



Christopher Cassion
David Loker
Nehal Gajraj
August 07, 2025
11 min read
August 07, 2025
11 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI’s GPT-5 model to evaluate the LLM’s ability to understand, reason through, and find errors in complex codebases.
As part of our GPT-5 testing, we've conducted extensive evals to uncover its technical nuances, capabilities, and use cases with a focus on the model’s ability to understand and reason through potential issues and bugs in codebases.
Below, you’ll find a breakdown of our structured evaluation approach, detailed findings relative to other popular models, and how we’re planning to incorporate GPT-5 into your AI code reviews to make them even better.

GPT-5 outperformed Opus-4, Sonnet-4, and OpenAI’s O3 across a battery of 300 varying difficulty, error-diverse pull requests.
GPT-5 scored highest on our comprehensive test and found 254 out of 300 bugs or 85% where other models found between 200 and 207 – 16% to 22% less.
On our 25 hardest PRs from our evaluation dataset, GPT-5 achieved the highest ever overall pass rate (77.3%), representing a 190% improvement over Sonnet-4, 132% over Opus-4, and 76% over O3.
We ran the same tests we run on all our models. These evals integrate GPT-5 into our context-rich, non-linear code review pipeline to see how it would perform in a typical code review.
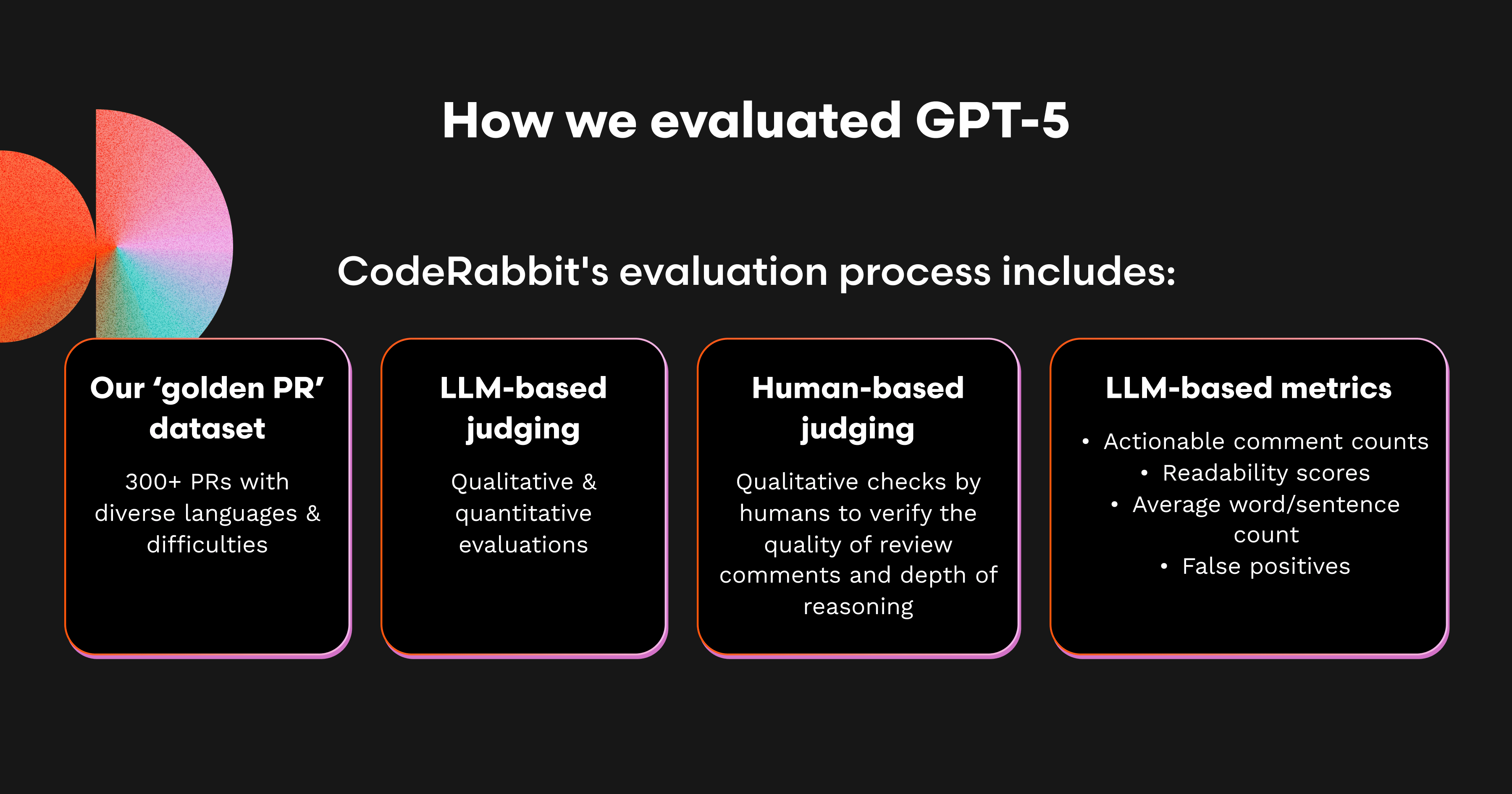
CodeRabbit's evaluation process includes:
LLM-based judging: We perform dual-layered LLM-based judgment that looks at both qualitative and quantitative data such as the quality of a review and a pass/fail of the model’s accuracy.
Human-based judging: We then perform qualitative checks by humans to verify the quality of review comments and depth of the model’s reasoning.
LLM-based metrics collection: We collect metrics that we believe are indicative of a high quality code review and weigh them by their importance. These metrics include:
Actionable comment counts
Readability scores (Flesch Reading Ease score)
Average word count
Sentence count
False positives (hallucinations)
Note: Our evaluations were conducted on various ‘snapshots’ of GPT-5 that OpenAI shared with us leading up to the release of GPT-5. While our results changed somewhat with different snapshots, their relative consistency allowed us to make the observations below. The released model might be slightly different.
Our evaluation of GPT-5’s capabilities found that the model certainly lives up to the hype. GPT-5 outperformed all other models we’ve tested on our datasets – by a lot.
GPT-5’s weighted score from our comprehensive evaluations was between 3465 and 3541 on different test runs – which is almost 200 points above OpenAI’s O3 model and Anthropic’s Sonnet 4, which were previously our highest scoring models. The maximum possible score is 3651.
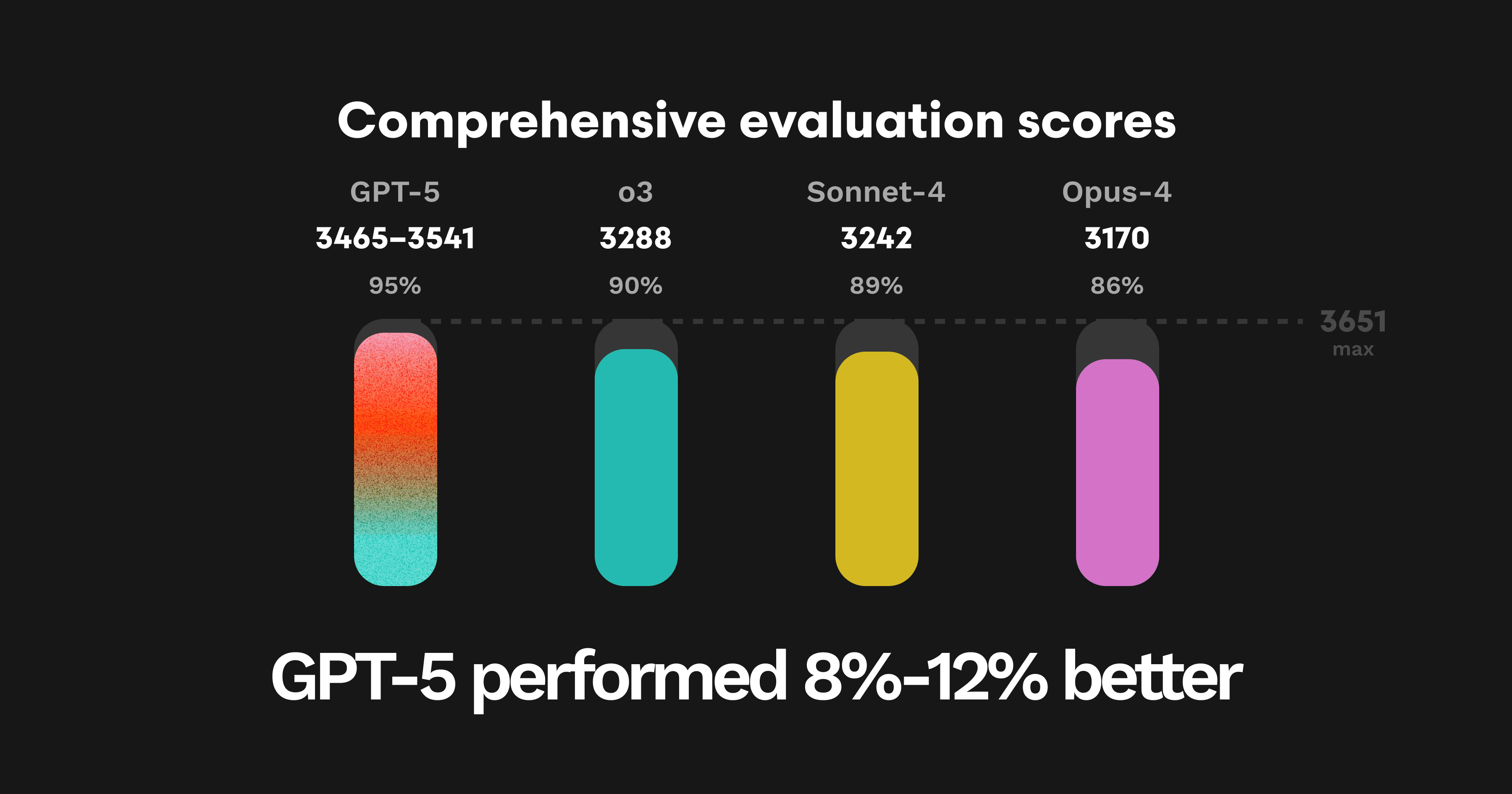
Full evaluation scores:
GPT-5: 3465–3541
O3: 3288
Sonnet-4: 3242
Opus-4: 3170
Takeaway:
While a 200 point or 5% increase might not seem significant, the way our tests work is that models initially rack up points finding low-hanging fruit like infinite loops and exposed secret keys. After a point, it then becomes progressively harder to get points since all the remaining points come from flagging much harder to find issues. GPT-5’s ability to get so many more points than other models, therefore, represents a significant leap forward in reasoning.
We also give models a pass/fail score based on how many of the 300 error patterns in our dataset PRs the model was able to find. GPT-5 also achieved the highest success rate on this scale that we’ve ever seen at 254 to 259 out of 300.
Compare that to the performance of other models:
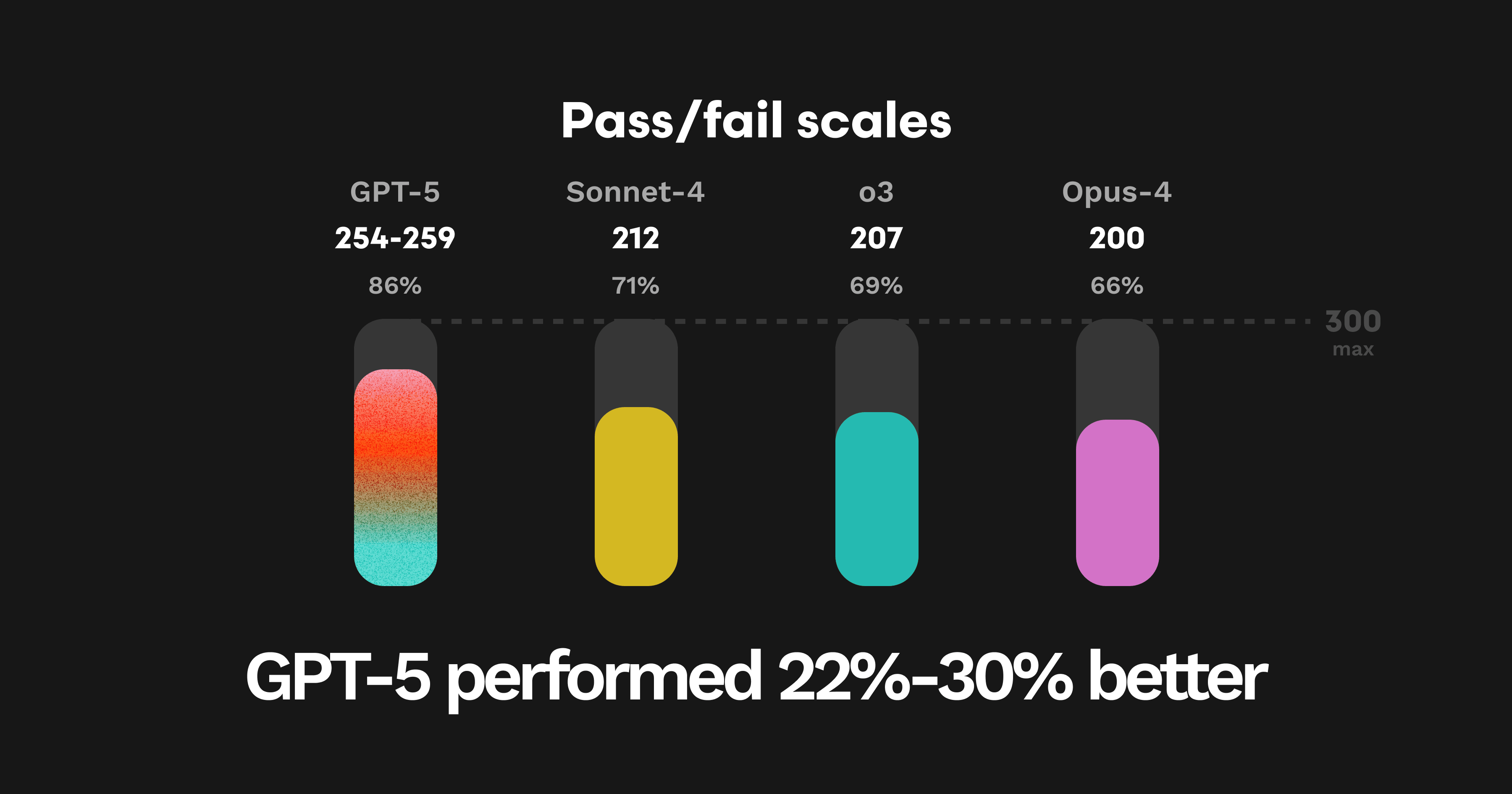
GPT-5: 254-259
Sonnet-4: 212
O3: 207
Opus-4: 200
Since about 100 of the bottom PRs are found by all models, if we just look at the most difficult 200 error patterns, the numbers show even greater improvement with GPT-5 catching 78% of those error patterns and other models catching only 54% to 58%.
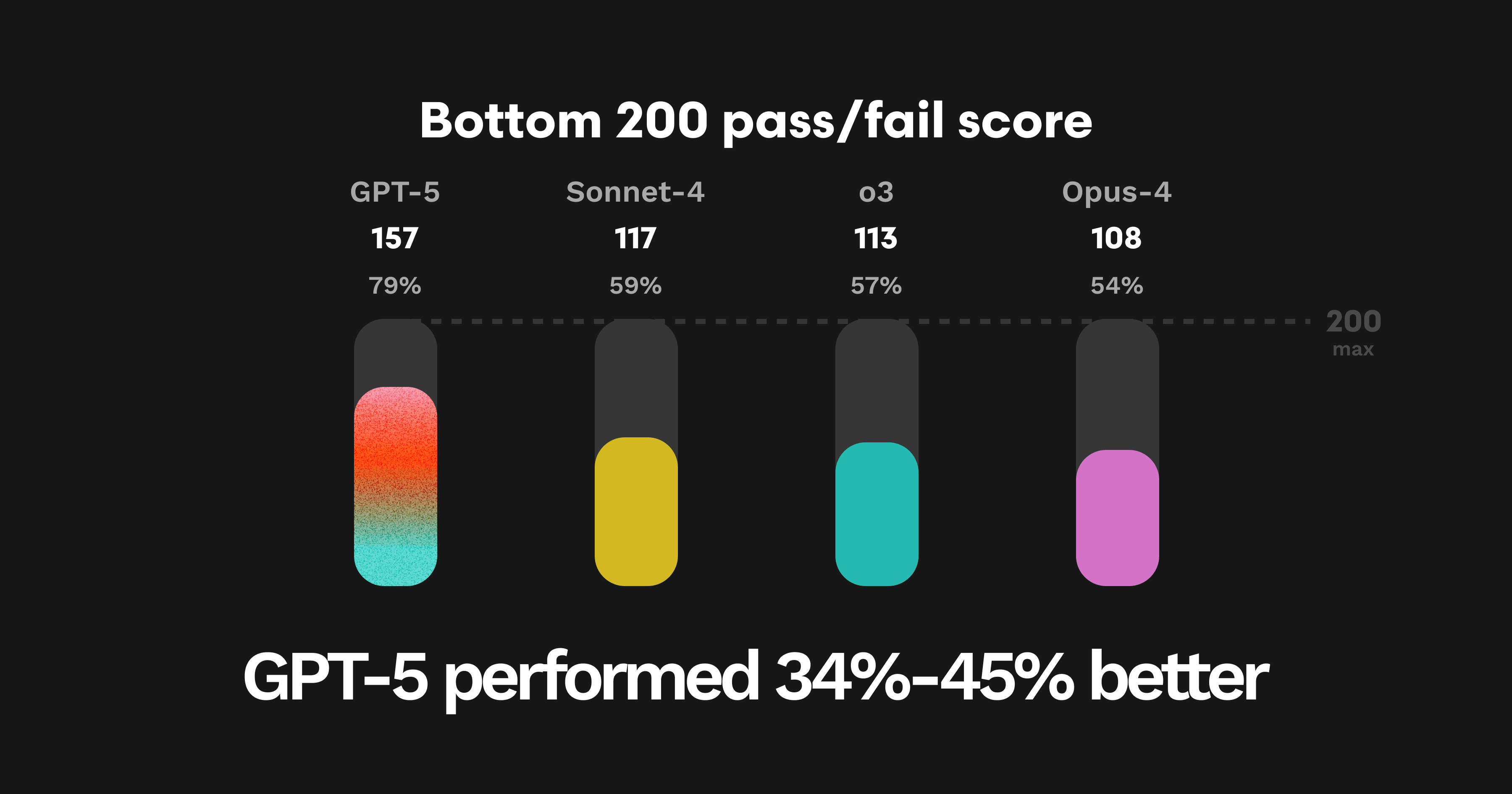
GPT-5: 157
Sonnet-4: 117
O3: 113
Opus-4: 108
Takeaway:
Similar to our comprehensive metric, the additional error patterns that GPT-5 was able to find are particularly hard for LLMs to spot, like concurrency bugs or inconsistent domain keys across environments, suggesting the model’s increased ability to reason.
To stress-test each model, we curated 25 of the most difficult pull requests from our Golden PR Dataset. These PRs represent real-world bugs that span:
Concurrency issues (e.g. TOCTOU races, incorrect synchronization)
Object-oriented design flaws (e.g. virtual call pitfalls, refcount memory model violations)
Performance hazards (e.g. runaway cache growth, tight loop stalls)
Language-specific footguns (e.g. TypeScript misuses, C++ memory order subtleties)
Each model was tested across three runs. Below is the average pass rate on this Hard 25 benchmark:
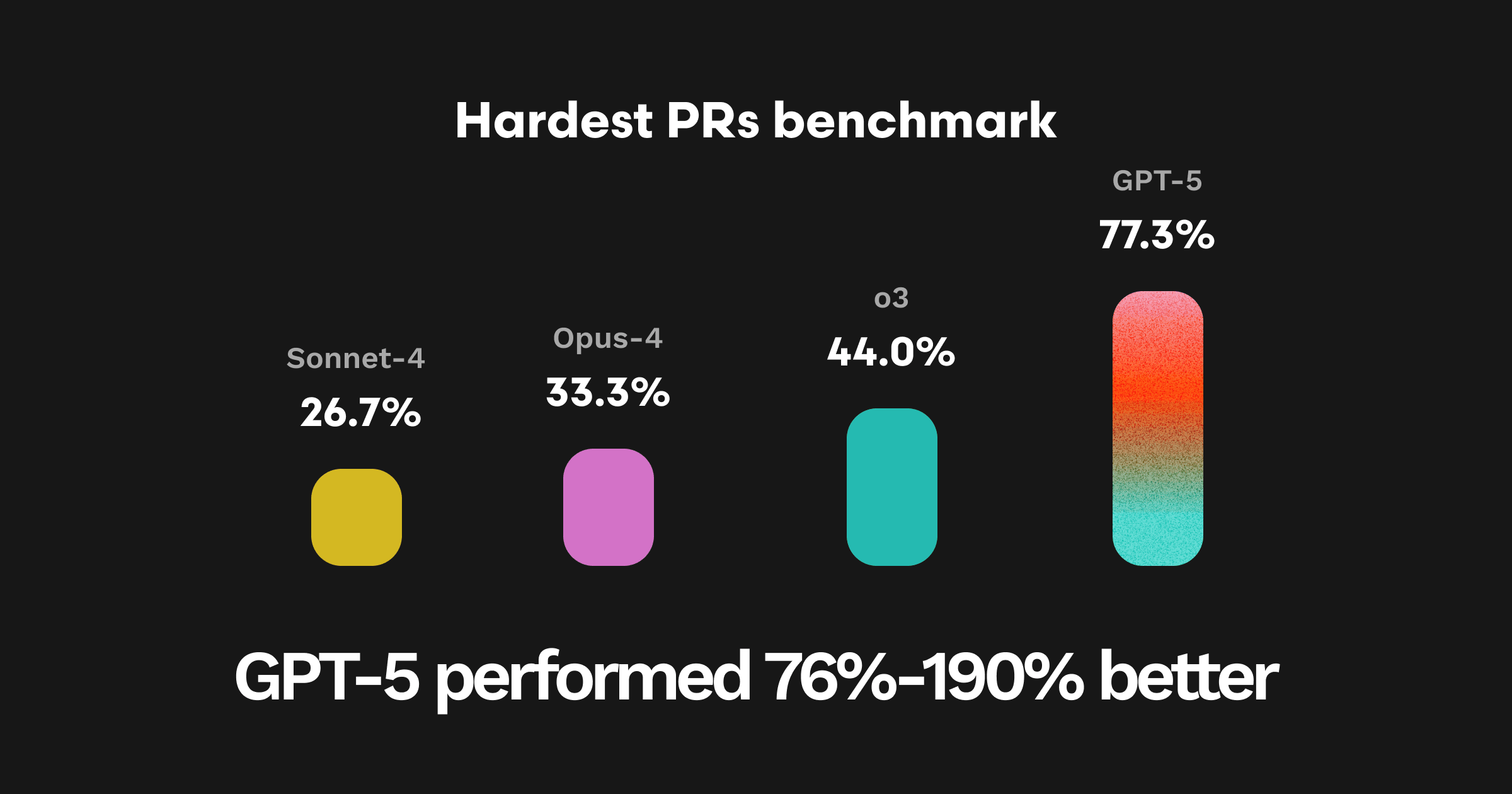
| Model | Mean Pass Rate (%) |
| Sonnet-4 | 26.7% |
| Opus-4 | 33.3% |
| O3 | 44.0% |
| GPT-5 | 77.3% |
Takeaway: GPT-5 shines where accuracy, contextual linkage, and depth matter most. It consistently delivers the most complete, test-ready, and forward-compatible code review output among all models we’ve tested to date.
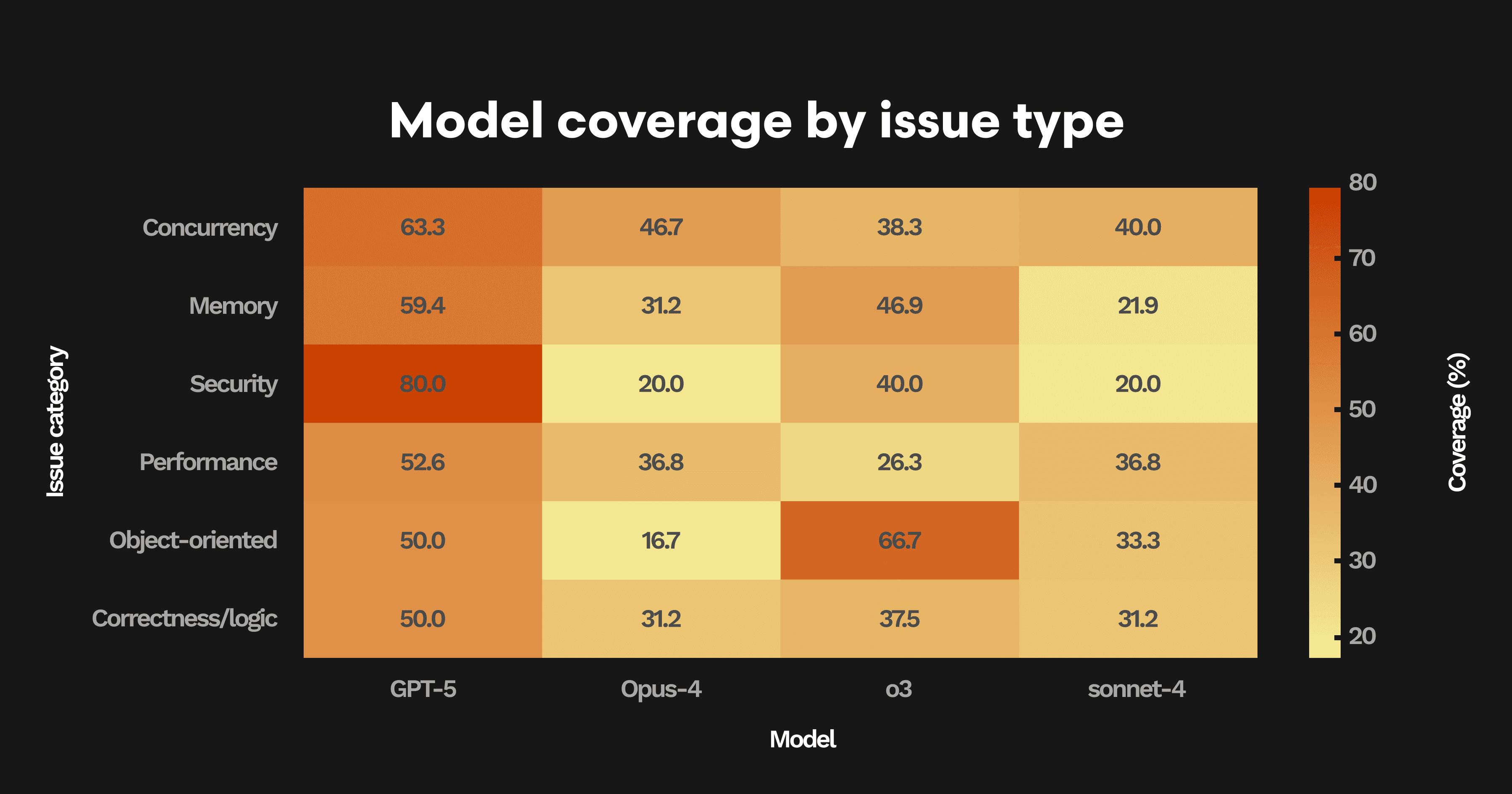
To better understand what kinds of issues each model identifies—not just how many—our team reviewed every comment across a set of hard PRs and classified them into categories like Concurrency, Security, and Object-Oriented Design.
We applied deduplication across models: if multiple models flagged the same core issue (even if phrased differently), it was counted only once per PR. This ensured we were measuring issue coverage, not comment verbosity.
Then, for each model, we tallied what percentage of those unique issues it successfully caught.
GPT-5 leads in almost every category, identifying over 60% of concurrency, performance, and memory bugs — and an impressive 80% of security issues.
Security remains the most striking gap: GPT-5 found 80% of security-related bugs, while the next best model (O3) found only 40%.
Even on basic concurrency and performance problems, GPT-5 consistently outperforms by 20-30 points.
In this pull request, a subtle concurrency bug stemmed from a combination of double-checked locking and unsafe access to a shared HashMap in a singleton service class. While most models flagged the obvious thread-safety issue, GPT-5 delivered a comprehensive, production-ready fix—resolving not just the symptom, but the architectural flaws underneath.
The OrderService singleton used a HashMap to store orders, while concurrent updates were made from a fixed thread pool. This design lacked synchronization, leading to potential data corruption. On top of that, the singleton was initialized using a non-volatile static field—opening the door to unsafe publication and partially constructed objects.
GPT-5 went beyond the basic fix and stitched together a complete concurrency hardening plan:
- private final Map<String, Order> orders = new HashMap<>();
+ private final Map<String, Order> orders = new ConcurrentHashMap<>();
✅ GPT-5 also explained why: “Concurrent updates... are executed on a plain HashMap... not thread-safe and can lead to undefined behavior.”
- private static OrderService instance;
+ private static volatile OrderService instance;
Or optionally:
private static class Holder {
private static final OrderService INSTANCE = new OrderService();
}
public static OrderService getInstance() {
return Holder.INSTANCE;
}
✅ It flagged the classic memory visibility issue with double-checked locking and offered an alternate pattern to make construction thread-safe.
// Inside OrderService.java
void clearAllForTest() {
orders.clear();
}
✅ This enables isolated, repeatable tests when working with a shared singleton across multiple test cases.
- future.get(); // Wait for completion
+ assertTimeoutPreemptively(Duration.ofSeconds(5), () -> future.get());
✅ GPT-5 proactively hardened the test suite by guarding against test flakiness in asynchronous flows.
Both models correctly flagged the unsynchronized HashMap and replaced it with ConcurrentHashMap. However, neither delivered a complete or production-safe remediation:
❌ Singleton issues unresolved:
Sonnet-4 ignored the broken double-checked locking; Opus-4 mentioned it but skipped the actual fix (no volatile, no holder idiom).
❌ No test safety provisions:
GPT-5 introduced clearAllForTest() and timeout guards; Sonnet-4 and Opus-4 missed these entirely or only noted them passively.
❌ Lacked architectural context:
Neither model cross-referenced the broader codebase or justified changes with evidence. GPT-5 backed each fix with reasoning that traced across services, tests, and threading behavior.
❌ Limited scope:
Sonnet-4 made a single, surface-level fix. Opus-4 added some useful logging but missed the deeper structural risks GPT-5 fully addressed.
The real value of GPT-5’s review lies in its depth and awareness. It not only patched the visible race, but also:
Identified deeper architectural risks
Cross-referenced test reliability and code quality
Delivered a set of changes that are safe to merge immediately
This isn’t just a fix—it’s engineering insight. GPT-5 showed how an AI reviewer can reason across system layers, suggest durable solutions, and help teams write safer code with less guesswork.

Beyond metrics and the specific things our tests were evaluating, we found that GPT-5 exhibited new behavioral and reasoning patterns.
Advanced contextual reasoning: GPT-5 proactively planned multiple review steps ahead, showcasing expansive creative reasoning rather than strict input-bound logic. For example, GPT-5 demonstrated deep reasoning by connecting evidence across filles in our Concurrency oriented test focused on a ‘Check-then-act race condition’ scenario. It was the only model to detect risk of duplicate creation and introduced an atomic refund pattern grounded in the enum and test suite.
Chain-of-thought reasoning via review threads: In an Object-Oriented test focused on a Virtual call in constructor case, GPT-5 showed layered logic by first identifying a misused polymorphic override and then adjusting its recommendations based on its own earlier suggestions. This shows layered logic by identifying one thing and then showing additional reasoning on the issue later.
Evidence-based diff justification: In a Performance-focused test focused on Unbounded cache growth (no eviction) issue, GPT-5 identified architectural memory risks that other models missed, and backed its recommendation with diff context, usage patterns, and suggested safeguards.
Forward-thinking suggestions: In a Concurrency-related test focused on Incorrect sync primitive usage, GPT-5 not only patched the race but also suggested how to structure future additions, lock hierarchies, and test guardrails to prevent regressions.
Granular, task-oriented recommendations: Unlike previous models, GPT-5 detailed explicit follow-up tasks, creating actionable workflows within the review process itself. This makes the model much better for multi-step workflows.
We’re excited that GPT-5 represents a significant advancement in AI-powered code review, pushing the boundaries in detail, accuracy, and contextual reasoning. That’s why we’ll be using GPT-5 as the core reasoning model in our pipeline – starting today. We’re excited that it will be able to find more issues and create more in-depth, context-rich reviews.
If you’ve never tried CodeRabbit, tried it previously, or are a current user, we’d love to hear how you think GPT-5 is improving your review quality and experience.
Try our free 14-day trial today to see the power of GPT-5 yourself.



