

Atsushi Nakatsugawa
November 13, 2025
3 min read
November 13, 2025
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GPT-5.1 for code-related tasks: Higher signal at lower volumeの意訳です。
TL;DR
プロンプト調整とスタックへの統合を行った結果、GPT-5.1 はレビューにおいて、これまでで最も高い精度とS/N比(シグナル対ノイズ比)を、より少ないコメント量で実現するようになりました。複雑なベンチマークセット上で、最高クラスのエラーパターン(EP)リコールに並びつつ、競合モデルの半分以下のコメント量を記録しました。
その結果として、少ないノイズでより良い修正が得られ、レビューは再びパッチのように読めるものになったと感じています。

OpenAI と報道によると、 GPT-5.1はより安定し、指示に従い、適応性の高いモデルとして説明されています。GPT-5.1 は ChatGPT の「Instant」と「Thinking」モードの両方で駆動しています。コードレビューに関してこの説明を検証したところ、驚くほど正確だと感じられました。細かな指摘では素早く表面的に対応し、深い推論が必要なバグではしっかりと理由付けを行います。
今回は新しい試みも行いました。GPT-5.1 が誤った場合、そのやり取り全体と内部推論のトレースを用いて、振り返りを促すプロンプトを実行しました。どこを誤ったのかを示し、改善のためにどのように指示を変えるべきかを尋ねることで、モデル自身がプロンプトに対する具体的な修正案を提示します。この反復的な振り返り手法(差分外への過剰な広がりといった問題も浮上しましたが)によって、モデルの挙動とシステム指示の両方を調整し、安定してタイトな出力を得られるようにしました。

私たちは、GPT-5、Codex、Sonnet 4.5 の記事で使用したものと同じベンチマーク環境を使用しました。これは既知の エラーパターン(EP) を埋め込んだ 25 件の難しい PR から構成されています。スコアリングでは以下に重点を置いています。
アクショナブルなコメントのみ: 実際に投稿されるコメントのみ(追加提案や 差分外への記述を除く)
エラーパターンごとの合格数(コメントごと。以下EP Pass): コメントが エラーパターン を直接修正、または明示していること
Important コメント: EP PASS または重大/クリティカルな実バグ
Precision(精度): EP PASS ÷ コメント総数
SNR: Important ÷ (総数 − Important)
比較対象は以下の通りです。
GPT-5.1(新モデル)
CodeRabbit Production(現行レビューアースタック)
Sonnet 4.5
CodeRabbit ではモデルの導入は毎回適切に行われており、モデルを差し替えて祈るようなことはしません。各社のモデルはすでに互換品ではなくなっているため、デプロイ前にテスト、調整、品質ゲートを行います。GPT-5.1 に対しては以下のような調整を行いました。
GitHub に投稿できない 差分外のコメント の削減
冗長さを抑えるための トーンと簡潔さ の調整
重大度タグ と 指示解釈 の再整合
これは GPT-5 Codex の場合と同じで、推論能力をプロダクト価値へと変換するために、モデルの挙動を再構築するという目的があります。最終的な結果として、高いS/N比、ストレスの軽減、バグのカバレッジを損なわないレビューを実現しました。
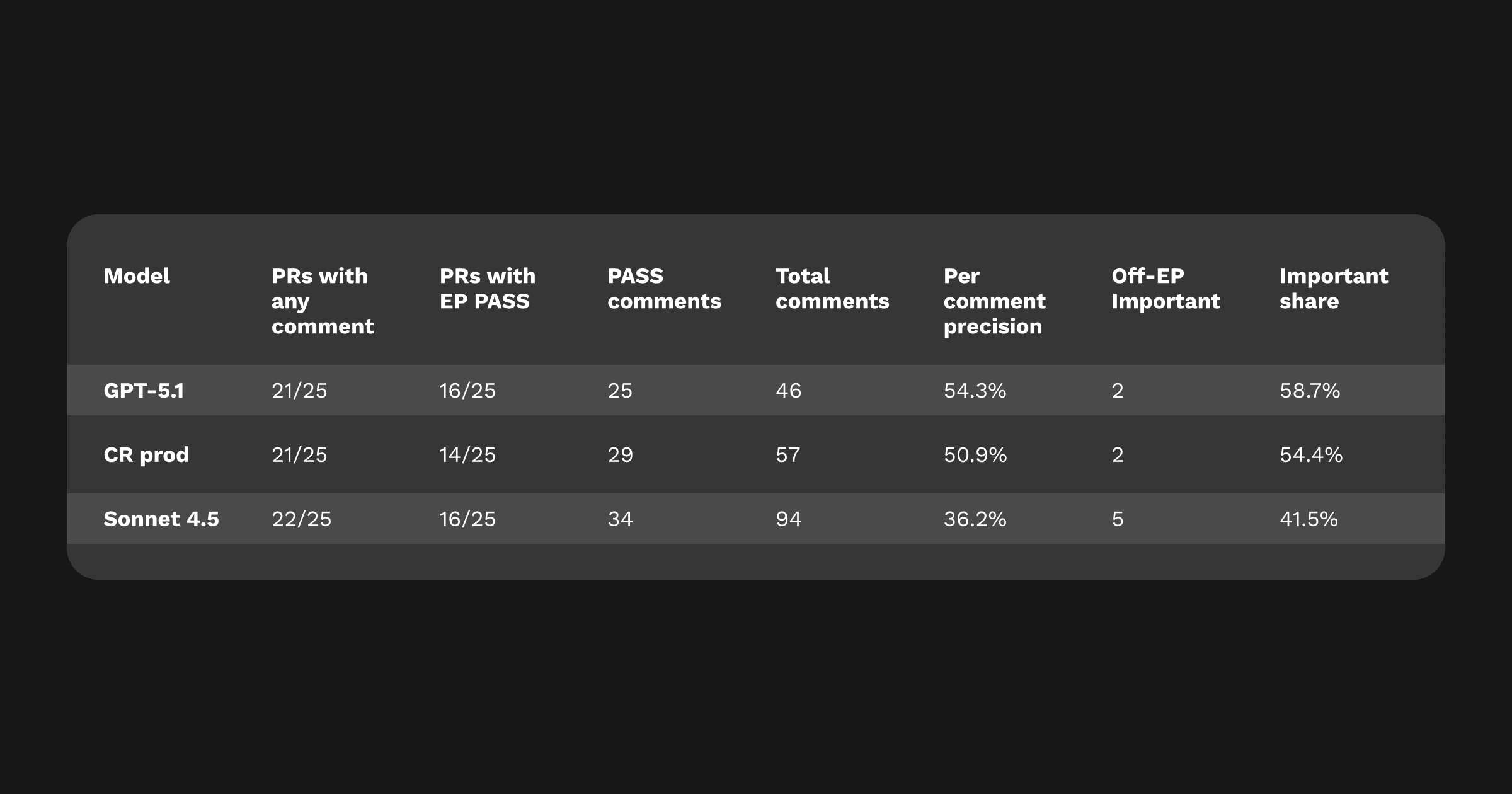
要点: GPT-5.1 は過去最高のエラーパターン再現率に並びつつ、最も少ないコメント量 を記録しました。CodeRabbit Production と Sonnet 4.5 の両方を コメント単位の精度 と Important コメント比率 で上回り、最もクリーンで高インパクトなレビュー を実現しました。

データで確認される挙動特性は、後に測定した言語メトリクス(弱め表現 28%、断定的マーカー 15% など)と一致しています。これにより、開発者が「レビュー自信があり、かつバランスの取れたトーン」だと感じる理由がデータでも裏付けられています。
GPT-5 Codex と Sonnet 4.5 と比較すると、GPT-5.1 のコメントはよりスリムで、対話的であり、熟練エンジニアのコミュニケーションに近いと感じられます。Codex は機械的かつ堅く、Sonnet 4.5 は冗長で学術的になりがちでした。それに対して GPT-5.1 は簡潔さと明確さのバランスが良く、押しつけがましくない自信を感じさせます。信頼できるチームメイトが差分を説明しているように読めます。CodeRabbit Production と比較すると、より課題に対して鋭くフォーカスされており、Sonnet 4.5 と比較するとより人間的で抑制が効いています。以下はその具体例です。
GPT-5.1 はより少なく鋭いコメントを書き、すぐに要点へ到達します。ある PR では、ロストウェイクアップバグを以下の 1 行で修正しました。p_caller_pool_thread->cond_var.wait(lock);
余計な文脈説明も不要な文章もありませんでした。比較すると CodeRabbit Production は同じ結論に至るまでに、スレッドフローを数段落説明していました。
所有権やメモリ管理が関わる場面ではためらいません。冗長な r->reference() 呼び出しについて、以下のように指摘しました。
「Ref<Resource> は refcount を自動管理します。手動で refcount を増やすとリークにつながるため削除してください」
開発者はこの率直さを好みます。講義ではなくパッチレビューのように読めます。
GPT-5.1 は、問題の重要度がどこにあるかを理解し、重要なものとそうでないものを適切に識別します。あるキャッシュ設定の PR では未実装の optimizeMemoryUsage() を指摘しましたが、次のように正しく文脈化しました。
「キャッシュの肥大化がメモリプレッシャーに影響しない限り、これは軽微です」
過剰反応せず、重要度を適切に扱っています。この点は Sonnet 4.5 にまだ課題があります。
プロンプトが曖昧だった場合、GPT-5.1 は自身の仮定を明示的に説明します。初期の実行では次のように述べました。
「プロンプトでヘルパー関数のスコープが指定されていませんが、明確化のために含めました」
この透明性が私たちの指示改善を助け、モデルの推論を信頼できるものにしました。
簡潔、率直、実務的、文脈理解という特性は GPT-5 Codex において私たちが高く評価した点と一致していますが、GPT-5.1 はより安定したトーンと抑制を備えています。
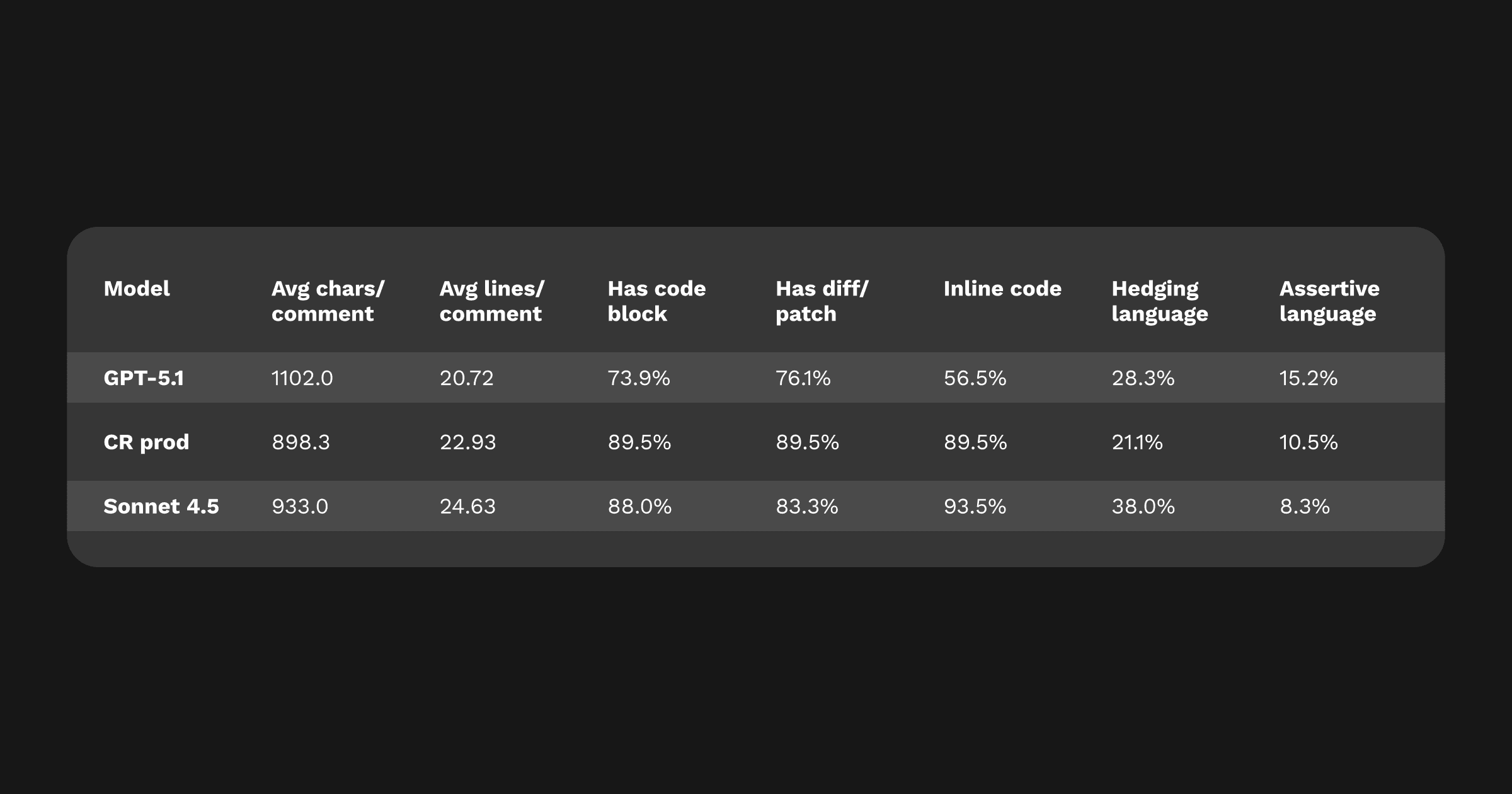
GPT-5 Codex や Sonnet 4.5 の評価で使用したものと同じ言語構造のシグナルを参照し、GPT-5.1 がレビューで異なる印象を与える理由を分析しました。これにはコメントの長さ、コードブロックの有無、弱め表現と断定表現の割合などが含まれます。データは明確な傾向を示しています。
読み方について
GPT-5.1 のコメントは平均文字数がやや多いものの、より明確な構造と負荷の高い文で構成されているため、実際には「短く読みやすい」と感じられます。GPT-5.1 のトーンは CodeRabbit Production や Sonnet 4.5 よりも断定的で、全体として diff ブロックは少ない(76%)という特徴があります。これは意図されたもので、複数箇所修正や API バリデーション、設計の明確化であり、単一のパッチを示すと誤解を招く場合があったためです。ただし、差分を含まないコメントの約 3 分の 2 では、最小限のパッチを示せば明確さがさらに向上すると感じられました。

CodeRabbit Production と比較すると、GPT-5.1 はパッチ頻度を一部犠牲にする代わりに、明確さと集中度を高めています。Sonnet 4.5 と比較すると、レビューを膨張させる冗長な説明を避けています。トーンは Codex の外科的精度と Sonnet の慎重な冗長性の中間に位置し、自信がありつつも強圧的ではなく、慎重でありながら臆病ではありません。
総じて、GPT-5.1 のレビューは 素早く読み進められ、より直接的で、実際の修正を見つけるためのスキャン量が少なくて済む という特徴があります。これは意図して調整した挙動であり、データと体験の両方に表れています。
完璧なモデルは存在せず、GPT-5.1 にもトレードオフがあります。CodeRabbit Production と比較すると、大規模チームで有用な文脈的な衛生改善の指摘を省くことがあり、より機能的な問題に集中する傾向があります。Sonnet 4.5 と比較すると、デザインやスタイル上の改善点を見逃すことがあり、人間のレビューアが好むケースもあります。これらは精度と簡潔さを優先した意図的なトレードオフであり、今後のロールアウトで開発者の反応を注視していく予定です。
GPT-5.1 は調整を必要としましたが、その課題は以前のシステムと比べるとはるかに軽度でした。CodeRabbit Production は衛生的な指摘と重大な指摘を同一スレッドで混在させる傾向があり、Sonnet 4.5 は説明過多で、同じバグについて複数の軽微なノートを投稿しがちです。一方で GPT-5.1 の調整点は主に精度に関わるもので、トーンや冗長性よりも限定的でした。これは GPT-5.1 がプロダクション導入に対して、非常に近い段階にあることを示しています。
diff 外コメント
GPT-5.1 は diff 以外の部分に提案を含めることがありました。プロンプトで明確に制約を示したところ、モデルは自己修正しました。
曖昧さに対する過剰な助け
プロンプトが厳密でない場合、コンテキスト追加やヘルパー関数の追加を行うことがありました。制約を明確にすると、境界を正確に守るようになりました。
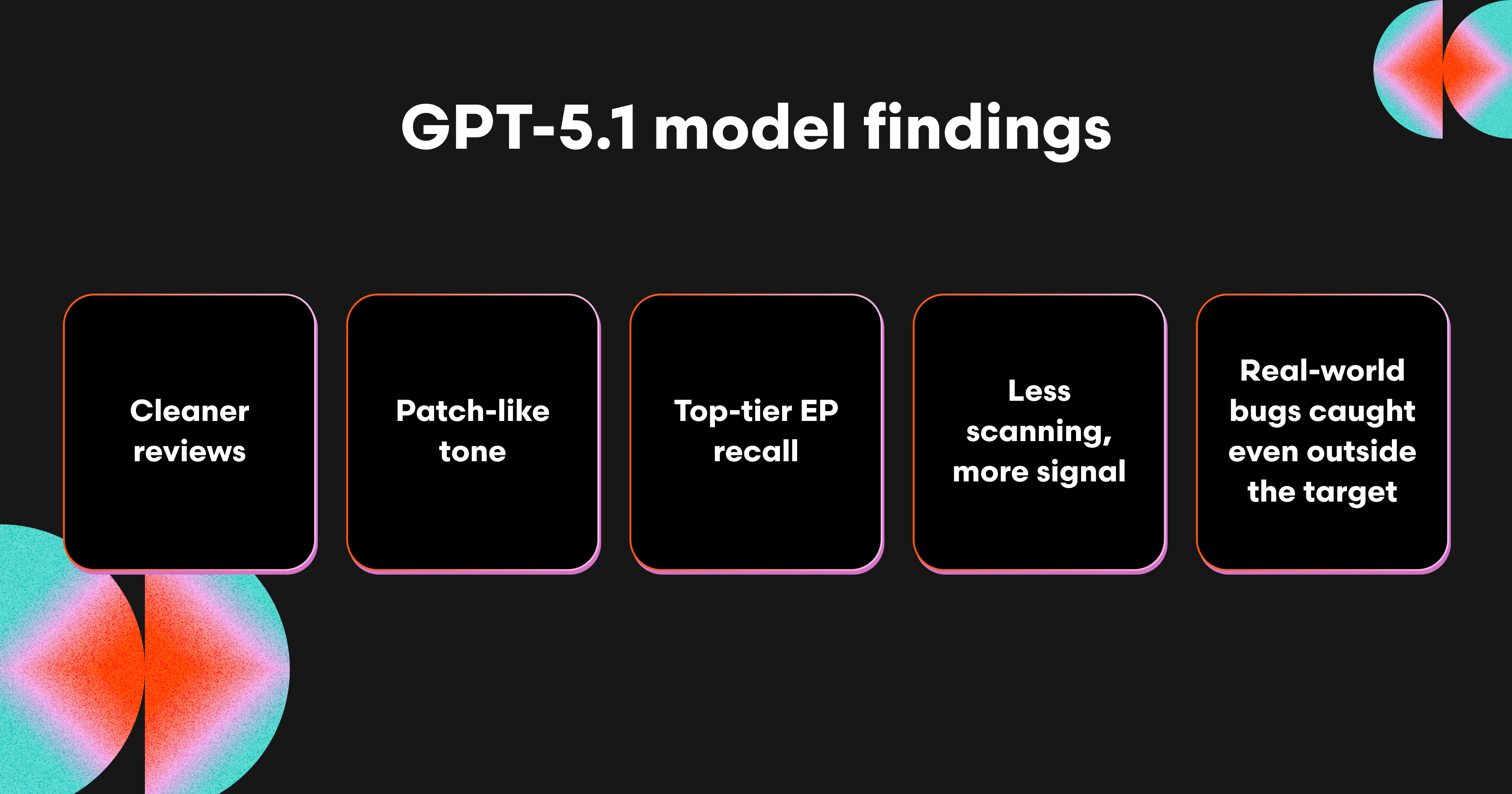
よりクリーンなレビュー
コメント数が減り、重要コメントの割合が高まります。
パッチのようなトーン
ほぼすべてのコメントが最小限の修正案と説明を含みます。
トップクラスの EP リコール
Sonnet 4.5 と同等で、CodeRabbit Production を上回ります。
少ないスキャンで高いシグナル
コメントの 58.7% が Important に分類されます。
ターゲット外でも実世界のバグを捕捉
ライフサイクルの問題、リーク、整合性ギャップなどを検出します。
私たちはモデルをただ選ぶのではなく、正しく機能する形へ調整します。GPT-5.1 は現在、GitHub 差分の振る舞い、トーン、冗長度、スコアリング閾値の調整を完了し、ロールアウト前のフェーズに入っています。今後数週間にわたり、開発者が高いS/N比、新しいトーン、簡潔なレビューをどのように受け止めるかを監視します。フィードバックが良好であれば、提供範囲を拡大し、開発者が求めてきた「よりクリーンでより速いレビュー」を提供していきます。
現時点で GPT-5.1 は、私たちに新しい価値、つまり次世代レベルの精度を重視したレビュー示してくれる準備が整っています。これは CodeRabbit の理想である、「重要なバグを素早く見つけ、開発者にノイズを強いることなく届ける」という目標にさらに近づくものです。
コードレビューを試してみたい方はこちらです
14 日間の無料トライアルをお試しください



