

Priyanka Kukreja
May 08, 2026
12 min read
May 08, 2026
12 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Explainability is what determines whether an AI Agent gets deployed to solve real-world problems, or remains a sidekick on non-critical enterprise tasks.
A year ago, Agentic AI launched and blew everyone away. It transformed the LLMs from a chat tool to the one that can actually “do” things for you. But now that agents are near-ubiquitous, they face a tougher problem: Earning trust.
An agent can be called "autonomous", but if it can't explain to my stakeholders the what and why of my agent’s actions (say, my manager or my customers or my audit review team), then its autonomy isn't really worth much.
Whether agents get used on serious work, or stay sidekicks on low-stakes tasks, comes down to just one thing: can people really understand what it’s doing?
First, it's worth separating "explainability" and "observability", which are sometimes (incorrectly) used interchangeably.
Observability is about "what happened". This is a simple mechanical record of actions, tool calls, inputs, outputs, branching paths. This is an engineering problem that's largely solved. You can build structured logging for , and the challenge here is making those logs useful at scale.
Explainability is about "why it happened". This is about understanding agent's reasoning behind decisions, the alternatives it considered, how confident it was. etc. This is the harder, partly unsolved problem.
Now, if any of the following holds true, the agent has to explain itself further.
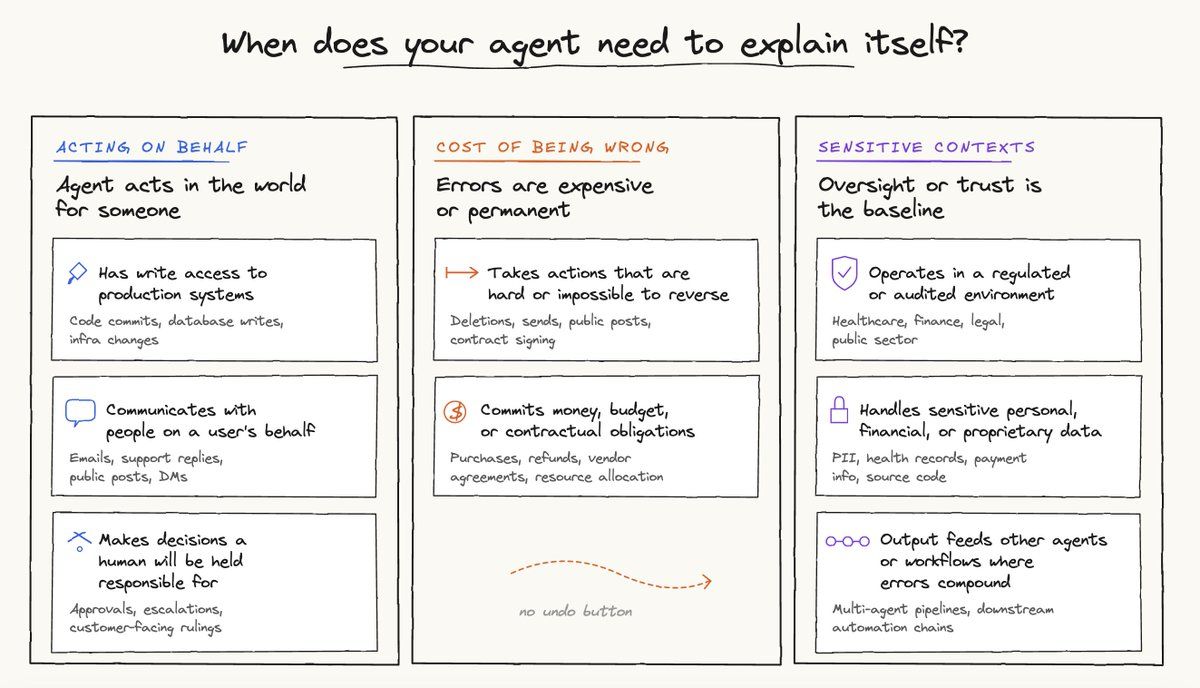
In these situations, if the agent can't explain itself, you end up with a trust deficit.
A classic example of this is something every agentic engineering team knows well: an incident occurs and developers are trying to debug what the agent did. They pull up logs, and find that the agent was tasked with X but also did Y and Z. They try to piece together a timeline and the root cause. But the path from agent’s action to real-world outcome isn’t clear, and neither is the reasoning behind those actions.
This “trust” tax compounds silently but surely. Once users stop understanding what the agent is doing, they lose confidence it will do the right thing. Over time, they hesitate before handing anything mission-critical, and end up adding manual review steps that eliminate the productivity gain. Sure, the agent offers autonomy, but it fails to build confidence. And, without confidence, autonomy stops getting used (on the things that matter, at least).
This is not just a hypothetical failure mode. It shows up across every category of AI deployment: from code review agents that developers second-guess despite high accuracy, to customer-facing agents where support teams shadow every interaction, not because quality is poor, but because no one can explain what happened when a customer escalates their issue to support.
This gap between what an agent logs and what a human can actually understand is what ultimately keeps agentic products from getting traction.
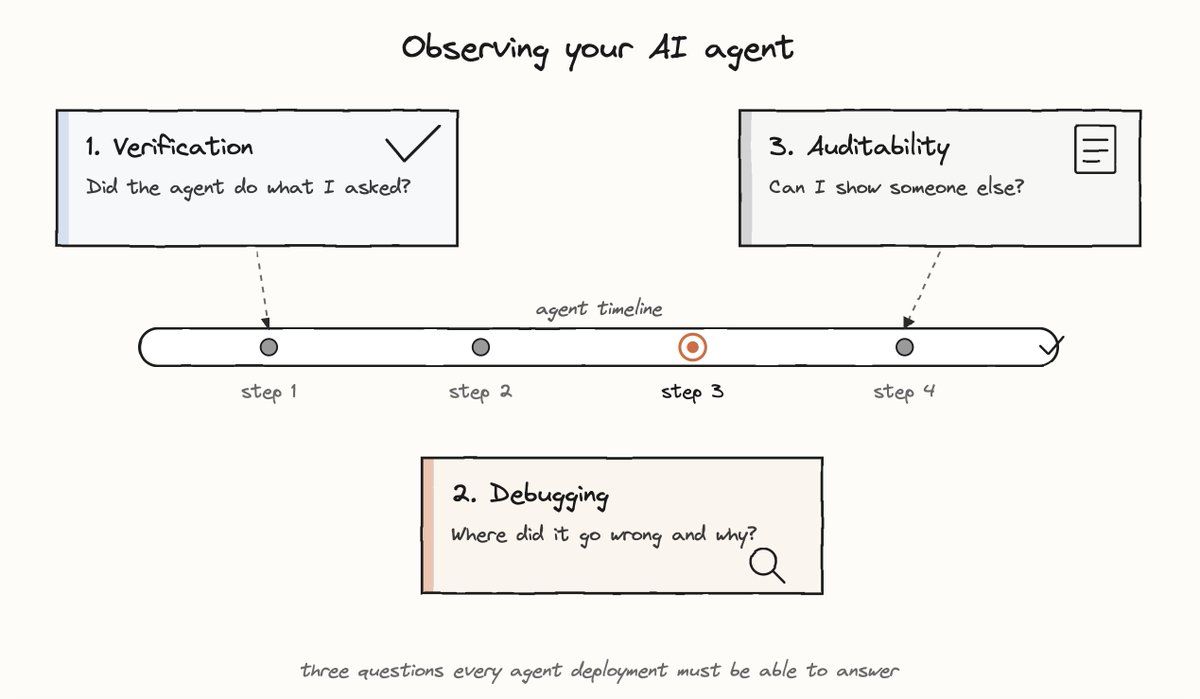
Explainability has three primary jobs-to-be-done, each requiring a different product response:
The user wants a fast, high-confidence signal. They are not debugging or looking for a trace. They just want a checkmark. Showing them a tool call log here is the wrong answer. It would be like responding to “did the payment go through?” with a database query result.
This user already suspects a failure. They need to trace the decision path, identify the branch where things diverged, and understand the root cause. Here, what they need is depth, not just an outcome or a reassurance.
The primary consumer here is not the user. It is their manager, their compliance team, their customer, or their future self six months later trying to understand a past decision. Accordingly, the artifact here must be exportable, immutable and structured for a reader with no prior context.
A product that tries to serve all three from a single interface will serve none of them well. Each use case has different requirements: verification needs compression, debugging needs depth and auditability needs structure and permanence.
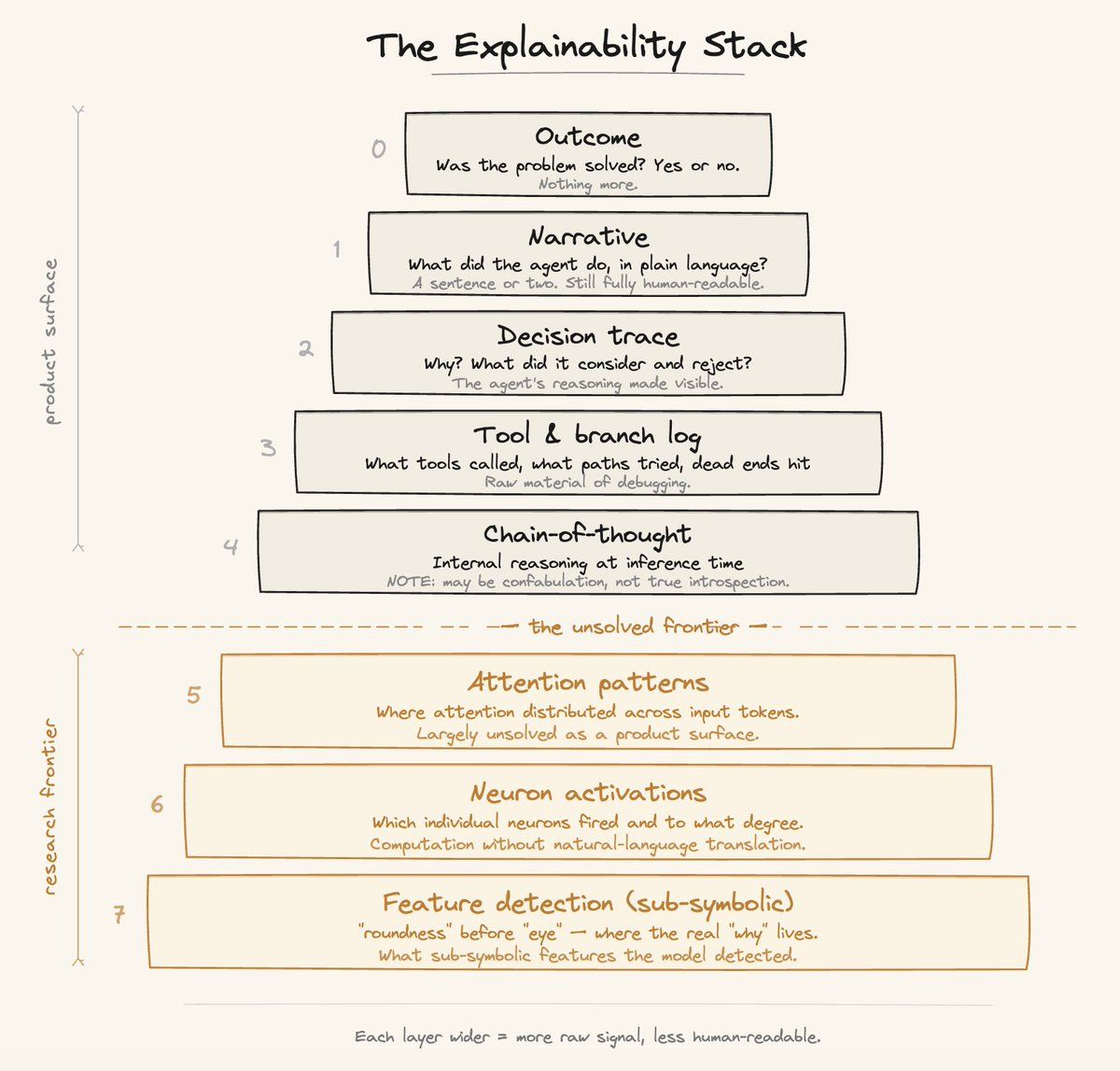
I think about explainability and observability as a layered architecture, not a single feature. Each layer is the right answer for a different user in a different context.
Layer 0 - Outcome: Did it work? A simple binary. This is what most users want most of the time for routine tasks.
Layer 1 - Narrative: A plain-language summary of what the agent did and why. "Created the PR, flagged three issues, posted inline comments on lines 42, 87, and 203." Think of it as an expedition report: the agent went out, came back, and here is what it found.
Layer 2 - Decision Trace: Why did the agent make the choices it made? What alternatives did it consider and reject? This is where you begin to see reasoning, not just actions.
Layer 3 - Tool and Branch Log: What tools were called, with what parameters, what was returned, what paths were explored, what dead ends were hit. This is where engineers live when something breaks. It is still output-based, not reasoning-based, but it shows the mechanical path the agent took.
Layer 4 - Model Reasoning: Chain-of-thought at inference time. This is where the model starts showing its actual reasoning process. This is super valuable for evaluation, model improvement and fine-tuning pipelines, while still being relevant for end users in production environments when something has gone wrong.
Layers 5 to 7 - The Deep Stack: Attention patterns, neuron activations, interpretability research. This is the frontier of mechanistic understanding. It is a fascinating science, but not a product feature (yet).
The pattern is consistent: the closer someone is to the implementation, the deeper they want to go. A solutions engineer reviewing a weekly agent summary lives at Layer 1. A developer debugging an unexpected tool call lives at Layer 3. A researcher studying emergent model behavior lives at Layer 5. Explainability and observability are not one size fits all and are defined by where your user actually sits.
The Explainability stack has two practical applications: (1) defining the right user experience, and (2) diagnosing where your success metrics are breaking down.
Start by listing every audience that touches your agent: say, for example, the end user, support, the sales engineer, the compliance reviewer. For each, ask which layer they actually need. Most teams collapse this into a single "show logs" toggle, which over-shows to non-technical users and under-shows to engineers. The fix is layered disclosure tied to specific surfaces:
Layer 0 in the headline UI: A green check on the PR, or a "3 tickets resolved" badge Layer 1 in async recaps: A Monday digest in Slack, or a weekly email summary Layer 2 behind a one-click "why?": On any decision the user might disagree with Layers 3 and 4: Gated behind a developer console or audit export
The payoff for this segregation shows up in support. When a customer says "the agent did the wrong thing," you can walk down the stack with them, starting from the outcome and going deeper only as needed. That is how trust gets built in practice.
Each layer you skip has a cost, and the cost compounds the further along in your deployment you are.
Skipping Layer 0 or 1 hurts adoption. A basic trust loop with the user is not built, which leads them to never delegate a second task. The agent stalls at novelty. Skipping Layer 2 hurts retention. Users only continue handing off work to an agent they feel confident they could overrule. This is why Cursor's diff view and Codex's change preview matter as much to stickiness as a model upgrade, if not more. Skipping Layer 3 stalls enterprise deals. The criticality of this layer would depend on the industry and the regulatory environment your product operates in. Skipping Layer 4 undermines your evals. Without reasoning traces, your evaluation pipeline anchors on outcomes alone. That makes it nearly impossible to tell whether the agent took the right path to a result, or whether it got lucky on test data.
There is a temporal dimension to explainability that most teams underspecify, and it changes the product architecture substantially.
Synchronous explainability enables users to watch the agent work in real time: thinking traces, live tool-call streams, visible course corrections. This modality serves a different purpose than the final output. It builds confidence during execution. When a user can see the agent head down an unproductive path and self-correct, that visible recovery builds further trust. More importantly, it creates the opportunity for the user to intervene early, saving time and tokens.
Asynchronous explainability is a post-facto report. The agent executed, returned, and here is a structured account of where it went and what it decided. This format is what makes parallel agent workloads manageable at scale. If you are operating a fleet of agents across a codebase running simultaneous reviews, dependency checks, security scans, you cannot watch each one live. This expedition report format helps provide that management layer.
Sync and async explainability are not the same product. They have different information hierarchies, different latency tolerances, and different “emotional contracts” with the user. Building one does not necessarily give you the other.
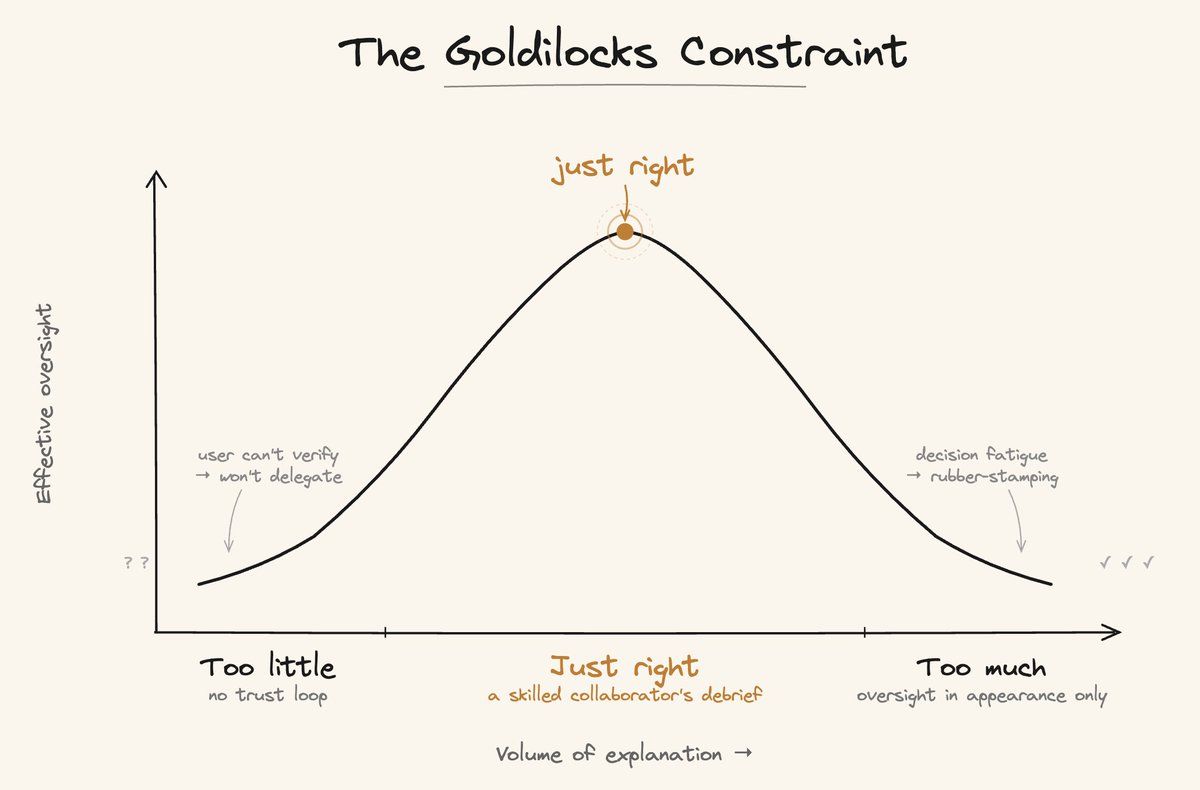
There is a delicate calibration problem at the center of all of this:
Too little explainability: here, users cannot verify the agent’s reasoning, so they will not hand the agent anything that matters.
Too much explainability: users hit decision fatigue. Once they stop reading and start rubber-stamping everything because of the sheer volume of output, user engagement becomes performative. It is only a matter of time before the adoption will stall.
The perils of first failure mode are well documented above. But the second one works in a more insidious way by producing an appearance of oversight without the substance of it. For anyone operating in a regulated environment, that gap can become a compliance liability faster than it looks.
This is also Goodhart’s Law showing up in a new domain: when a measure becomes a target, it stops being a good measure. If “volume of explanation” becomes the proxy for “quality of oversight,” products will optimize the proxy and lose the thing it was meant to measure. More logs, traces, and reasoning text would translate to a reader who has stopped engaging with any of it.
The reference point I keep returning to is this: what does a skilled human collaborator tell you after working on something independently? They do not narrate every search query, or share their entire browser history. They say: 'I looked at X and Y. X was a dead end for this reason. Y is the path forward, here is why, and here is what I am not certain about.'
There are several modalities to render explainability: natural language narration, structured timelines, visual diff rendering, collapsible tool call trees. All are legitimate formats depending on context. The more interesting product question is not which modality to choose, but how you empower the agent to determine the appropriate one given the context and the user.
For synchronous traces, more raw structure is acceptable since the user is present and can navigate. For asynchronous reports, where the reader has no prior context, you cannot expect them to parse the raw logs. Curation becomes table stakes: relevance, readability, parsability.
I do not think this problem has a clean industry solution yet. But teams that frame it as a product design problem, rather than just an engineering logging problem, will get there faster.
A few years from now, we will reflect back on what made certain products more successful than others. One thing would be clear: it is the products with better explainability that enjoy greater user trust and so were the ones chosen to tackle mission-critical tasks.
As the foundational models head towards commoditization, the true differentiator would be how deeply a product can build a bond with the user. Trust is the foundation of any bond, for both humans and products.

At CodeRabbit, this is not just theoretical. We are building explainability across the board on all of our products. The question of how to show developers what happened and why, without burying them in the output, is one we are working through in production right now. More on what that looks like soon!



