CodeRabbit is now in the Claude Marketplace!Read the Claude Marketplace announcement

Juan Pablo Flores
April 16, 2026
17 min read
April 16, 2026
17 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
You know the bug that ships on a Friday because the reviewer was rushing through a 40-file PR? The race condition buried three files deep that nobody traces until it pages someone at 2 AM? That's the gap AI code review was built to close. With Claude Opus 4.7, the gap just got a lot narrower.
CodeRabbit's review engine doesn't rely on a single model. We run an ensemble of frontier models from multiple labs, selecting different models for different aspects of the review pipeline. Each model earns its slot through evaluation on real code. When a new frontier model ships, we benchmark it against every model in our current ensemble to see where it outperforms and where it doesn't.
We've been testing it at CodeRabbit against our production code-review pipeline. The results aren't marginal improvements. We ran Opus 4.7 head-to-head across 100 evaluation points spanning a multitude of real-world open-source pull requests. Claude Opus 4.7 finds more real bugs, produces more actionable feedback, and reasons across files better than anything we've tested before.
Before diving into the results, it's worth understanding how we benchmark code-review models. Methodology matters as much as outcomes.
Our evaluation framework is built around what we call Error Patterns (EPs): a curated set of 100 known issues drawn from actual pull requests across major open-source projects. Each EP maps to a specific, verified issue in a real PR: a race condition in a Go service, a missing null check in a React component, an authorization bypass in a Rails controller.
For every model we test, we measure four core dimensions:
We scored Opus 4.7 against our current production baseline on the exact same rubric, across the same 100 EPs, on the same PRs. No cherry-picking, no special prompting for one model over the other.
Integrating Opus 4.7 in CodeRabbit delivers a jump in review quality across various metrics that we track.
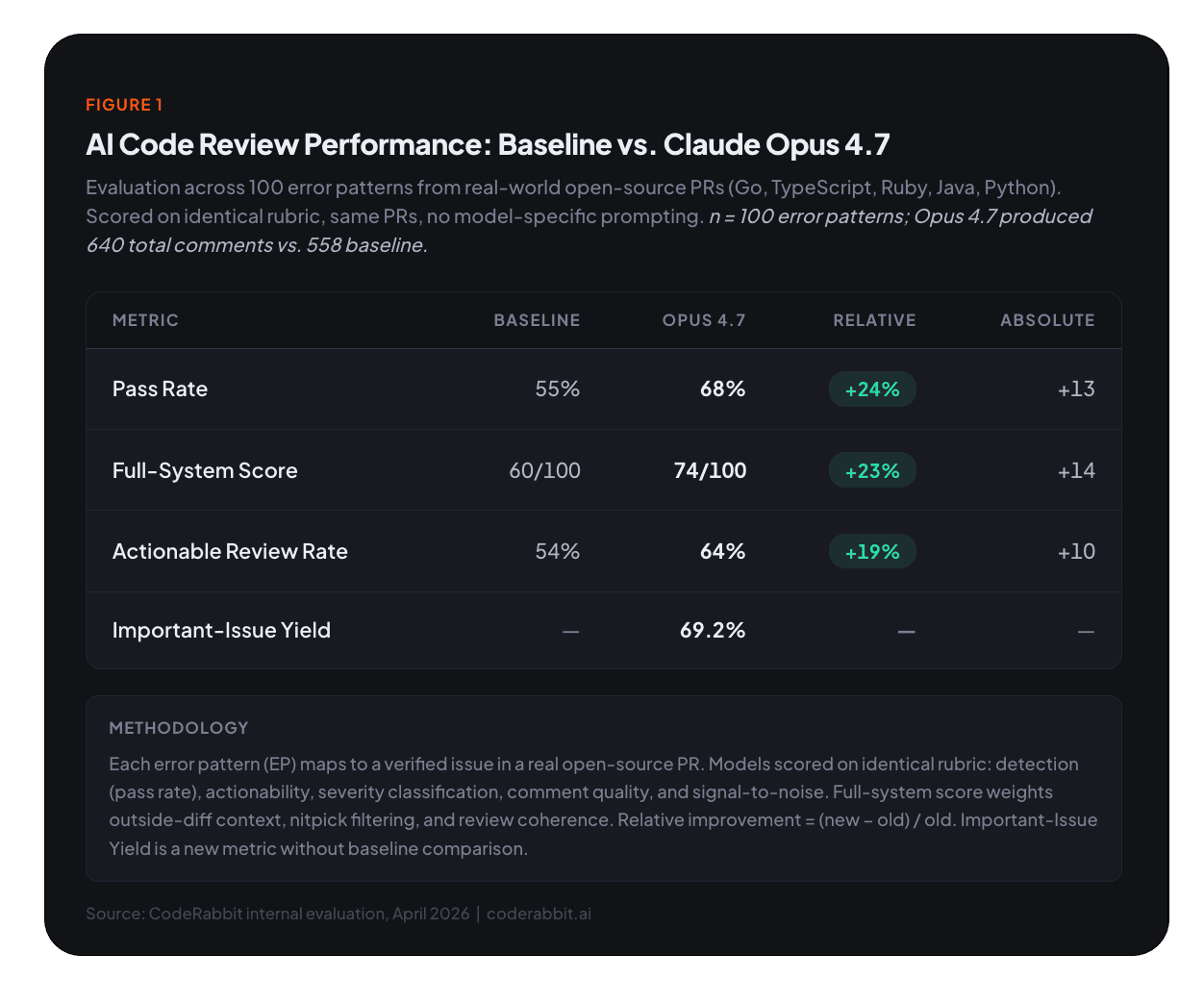
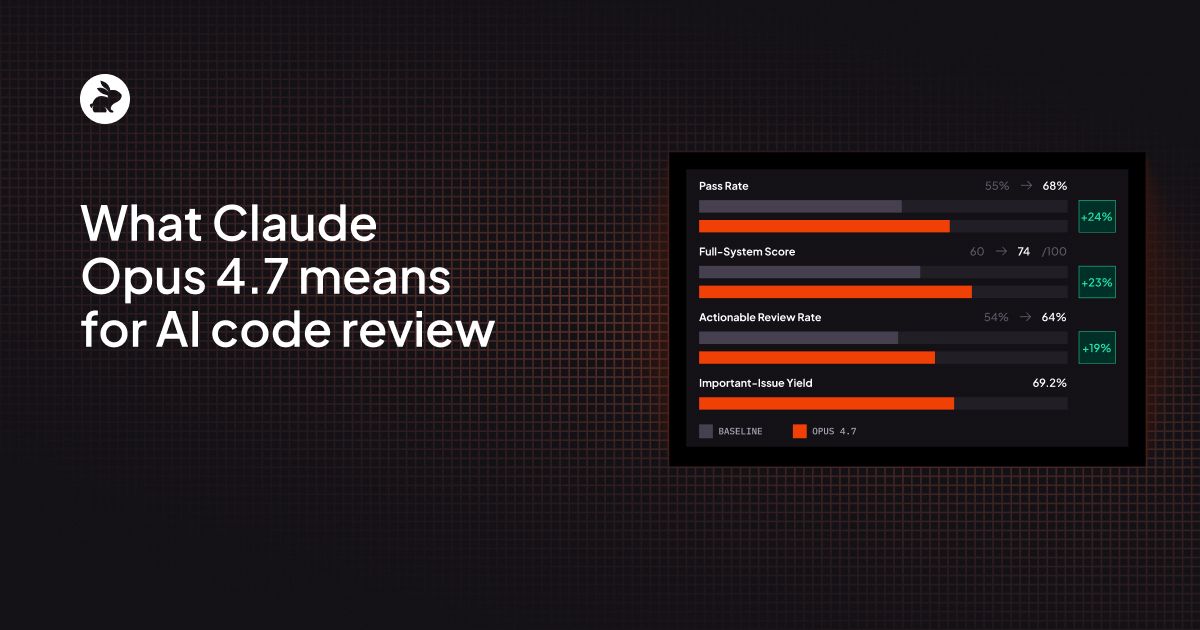
On our core evaluation, whether the model catches the known issue in a given PR, integrating Opus 4.7 to CodeRabbit’s current code review harness passed on 68 out of 100 evaluation points, up from 55 on the baseline. That's a 24% relative improvement in the model's ability to find the specific bug that matters.
To put this in practical terms: imagine a team that merges 20 PRs a week, each containing at least one reviewable issue. With the baseline model, roughly 11 of those issues get caught. With Opus 4.7, that number jumps to nearly 14. Over a quarter, that's roughly 36 additional bugs caught before they reach production.
When we layer in our full scoring system (which accounts for outside-diff context, nitpick filtering, and overall review coherence), the gap widens further. Integrating Opus 4.7 scored 74/100 compared to the baseline's 60/100, a 23% relative improvement.
This metric captures something subtler than raw bug detection. A model might catch a bug but do so in a way that's confusing, references the wrong line, or buries the finding in unrelated noise. The full-system score penalizes those failure modes and rewards reviews that are coherent, well-targeted, and properly contextualized within the broader PR. The fact that Opus 4.7's full-system score improved more than its raw pass rate tells us the presentation quality improved alongside detection. The reviews are more coherent, better targeted, and properly contextualized.
Every single one of the 640 comments was marked actionable by our evaluator, meaning each one contained enough information for a developer to act on. But when we measure against EP-specific actionability (whether the actionable comment actually addresses the target issue rather than a tangential concern), it jumped from 54% to 64%.
This is the difference between a reviewer who says "there's a problem somewhere in this file" and one who says "line 47 will panic when the user is nil because the guard clause on line 42 doesn't cover the admin role path. Here's a diff that fixes it." Both are technically actionable. Only the second one saves you time.
This is one of the most striking data points in our evaluation. Nearly 70% of all comments Opus 4.7 generated were classified as important, meaning they flagged substantive bugs, security risks, or correctness problems rather than style nits or cosmetic suggestions.
Of those 443 important comments, 367 were findings the model surfaced beyond the target evaluation point. That's 82.8% of all important output coming from issues the model discovered on its own, unprompted, while reviewing the same code. In other words, Opus 4.7 behaves less like a targeted test and more like a thorough reviewer who notices problems in the periphery while looking at the code you pointed it to.
For context, the baseline model generated 558 total comments. Integrating Opus 4.7 generated 640, about 15% more volume. But the important-issue density is what sets it apart. More comments don't matter if they're noise. More important comments are a different story entirely.
The scores above establish that Opus 4.7 is better. What follows explains why, and what it actually looks like when this model reviews your code. We spent significant time reading through individual comments, and several patterns emerged consistently across languages and codebases.

Across our evaluation set, the model consistently identified concrete races, nil/panic paths, authorization failures, blacklist bypasses, XSS and SSRF chains, response-shape mismatches, and lifecycle/data-loss bugs.
In Go codebases, the model traced concurrent access patterns across goroutines to identify real race conditions: not just "this looks like it might have a race" but "goroutine A writes to cache.entries on line 137 while goroutine B reads it on line 140 with no synchronization, which will panic under concurrent load." It named the specific data structure, the specific lines, and the specific failure mode.
In TypeScript/React code, it followed event handler lifecycles to spot state-management bugs. It tracked how a useEffect cleanup function interacted with an async fetch, identified the exact window where a stale closure could cause a state update on an unmounted component, and proposed a cancellation-token pattern as the fix.
In Ruby on Rails controllers, it identified authentication bypass vectors that arise from parameter handling edge cases, the kind of subtle permissiveness that a human reviewer might miss on a Friday afternoon but an attacker won't miss on a Saturday.
In Java (Keycloak specifically), it caught contract mismatches between service interfaces and their implementations, tracing through multiple layers of abstraction to identify where a runtime exception would surface.
In Python (Sentry), it identified silent failure paths where exceptions were caught too broadly, causing data-processing pipelines to swallow errors and produce incomplete results without any visible alert.
One of the most impressive capabilities, and the one that benefits most from the expanded context window, is the model's ability to connect findings across files. Given a diff, it traces helper-level contracts to downstream breakage and compares behavior across related methods, handlers, or providers.
Opus 4.7 can tell you that the parameter was used by two downstream callers that the PR author forgot to update and that one of those callers will now silently fall back to a default value that breaks the billing calculation for enterprise accounts.
Our analysis confirmed this pattern: the model "often connects helper-level contracts to downstream breakage and compares behavior across related methods, handlers, or providers." We observed this consistently across dozens of review sessions spanning five different language ecosystems.
The review style is extremely code-centric, and this is where the practical developer experience shines:
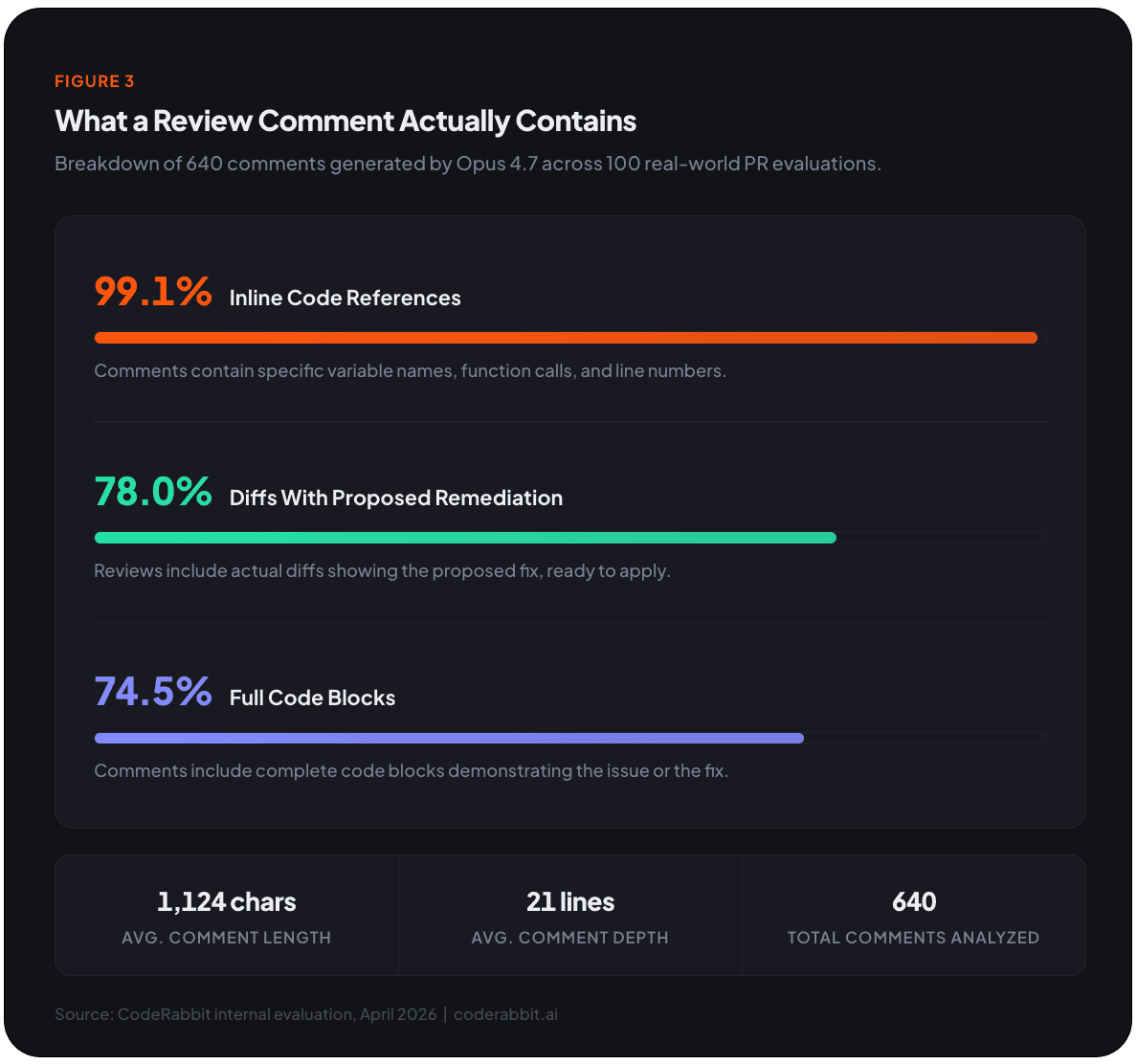
In practice, most comments arrive with a ready-to-apply fix. The average comment runs 1,124 characters across 21 lines, reading like a mini design review rather than a drive-by annotation. A typical comment opens with a bold, verdict-style summary ("Race condition in cache invalidation"), follows with a concise mechanism/impact explanation (2-3 paragraphs tracing the specific code path), and closes with a concrete diff wrapped in a collapsible <details> block.
If you've used earlier Claude models for code review, the tone of Opus 4.7 will feel noticeably different. Anthropic describes it as "more direct and opinionated, with less validation-forward phrasing." Our evaluation quantifies this shift.
Opus 4.7's review comments have an assertiveness rate of 77.6% and a hedging rate of just 16.5%. It leads with a bold, verdict-style summary of the issue, follows with a concise mechanism/impact explanation, and then presents a concrete patch. The language uses clear imperatives: "Guard against nil," "Prevent concurrent access," "Validate input before processing" rather than tentative suggestions.
Our tone analysis summarized it well: "Comments read like detailed mini code reviews. They open with a bold, verdict-style summary of the issue, follow with 1–3 explanatory paragraphs, and then present a concrete patch in diff form. The tone is confident and directive, using clear imperatives rather than tentative phrasing."
For maintainers, this is a welcome shift. When a model tells you "this will panic on nil input" instead of "you might want to consider checking for nil," you save cognitive overhead and can act on the feedback faster. In a busy review queue, that directness multiplies across dozens of comments per day.
The hedging that does remain is well-placed. It appears primarily around subjective or domain-specific decisions, for instance, flagging a localization string as potentially incorrect and suggesting "please have a native speaker confirm." That's appropriate humility. The model is confident where it has evidence and careful where it doesn't.
Want to see this in action? Try CodeRabbit on your next PR - free to start, no credit card required. See Opus 4.7-powered reviews on your own code.
Benchmarks tell you how a model performs on a rubric. They don't tell you what it feels like to sit down with it and build something. Our engineering team has been hands-on with Opus 4.7 for coding tasks beyond code review, and a few patterns emerged.
The first thing you notice is how communicative the model is. As it works, the model narrates: what it's doing, why, which variables it's modifying, which files it's touching, and what its reasoning is at each step. The tone isn't conversational,it’s tactical. Every token carries information, optimized for context transfer rather than warmth.
If you're new to working with AI coding assistants, this is great. You get a running commentary that doubles as a learning tool. But if you're an experienced developer who's used to terse, get-it-done interactions, it can feel over-communicative. There's a calibration period where you learn to skim the explanations and focus on the code output. The same depth we measured in the review benchmarks carries over.
Opus 4.7 has a strong sense of task complexity. When you give it something simple (rename a variable, add a guard clause, write a utility function), it moves fast. When you give it something genuinely hard (refactor a state machine, redesign an authentication flow, untangle a circular dependency), it takes more time to reason, and you can feel the difference. Even on complex tasks, the overall velocity is noticeably faster than previous models. The model seems to understand how much thinking a task deserves and allocates accordingly, so it doesn't waste your time over-reasoning on trivial work.
In practice, this means you can move through a task backlog at speeds we haven't seen before. Simple changes fly by. Complex changes take longer but arrive with fewer bugs and better structure.
Across our first batch of hands-on sessions, the code quality was consistently strong. We encountered very few bugs during initial exploration, the kind of "it runs but doesn't work" failures that typically plague first-pass AI-generated code were notably rare. The model seems to get the logic right on the first try more often than not.
There's a nuance here for frontend work. Opus 4.7 is excellent at the logic of UX: the placement of elements, the flow between states, the interactive behavior of components. But it doesn't have a great design taste. The UI it generates is functional and well-structured, but it won't win any design awards. If you're building a prototype or an internal tool, that's fine. If you're building a consumer-facing product, expect to bring your own design system and use the model for the logic layer.
One thing that surprised us: Opus 4.7 is remarkably good at interpreting imprecise prompts. You don't need to write perfectly structured instructions. You can be vague, incomplete, or even somewhat contradictory in your prompt, and the model will generally infer what you actually meant and produce something useful. In real-world usage, developers are thinking faster than they're typing. They don't want to spend time crafting the perfect prompt, and with Opus 4.7, they don't have to.
This tracks with what our benchmarks show in the code-review context. The model appears to reason about broader intent and context rather than treating each instruction as an isolated directive.
One of the more interesting behaviors we observed is that Opus 4.7 will often go back and review its own work after completing a task. It'll generate the code, then scan it for issues, then attempt to fix what it found, all without being asked. This self-correction loop can be genuinely valuable. It catches things the model missed on the first pass and improves the final output.
But there's a downside. Sometimes the model overthinks it. It'll identify a "problem" in otherwise clean code and start reworking sections that didn't need to be touched, introducing unnecessary changes or even new issues in the process. The model's thoroughness occasionally tips over into over-correction. For developers, the practical advice is to review the model's self-edits with the same scrutiny you'd apply to any code change, and don't hesitate to roll back the second pass if the first one was already correct.
This was unexpected: Opus 4.7 is genuinely good at creative work. When we asked for titles, taglines, naming suggestions, and creative copy, the model produced results that felt original.
It also performed well on graphical tasks: generating images, logos, vector graphics, and pixel art with a level of quality and coherence that went beyond what we expected from a model primarily known for code and reasoning. For developers who wear multiple hats (and most of us do), that creative range means you can use the same model for both the code and the marketing page that explains it.
No model is perfect, and we'd rather be upfront about the rough edges than have you discover them yourself.
critical and major. While many of those labels are justified, the model also applies critical to speculative security surfaces, migration risks, and test-only failures that don't meet a strict rubric for that level. Identical comment text occasionally receives different severity labels across similar contexts, reflecting annotation instability we need to smooth out. We're tuning our post-processing pipeline to normalize these before they reach developers. 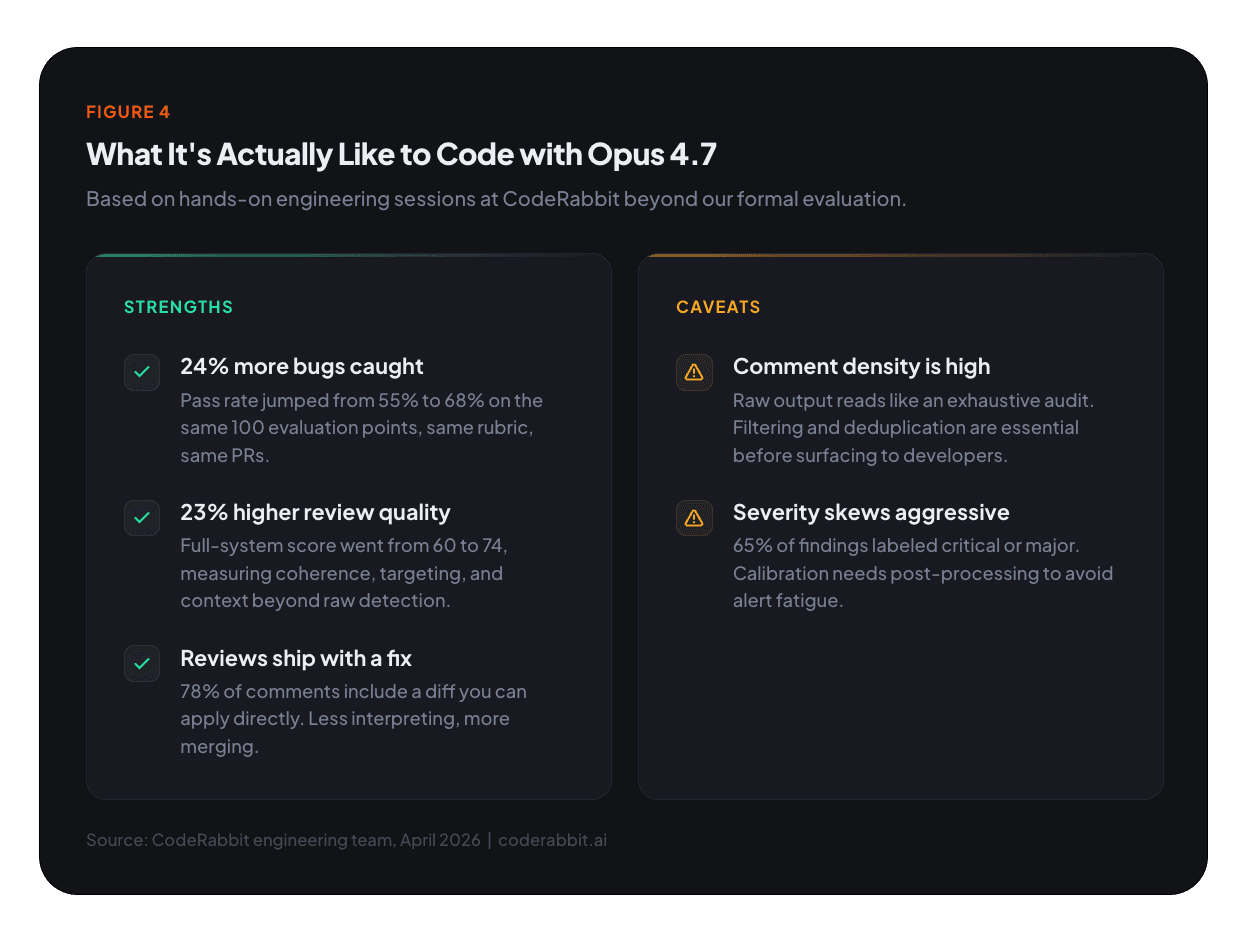
We're actively integrating Opus 4.7 into our review pipeline. Here's what you can expect as we roll it out:
Opus 4.7 represents a step function in what's possible with AI-assisted code review. Stronger reasoning, broader context, more actionable output, configurable depth. The gap between AI review and expert human review continues to narrow. The AI isn't replacing the human reviewer. It's covering the ground that humans don't have time for.
If you haven't tried CodeRabbit yet, there's never been a better time. Connect your repository in under two minutes. The model got a lot smarter, and so did your code reviews.
Get started with CodeRabbit - connect your repo, get your first AI review in minutes. Free to try, no credit card required.



