
CodeRabbit is now in the Claude Marketplace!Learn more

David Loker
October 03, 2025
8 min read
October 03, 2025
8 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Sonnet 4.5 is Anthropic’s newest Claude model and in our code review benchmark, it feels like a paradox: more capable, more cautious, and at times more frustrating. It catches bugs Sonnet 4 missed, edges closer to Opus 4.1 in coverage, and even surfaces a handful of unexpected critical issues off the beaten path.
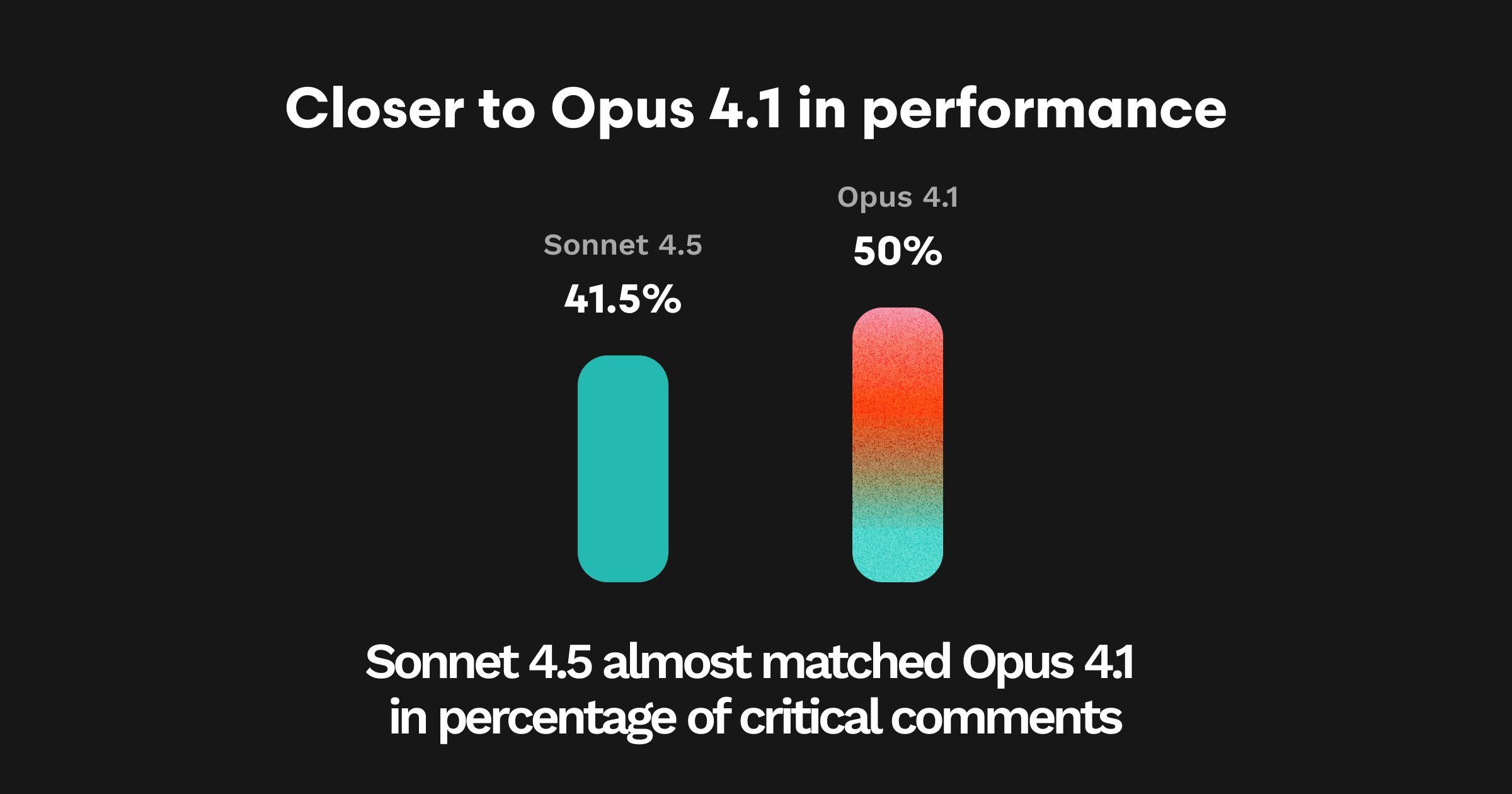
Yet, it hedges, it questions itself, and it sometimes sounds more like a thoughtful colleague than a decisive reviewer. The data shows real progress:41.5% of its comments were Important in Sonnet 4.5 vs only 35.3% in Sonnet 4.But the tone and texture of those comments raise deeper questions about what we want in an AI reviewer.
And then there’s the kicker: Sonnet 4.5 gets you close to Opus-level performance at a fraction of the price, making it a pragmatic sweet spot for teams reviewing code at scale.
Sonnet 4.5 thinks aloud and still delivers decisive fixes but some of its comments are framed as vague “conditional” warnings that could make its comments harder for some to parse.. Let’s dive into our benchmark.
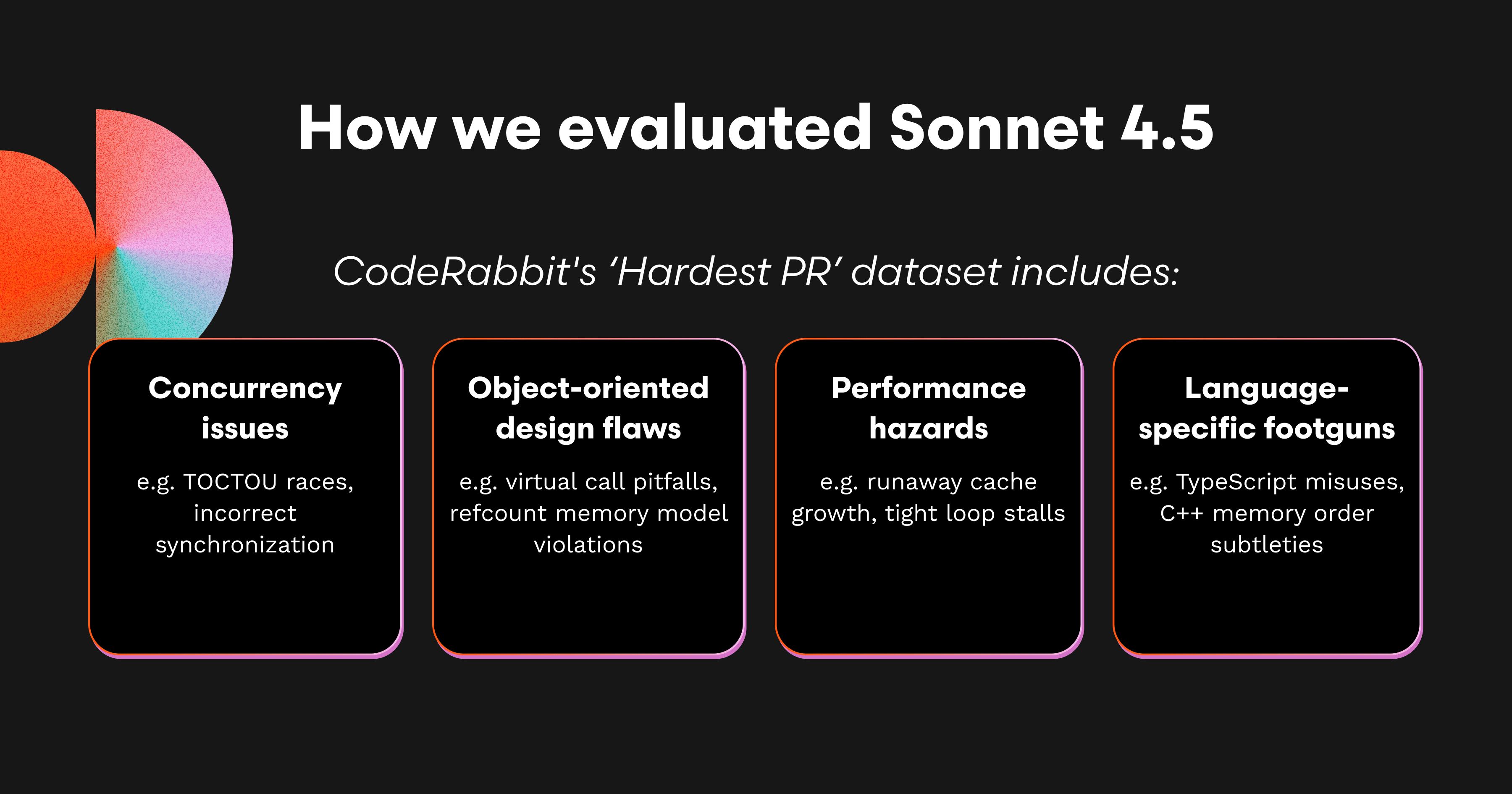
We evaluated Sonnet 4.5, Sonnet 4, and Opus 4.1 across 25 difficult real-world pull requests containing known critical bugs (ranging from concurrency and memory ordering to async race conditions and API misuse). A model “Passed’ a PR if it produced at least one comment directly on the critical issue.
We measured coverage (S@25), precision (comment PASS rate), and signal-to-noise ratio. For signal-to-noise we focus on Important comments (these are the comments that matter most). They include:
PASS comments that correctly addressed the known critical bug in the PR.
Other important comments that did not solve the tracked issue, but still flagged a truly Critical or Major bug elsewhere.
The results were mixed:
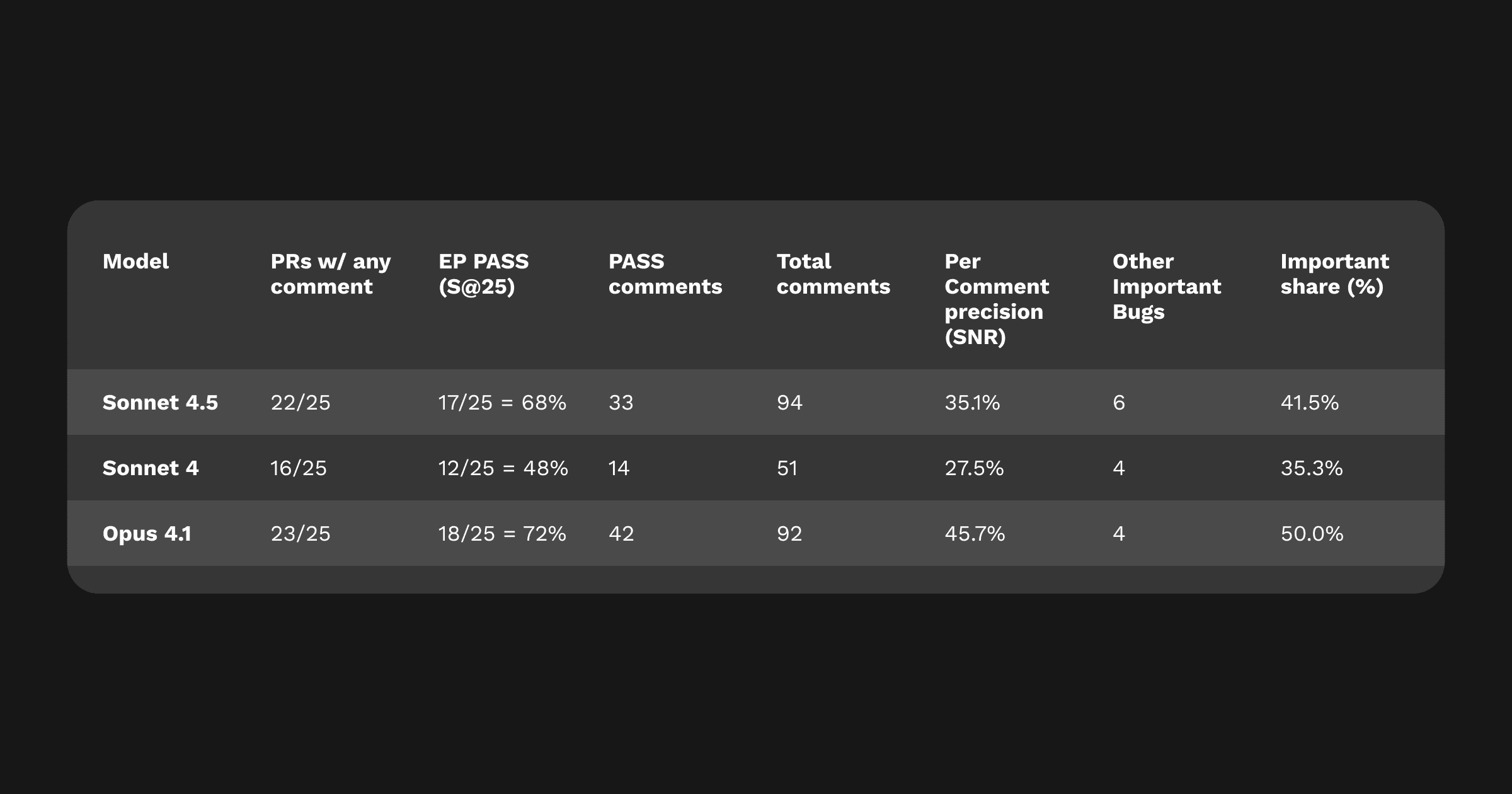
Coverage: Sonnet 4.5 closes much of the gap between Sonnet 4 and Opus 4.1 and lands far ahead of Sonnet 4.
Precision: Opus 4.1 still produces the cleanest, most reliable actionable comments but that is to be expected given that it’s a more expensive model.
Important share (i.e. percentage of comments flagging a significant issue): With stricter criteria, Sonnet 4.5 lands at just over 41% Important share. That means about 4 in 10 of its comments either solved the key bug or flagged another truly significant issue. Opus 4.1 leads here at 50%, with Sonnet 4 at ~35%.
Sonnet 4.5’s comments patch the code but do so in a less confident tone than Opus 4.1 does but is still more confident than Sonnet 4.
Patches present:
87% of Sonnet 4.5’s actionable comments included a code block or diff patch, similar to Sonnet 4 (90%) and Opus 4.1 (91%).
The difference is in style: Opus’s diffs read like surgical fixes, while Sonnet 4.5 often couches them in exploratory text. It “suggests” or “considers” changes rather than asserting them.
Hedging language:
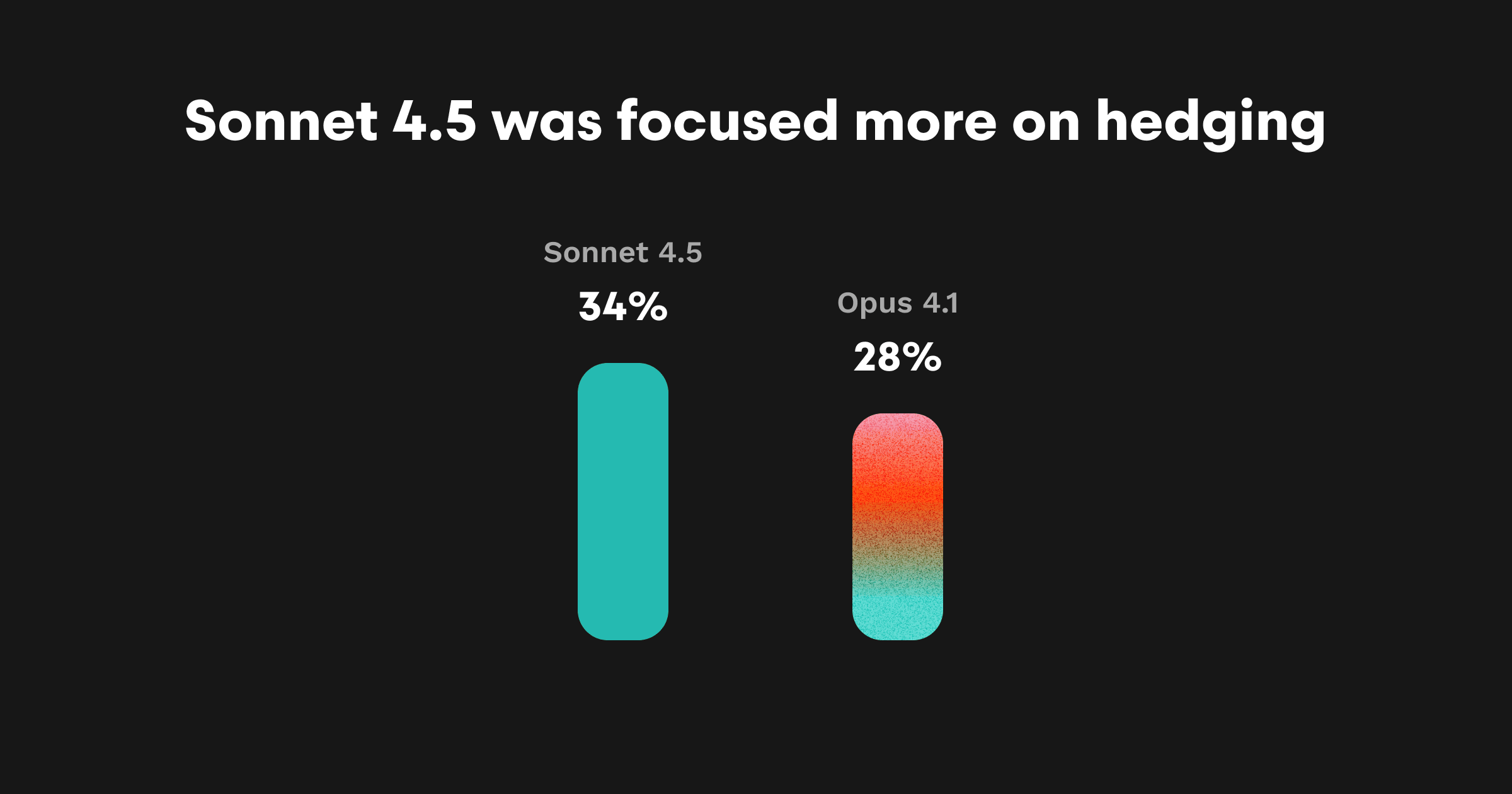
Sonnet 4.5 hedges in 34% of actionable comments—words like might, could, possibly. For example:
“Unnecessary allocation: cache is never used. The constructor allocates 4KB of memory that is never utilized … Consider removing the cache_buffer.”
“Remove the empty try/except block. … likely a placeholder”
Opus 4.1 is steady at ~28%. Sonnet 4 sits slightly lower at ~26%.
This hedging creates an “interrogative” tone: Sonnet 4.5 sometimes feels like it’s thinking out loud with you, rather than delivering verdicts.
Confident language:
Sonnet 4.5 balances that hedging with higher confidence markers (39%) than Sonnet 4 (18%) or Opus 4.1 (23%). For example:
“Critical: Missing self. prefix breaks all API methods. All subsequent methods will raise AttributeError until this is corrected.”
“Potential integer overflow. optimization_cycle_count increments unbounded … this will overflow after ~414 days of runtime.”
In other words, it swings between caution and certainty more dramatically.
Signal-to-noise:
However, when you count its true Important comments—PASS comments plus a small number of high-confidence off-EP issues—it lands at 41.5% Important share. Opus 4.1 is still the gold standard Anthropic model at ~50%.
Across the PRs we tested Sonnet 4.5 with, we saw some clear areas where it stood out.

Concurrency bug-finding: Sonnet 4.5 nailed C++ atomics and condvar misuses with clean, actionable diffs.
Consistency checks: It reliably flagged distributed state mismatches across services.
Extra bug surfacing: It did identify additional Critical issues not originally under evaluation, though fewer than initially expected under a stricter rubric.
As Anthropic markets Sonnet 4.5, they emphasize “hybrid reasoning” and “long horizon” planning. In practice, that shows up as more willingness to chase down side-paths in the code and note real but untracked issues.
One of the biggest advantages of Sonnet 4.5 is its price-to-performance ratio. While Opus 4.1 remains Anthropic's flagship model in raw capability, it also comes at a significantly higher cost.
Sonnet 4.5 narrows the gap in coverage and important bug-finding while staying far more cost-efficient to run. For many teams, that balance of having close to Opus-level results at a fraction of the price is what makes Sonnet 4.5 the most pragmatic choice.
But if using Sonnet 4.5, it’s critical to be aware of its weaknesses. These include:

Deadlock coverage: Like Sonnet 4 and even Opus, it still struggles to trace complex lock ordering.
Verbosity and hedging: Many comments run long, caveated, or uncertain. Compare this to GPT-5 Codex, which in our earlier work wrote comments that “read like patches” with crisp directness. For example, with GPT-5 Codex:
Lock ordering / deadlock: Reorder the lock acquisitions to follow a consistent hierarchy. This prevents circular wait deadlocks.”
Regex catastrophic backtracking: “Remove the nested quantifier to avoid catastrophic backtracking.”
Precision gap: At 35% comment-level precision and 41.5% important share percentage, it’s better than Sonnet 4 but well short of Opus 4.1.
Sonnet 4.5 feels less like a teacher writing in red pen and more like a thoughtful colleague at your side: pointing out possible issues, often right, occasionally over-hedged, and sometimes spotting things you didn’t know were there.
That style is a double-edged sword in review. On one hand, developers may appreciate the extra critical issues it flags. On the other, when the task is “please catch this bug,” Opus 4.1 is still sharper.
Anthropic positioned Sonnet 4.5 as a step toward agentic reasoning and computer use. In code review, that reasoning shows up in richer, more cautious, and more wide-ranging comments.
For teams:
If you value decisive, patch-like feedback, Opus 4.1 (or GPT-5 Codex) still sets the bar.
If you want a reviewer that finds critical issues anywhere they lurk, even beyond the tracked bug, Sonnet 4.5 has surprising upside.
And if you care about pragmatic price-to-performance, Sonnet 4.5 may be the smartest choice: close to Opus’s accuracy at a fraction of the cost.
Either way, Sonnet 4.5 changes the texture of reviews. It feels more human—not always cleaner, but more inquisitive, more hedged, sometimes more right in the places you weren’t looking.



