On June 16, 2026, SpaceX agreed to buy AI coding start-up Cursor for $60 billion in an all-stock deal. Cursor helps developers write code and also reviews code through Bugbot. Put that inside a broader corporate stack that already owns infrastructure, models, and generation, and the question for engineering teams becomes unavoidable.
Should the same AI stack that writes the code also be trusted to review it?
In school, we call that grading your own homework, and in software, the stakes are higher. The code may compile, the agent may explain itself, and the reviewer may sound confident, but confidence is not verification.
As AI writes more of the code teams ship, an independent reviewer becomes the safeguard that keeps teams moving fast without sacrificing quality. It also brings separation of duties to AI development, making sure the system that helps create the code is not the same one deciding whether it is safe to ship. For enterprise teams, this is a way to get ahead of the governance and regulatory expectations forming around AI-generated software.
A model is a poor judge of its own work
Consolidation in this market is moving quickly, with AI coding platforms adding their own review features. Cursor’s BugBot defaults to using Composer 2.5 for code review, the same model family used to generate code. The convenience is real, but when the same stack writes and reviews the code, it can carry the same assumptions into both steps, which makes it more likely to repeat the same oversight rather than catch it.
One study found that large language models exhibiting Self-Correction Blind Spot have a 64.5% average failure rate when asked to correct errors they produced themselves. A separate analysis found that generated code passed 9 to 17 percentage points more often when it was tested by models in the same family than when it was tested independently.
Models that share training tend to share blind spots and often fall into the Homogenization Trap, so a model checking its own output is inclined to approve it.
The volume of AI-generated code makes this harder to ignore. Industry data points to a 14x increase in GitHub commits in 2026 attributed to AI coding, and a 40% increase in critical issues found in pull requests. There is also a 81% increase in secrets leaked in code, alongside an explainability gap in which AI is outpacing human comprehension of code by 5 to 7x.
Code review functions as the final checkpoint before production, and that checkpoint can’t be trusted when the same model both produces the code and signs off on it.
Compliance frameworks are moving in this direction
Separating the author of a change from its reviewer is not a new idea. It is an established governance practice, borrowed from how finance has handled trust for decades.
After the Enron and WorldCom scandals, where the creator and the reviewer of financial records shared incentives, Sarbanes-Oxley Act required companies to separate the external auditor from the accountant. The separation worked because it removed the conflict at the source rather than auditing around it.
What reads today as good practice is beginning to look like a requirement. SOC 2, the AICPA framework that many enterprise buyers ask their vendors to meet, addresses the issue. Control CC8.1 governs change management and calls for Segregation of Duties (SoD). The principle is that the party which authors a change cannot also approve it and push it to production without independent review.
Engineering leaders who decouple authoring from review today are proactively de-risking the AI pipeline ahead of any mandate, and turning a future compliance obligation into a present advantage. This is already appearing in enterprise purchasing conversations.
One engineering director at a quality engineering platform put it plainly that their security team “doesn’t feel that using the same tool for coding and PR reviews is a good idea.” An engineering leader at a security company put it even more directly: “We do not necessarily want the AI coding assistant vendor to also be our PR review vendor.”
How CodeRabbit delivers independent, explainable AI code review with the best ROI
Built to review independently
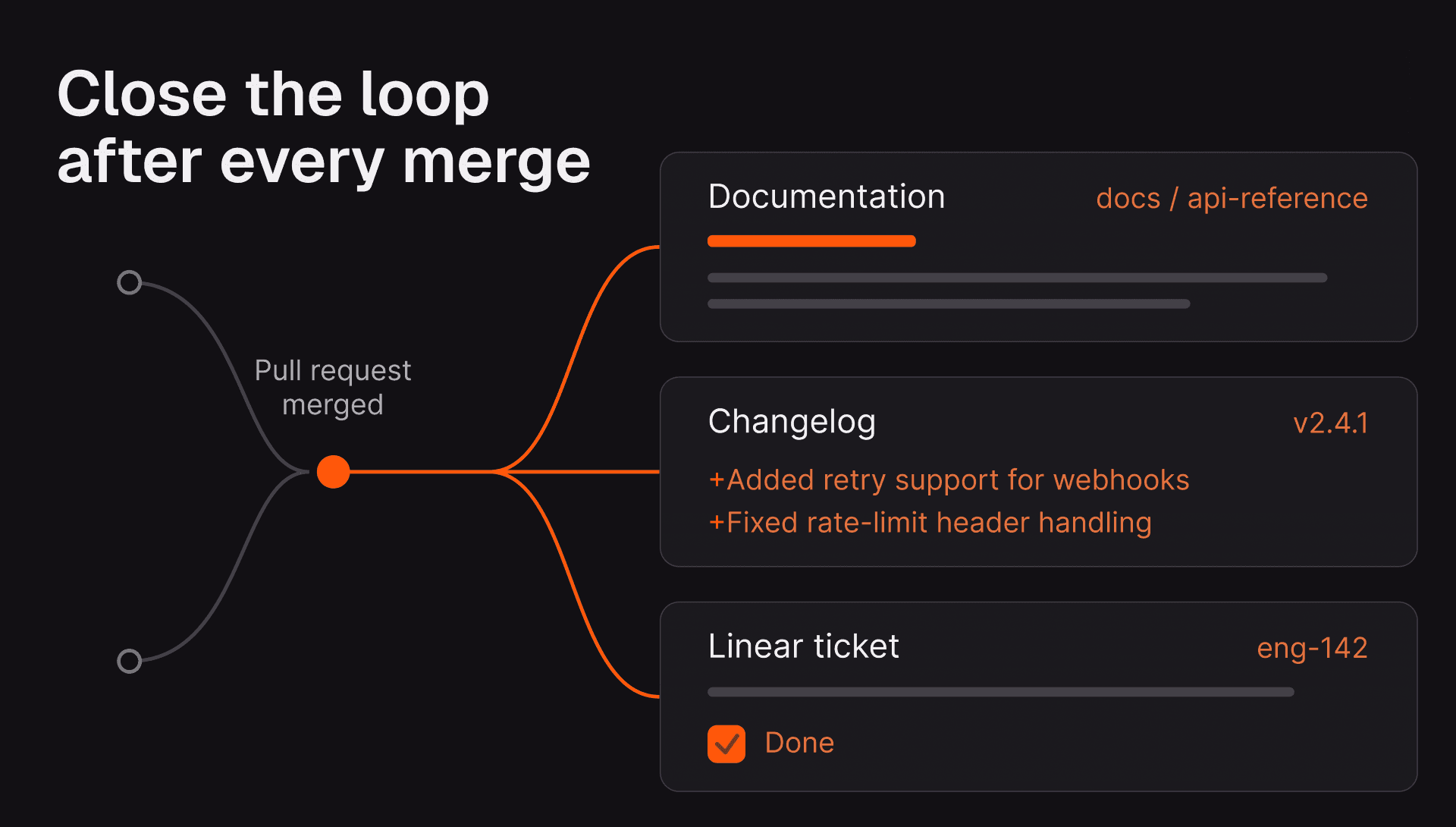
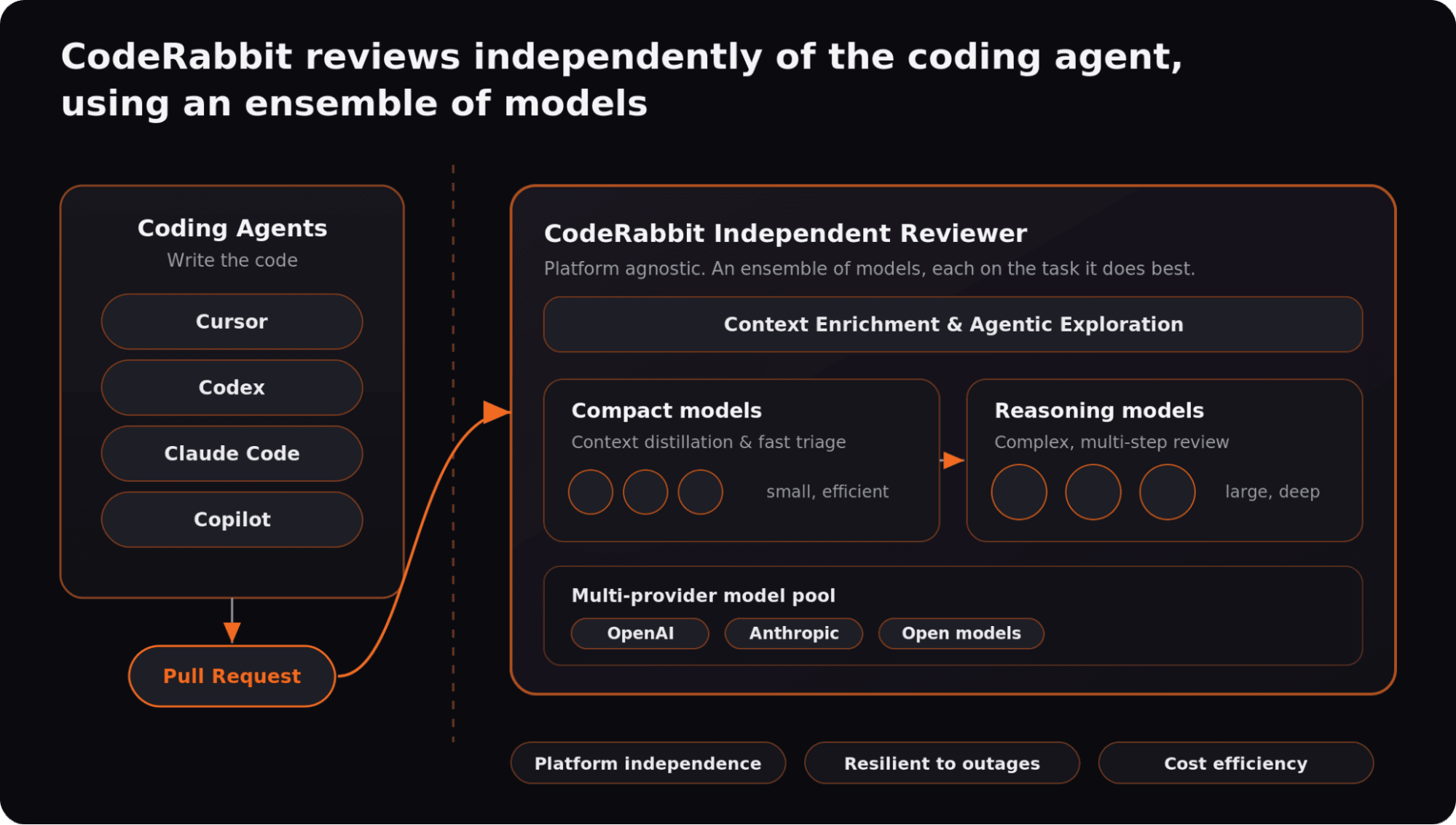
By nature, CodeRabbit separates the writer from the reviewer. It's platform agnostic and operates independently of coding agents, running alongside tools like Cursor, Codex, Claude Code, and Copilot rather than being bundled into the same generation stack.
Under the hood, CodeRabbit uses an ensemble of models instead of relying on a single model for the entire review. Compact models handle context distillation, while larger multi-step reasoning models are reserved for more complex tasks. Multiple models work together, each focused on the task it is best suited to do.
This design also improves resilience. If one model provider is degraded or unavailable, reviews can continue through other models, reducing dependence on a single model provider.
Cost efficiency is another benefit of the multi-model approach, giving engineering teams the best ROI in code review. Teams get high-performance review, predictable seat-based pricing, and flexible usage-based add-ons for high-throughput agentic loops.
The purpose-built and explainable review layer teams can trust
As more code is generated by AI, explainability is becoming the missing layer in code review. CodeRabbit has long provided structured summaries and walkthrough comments for every pull request. The recently launched Change Stack feature takes explainability further by turning the diff into a guided, layer-by-layer walkthrough.
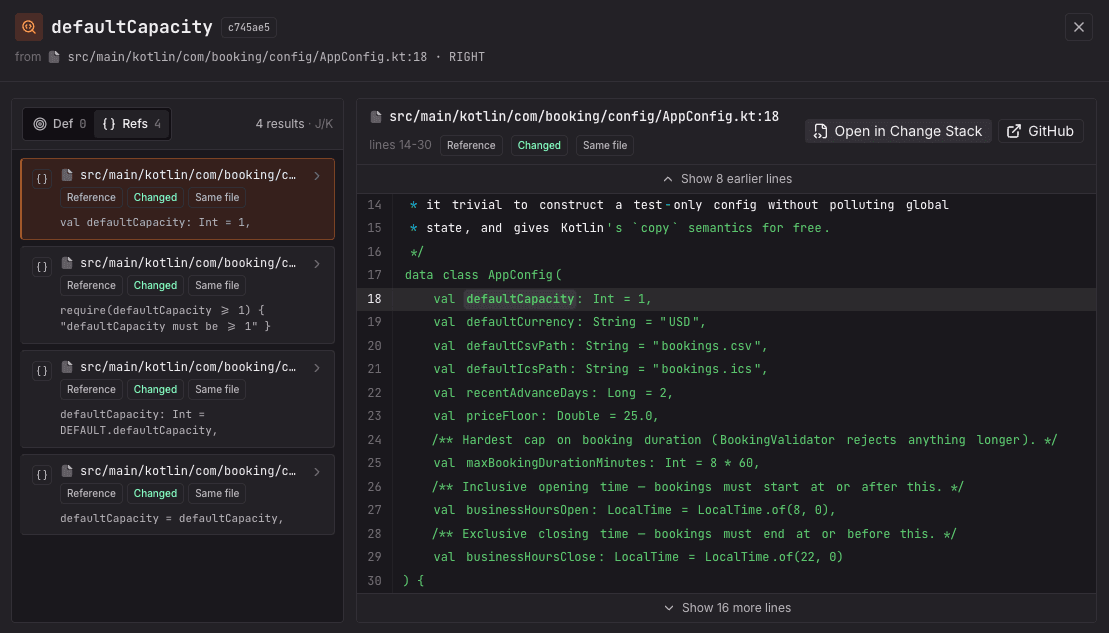
It identifies semantic relationships between changes, groups related code blocks into logical cohorts, and orders those cohorts by dependency. Instead of reviewing a PR file by file, human reviewers can follow the change in the order the system actually fits together. It is like having a senior engineer walk you through the PR.
What the Cursor acquisition means for engineering leaders
The Cursor deal makes the trust problem obvious. More of the software development lifecycle is being pulled into the same vendor stack, from writing code to reviewing it. That may be convenient, but it raises a question every engineering team should ask. Should the same system that helped create the code also decide whether it is safe to ship?
Independent review exists for a reason. Models can miss their own mistakes, and models from the same family tend to share the same blind spots. Engineering leaders already identified the risk, and established change-management practices also recognize the value of separating the author of a change from its reviewer.
CodeRabbit gives teams that independent review layer, combined with a specialized, feature-rich platform for explainable code review. Teams can validate AI-generated and human-written code, understand why issues were flagged, catch defects before production, and ship faster with confidence.
Proactively de-risk your AI development pipeline with independent, explainable code review. CodeRabbit comes with a rich feature set, enterprise controls, and governance built in, battle-tested across more than 15,000 engineering teams. Talk to our sales team to learn more.