

Brandon Gubitosa
June 24, 2026
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Collaborative AI keeps humans and agents working from shared repo rules, tickets, review comments, and team decisions so teams can understand, trust, and build on the output. In the agentic software development lifecycle (SDLC), coding agents can draft changes, open pull requests, and trigger downstream checks, which makes review context part of the delivery path.
Once a team ships AI-generated code at volume, the question shifts from writing speed to how well reviewers understand, validate and trust what agents produced.
84% of developers now use or plan to use AI tools, up from 76% in 2024, per the Stack Overflow data on AI tool adoption. The harder problem starts after the agent commits, and a half-human, half-agent team needs collaboration systems to make ai generated code understandable enough to review.
The 2025 report from DevOps Research and Assessment (DORA) calls AI the great amplifier, and found that AI adoption correlates positively with delivery throughput and negatively with delivery stability. The cost shows up as more change failures, more rework, and longer recovery.
At the individual level, the productivity gains are lost downstream when teams re-spend the time saved writing code on auditing, fine-tuning, and correcting AI output. Individual speed can rise while team output stays trapped behind review, testing, and rework.
Re-spending that saved time on auditing has a name: the verification tax. One developer quoted in DORA's research put it plainly: "I feel somewhat more productive, but it's at a cost. While I end up spending less time writing code, I spend more time babysitting the AI and reviewing what it is trying to do."
The CodeRabbit platform reviews everywhere developers work: the pull request (PR), IDE, CLI, and Slack. Its AI-vs-human report makes the bottleneck measurable: AI-co-authored PRs averaged 10.83 issues per PR versus 6.45 for human-only PRs, 1.7x more findings. At the 90th percentile, AI PRs carried 26 issues versus 12.3, the kind of outlier workload that blows up reviewer capacity. Review becomes the throughput ceiling when code arrives faster than anyone can validate it. At freee, engineers facing that volume used CodeRabbit to recover 32.8 weeks of reviewer time over six months.
Developer adoption rose from 76% to 84%, and trust moved the other direction. Stack Overflow's accuracy trust analysis put trust in AI accuracy at 29% in 2025, down from 40% in 2024. The biggest frustration, cited by 66% of respondents, is output that's almost right, but not quite. You know the kind: it survives your skim and fails in production. Almost-right is the worst kind of wrong.
Security and maintainability show the same pattern. An AI vulnerability study found AI-generated code more frequently triggers high-risk vulnerabilities, led by command injection and hardcoded secrets. GitClear's research on AI-generated changes found newly added code growing as a share of changes, code duplication rising, and refactoring shrinking as AI proliferated. Separate maintenance research found agent-generated code receives less ongoing maintenance, leaving humans to absorb the large majority of fixes.
The failure mode is bigger than a bad autocomplete suggestion. AI output can look plausible while pushing risk into security review, future maintenance, and production behavior.
Can a model reliably catch its own mistakes? The evidence says no. Models can favor their own outputs, and some bugs require intent rather than another structural pass over the code. A reviewer working from the same limited context can miss the same intent-dependent problems as the generator. As CodeRabbit's AI-vs-human report puts it: "Don't trust the AI that created the error to find it. If it added the error into your code, it's less likely to find it." Review needs independent verification and project-specific context; another pass over the same diff leaves intent gaps intact.
Agent failures usually come from missing context.
As Greg Foster put it in The New Stack, the context bottleneck is "the gap between what engineers carry in their heads and what AI can understand or communicate." A model has no access to your project-specific invariants, repo conventions, or the decisions your team made last quarter that explain why a function looks the way it does. It only knows what the team feeds it. Some bugs are visible only through intent: code can look structurally valid while still violating what the system was supposed to do.
The same failure shows up in CodeRabbit's AI-vs-human report: logic and correctness issues were 1.75x higher in AI PRs, while algorithm and business-logic errors were 2.25x higher. The analysis points to the local business logic and domain context gap. LLMs generalize from broad training data, while teams depend on project-specific invariants, configuration rules, and edge cases. Feeding agents the operating context the team already uses closes part of that gap.
Version-controlled context files were an early answer. The AGENTS.md / CLAUDE.md convention is now widely adopted, documented in 60,000+ repositories, and Addy Osmani's AGENTS.md guide frames it as a way to stop repeating project rules to every coding agent. It helps, but only when the file holds useful, human-authored context. An InfoQ-reported context-file review found LLM-generated files actually cut agent success by about 3%, while human-curated files gave a marginal 4% gain, roughly 20% token overhead either way. Model Context Protocol (MCP) connections push further, and Anthropic describes MCP as an open protocol for connecting agents to external systems and context.
Together these give agents persistent ways to read project rules, tools, and external systems. You still need governed review across all of it, no matter which generator wrote the code.
Useful review comments draw on the same artifacts senior reviewers rely on: codebase history, the linked ticket, prior PRs, and past reviewer feedback.
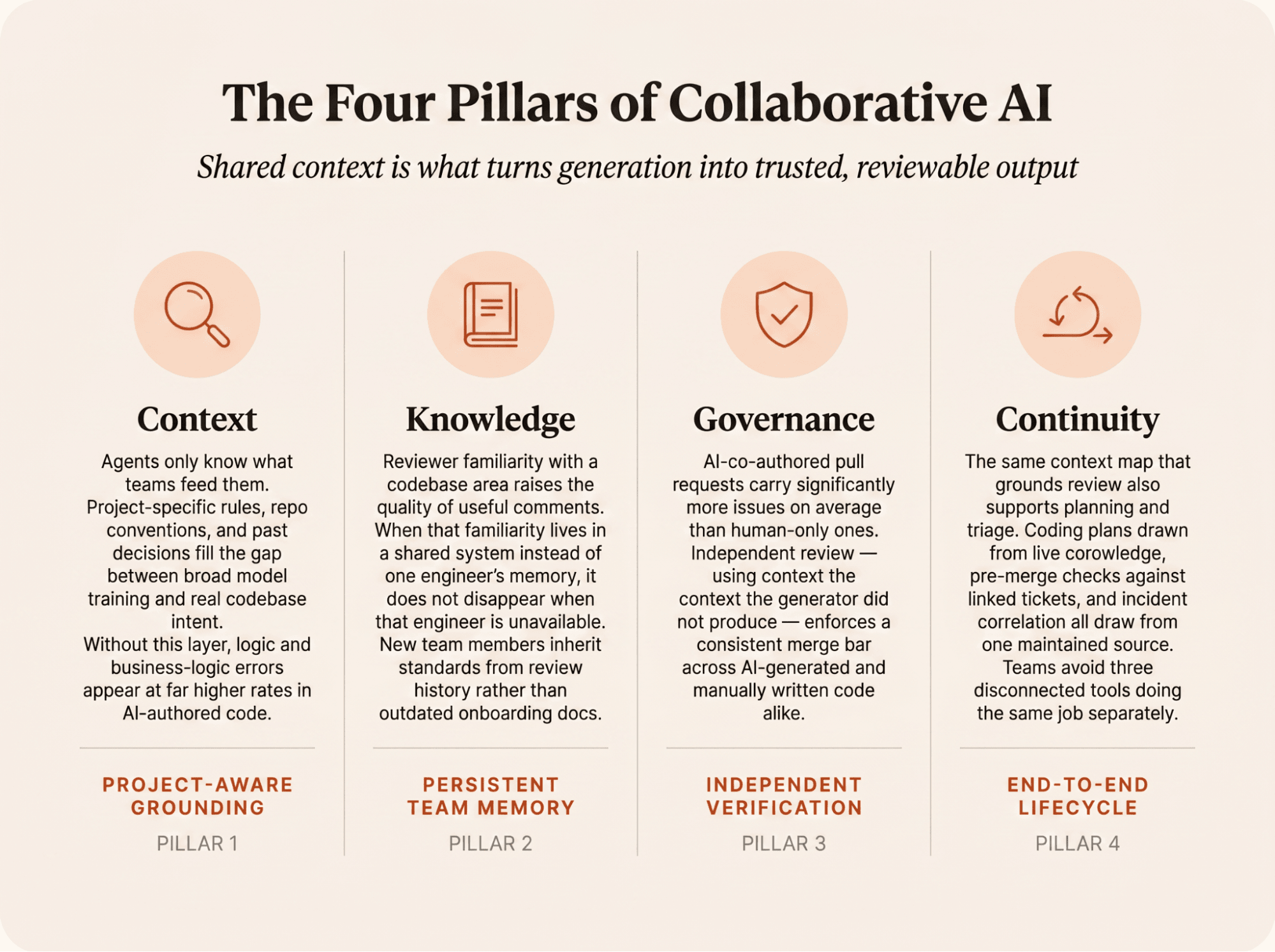
Once those artifacts live where the whole team and its agents can read them, they do four distinct jobs, each one closing a failure mode from the sections above.

CodeRabbit reviews the artifacts that usually sit outside the diff. The context engine indexes your codebase, linked tickets, prior PRs, and team decisions, then grounds its review feedback in that context the way a senior engineer would. CodeRabbit Learnings remember reviewer feedback and apply it to future reviews. The strength is the maintained map itself, kept current as the team works.
Independent verification works best when the reviewer and the generator don't share the same blind spots. The review system needs context maintained by the team that knows its own conventions. Autonomous loops raise the trust bar.
At Abnormal AI, 250 engineers needed a consistent enforcement layer across AI-generated and manually written code, and the team reached a 65%+ acceptance rate on critical-severity comments. Mastra's 16-person engineering team used CodeRabbit through the path to its 1.0 release, resolving 70 to 85% of critical comments before PRs merged and ending with zero follow-up PRs. Abhi Aiyer, CTO at Mastra, said: "CodeRabbit is the only tool that I trust after fully autonomous coding loops."
Among CodeRabbit's 15,000+ customers, internal operational metrics as of May 2026 show the platform reviews 2 million PRs per week, and CodeRabbit company statements in June 2026 said the platform reviews PRs across 3 million+ repositories. Small teams and large organizations hit the same constraint once agentic output enters the codebase: review needs the context to validate it.
Shared context matters most when it maps to outcomes engineering leaders already track: shipping better code, stability metrics, defect escape rate, security controls, and knowledge transfer. The repo rules, requirements, and incident history deliver on those outcomes when the same knowledge travels through planning, review, triage, and incident response.
The foundational modern code review study found reviews deliver knowledge transfer, team awareness, and shared code ownership alongside bug-catching. Microsoft Research's follow-up work on reviewer familiarity showed useful comment ratios climb the more times a reviewer works the same area of the codebase. When reviewer familiarity lives in a shared-context system instead of one senior engineer's head, the value stops walking out the door when they take PTO. New hires inherit standards from review comments instead of an onboarding doc nobody reread.
CodeRabbit carries the same codebase context from planning through review to triage. CodeRabbit Plan turns issues and requirements docs into codebase-aware Coding Plans you hand to any coding agent. Downstream, Pre-Merge Checks validate the implementation against the linked issue before merge. The CodeRabbit Agent for Slack reuses the same context to correlate Sentry errors with merged PRs and Jira issues, then opens a PR your team still reviews. The payoff for you is one context map, maintained once, that serves planning, review, and triage instead of three disconnected tools.
AI generation is cheaper every quarter; trust still has to be earned. Teams adapting to agentic development are putting that shared context, the repo rules, tickets, and prior reviews, where both humans and agents can use it.
CodeRabbit's context engine indexes those artifacts for independent review, so generated and manually written code face the same merge bar.
Cut code review time & bugs by 50%. Start a free 14-day trial.



