
CodeRabbit is now in the Claude Marketplace!Learn more

Yiwen Xu
May 19, 2026
6 min read
May 19, 2026
6 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
CodeRabbit is the verification layer and quality gate that developers and organizations trust. But a great review does more than point out bugs or suggest fixes. It helps teams trace a change from implementation back to intent: what changed, why it matters, how to improve it, and whether it is safe to ship.
That job is becoming harder as developers rely more on coding agents. AI is already changing the shape of software delivery: teams with high AI adoption are merging 98% more pull requests while spending 91% more time on review, according to a Faros AI study of more than 10,000 developers. When more code is being produced and shipped faster, review cannot just be about catching bugs. Teams need a better way to understand what changed, why it matters, and how it connects to the rest of the system before it ships.
This is the idea behind explainability. Harjot Gill, our CEO, has framed this as the agentic-era equivalent of cloud observability. As more coding work shifts to AI agents, humans need a new interface for understanding and trusting the output. Explainability is becoming the new observability: the layer that helps teams see, understand and verify what their systems and their agents are doing.
Recently we launched CodeRabbit Review, a new AI-native review interface that walks reviewers through a pull request like a senior engineer would. CodeRabbit already helps teams understand changes through summaries, walkthroughs, logic diagrams, and actionable review comments. CodeRabbit Review builds on that foundation by showing the path through a change, not just what changed, but how the pieces connect.
As developers write less code by hand and rely more on agents to generate it, review shifts from "is this diff correct?" to "did the system build what we intended?" We call this reviewing intent: verifying the plan and the outcome, not just the keystrokes.
The diff has been the default review interface for nearly two decades. CodeRabbit Review shows what becomes possible when the system can explain the shape of a change and help developers verify that it matches their intent.
For example, CodeRabbit reviews PRs using semantic diffs. Traditional line-by-line diffs treat a renamed variable, a reformatted block, and a real logic change as equally important, forcing reviewers to separate signal from noise by hand.
Semantic diff understands the structure of the change. It filters out irrelevant changes, detects moved code, and surfaces only the changes that matter. Reviewers see what actually changed, so they can review code faster and more accurately. That experience is only possible because of the deeper system underneath: context engineering that understands intent, connects changes across files, reasons about impact, and explains the path through a pull request.
At CodeRabbit, a trustworthy and explainable review starts long before the review comment is written.
For every PR, we build the context the model needs to reason accurately. We clone the repo, analyze the diff, and construct a code graph that traces how the change connects to the rest of the codebase cross-file and cross-repo. The context engine then pulls in the surrounding engineering knowledge linked issues, architecture standards, custom review instructions, coding conventions, past PRs, team-specific learnings, and through MCP, the documents and systems your team builds against and filters all of it down to what is relevant to this specific change.
Signals from 40+ linters and SAST tools feed in alongside, real-time web queries pull current release notes and newly disclosed vulnerabilities, and everything runs in an ephemeral, isolated sandbox with zero data retention.
This is the work behind the work. In our system, we do a lot of work in context enrichment. The hard part isn't asking an LLM to review a diff. It's giving the model the right context, in the right order, at the right level of detail so it can understand intent, reason through impact, and explain its findings clearly.
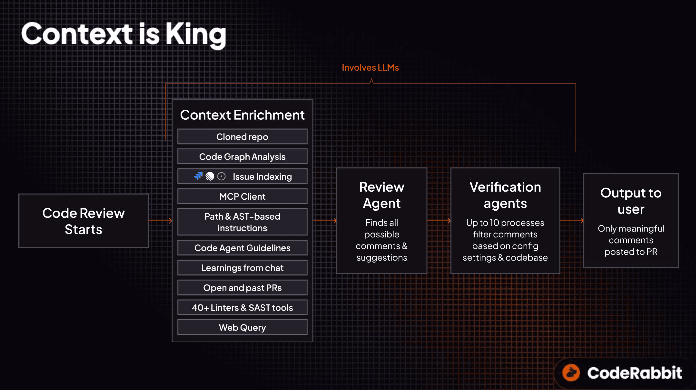
The harness around the context engine matters just as much. It routes each task to the right model by complexity: cheap and fast where deep reasoning isn't needed, frontier where it is, open models where they meet our quality bar. A review agent surfaces possible comments; verification agents filter them against the code guidelines, configuration, and team preferences before review comments reach developers. Underneath all of it sits an evaluation framework that tests every model release, prompt change, and context strategy against recall, precision, latency, and cost. That feedback loop is how we improve quality without just throwing more tokens at the problem.
This is the system around the system: context retrieval, ranking, filtering, sandboxing, tool orchestration, prompt design, model routing, verification, and evaluation loops all working together.
CodeRabbit has spent three years refining this harness across millions of pull requests and more than 15,000 engineering teams. That accumulated domain expertise, knowing which context matters for which kind of change, is the difference between a system that summarizes diffs and one that finds the issues that could derail what you intended to ship.
AI can write the code, but your team is still responsible for what ships. CodeRabbit is the AI-native quality gate that helps teams move fast without losing control. It provides instant explainability for every change and enforces consistent standards across every pull request, so what ships matches what you intended.
Try CodeRabbit Review on the next large PR in your queue. CodeRabbit Review is free for a limited time for every CodeRabbit user. You can find it by clicking Review Change Stack in the CodeRabbit PR summary comment.



