


Juan Pablo Flores
Gowtham Kishore Vijay
June 30, 2026
12 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Anthropic just shipped Claude Sonnet 5, the newest model in its mid-tier line. This post answers one simple question: Should you stay on the model you use today, or move up to this one?
Sonnet 5 didn't land out of nowhere. We've reviewed a string of new models on the blog over the past month:
Sonnet 5 feels like the rest of the Anthropic family. It's patient and thorough, and it likes to think a problem all the way through before it acts.
For writing and building code, Sonnet 5 is the most capable model we've worked with at this tier, and it's an easy upgrade to be excited about. For review, it's more of a tradeoff. While it generates cleaner, sharper comments, it catches fewer bugs than the earlier models we currently run in production, and comes at a slightly higher cost per review.
The good part is that you can tune most of that, and for a lot of teams the move is well worth making. Let's walk though what's new in Sonnet 5, how it performs writing and reviewing code, and if it makes sense to switch.
Sonnet 5 thinks more deeply than the version before it. For you, that means it works through harder problems the old model would have given up on.
The thinking "effort" dial in Sonnet 5 that allows you to incrementally turn it down to off if you don't need it. This is the feature that protects your budget. Turn the effort up for a tricky review where a missed bug is expensive, and turn it down or off for routine work where you'd rather not pay for deep thinking.
It can also rewrite its own instructions partway through a task. On long agent jobs, the goal tends to shift as the model learns more, and a model stuck on its first plan will keep pushing on instructions that no longer fit. Sonnet 5 updates its own plan instead, so you get fewer runs that wander off and burn your time and tokens.
It also ships with new safety guardrails around security and cyber topics. The upside is fewer risky outputs. The catch is that real security work can trip the filters now and then, so expect the odd refusal if that's your area.

The easiest way to picture Sonnet 5 is as a mid-level engineer who cares, maybe a little too much, about shipping code that truly works and runs at the level you asked for. That one trait shapes most of what it does, and it showed up in four habits we saw again and again:
Sonnet 5’s code writing is the main reason we think most teams will want to upgrade. Before we get to the review numbers, it is helpful to see how it behaves when it builds something from scratch. We handed it the work we do daily, from quick features to harder problems with no clear path.
One evening, we gave it a tough task and stepped out for lunch. The job asked the model to write the code, run simulations on it, and keep tuning the output until the results were as good as possible. We came back expecting it to be done or stuck. Neither were true. The model was still going, working through the problem on its own, with no nudging from us.
It built the whole application by itself. The reason it ran so long was simple. It kept cleaning up its own solution, pass after pass, because it was chasing the best answer instead of the first one that happened to work. That's the kind of thing that was previously only available with a pricier model, and watching a mid-tier model do it is a real moment.
That aforementioned diligence is exactly why Sonnet 5 is good at long, open-ended work. The slowness that bugs you on a one-line change turns into a strength when the job has no set number of steps. It's a great fit for agent loops, where you hand the model a simple goal and let it spend a few rounds trying approaches, testing them, and improving the result on its own before it reports back.
Anthropic's own guide to building effective agents calls this an evaluator loop, where the model writes a result and then critiques and improves it in a cycle. It's worth a read if you're building that kind of workflow. Sonnet 5 has that loop wired into how it thinks, and if you've been holding off on agentic coding because earlier models drifted or gave up, this is the release that changes that.
Most models treat tests as a chore for later, Sonnet 4.6 included. Sonnet 5 tends to write the tests first, builds the feature on top of them, and then runs everything once it thinks it's done. The self-checking we saw comes straight out of that order. You can't spot a clash between your tests and your code if you never run the tests, and this model always runs them. If you've ever shipped code that looked fine and broke a week later, you'll feel that difference fast.
The extra care Sonnet 5 takes shows up in your file count and token use. Ask for something small and you get a lot back. You'll see extra helpers and a test file longer than the feature itself. On a big feature that looks like good engineering. On a one-line change it looks like a model that can't help itself.
We found Sonnet 5 to be slower than Sonnet 4.6, which is likely due to the extra thinking Sonnet 5 performs. You're trading minutes for thoroughness, which pays off on long jobs you leave running. It does sting when you're waiting on a small change. Where 4.6 hands back a quick answer, 5 keeps working for a better one, and you feel that most on the little stuff. Two smaller notes: It uses more tokens than 4.6 did, and is still clear, just chattier. It also writes good plans, then rewrites them mid-task more often than we'd like. None of this is a dealbreaker for build work, but it's worth knowing before you point it at a pile of tiny edits.
This is the part we care about most, since reviewing code at scale is what we do. AI now writes a big share of the code many teams ship, and that code needs a careful second pair of eyes. Our look at 470 open-source pull requests found that AI-co-authored PRs carry about 1.7 times more issues than human-only PRs, and one 2025 study found review time climbed 91% on teams leaning hard on AI. The model doing the reviewing is now a big factor in how fast teams ship.
We added Sonnet 5 to our harness and pointed it at our standard benchmark, a fixed set of pull requests with known bugs, and measured how many it caught and how clean its comments were. You can read more about how we build these reviews in our piece on context engineering for AI code reviews.
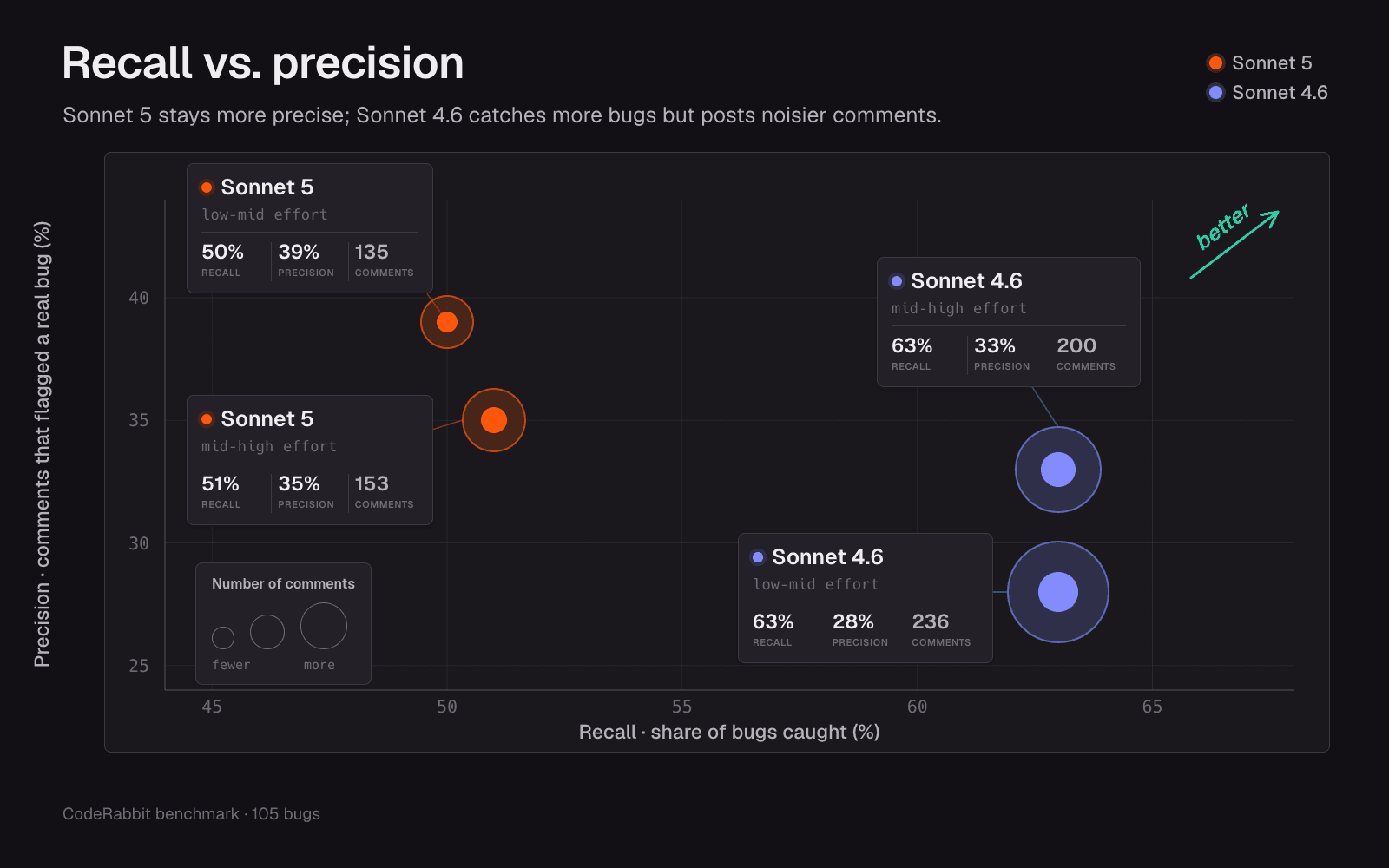
Sonnet 5's comments are cleaner and its findings were more often bugs than noise. On our benchmark, precision climbed from about 29% with Sonnet 4.6 to roughly 38% to 40%. Sonnet 4.6 does the opposite. It comments on almost everything and leaves you to pick the keepers out of the clutter. If you've ever turned a reviewer off because it flagged every little thing, you already know how important it is to highlight what needs your attention..
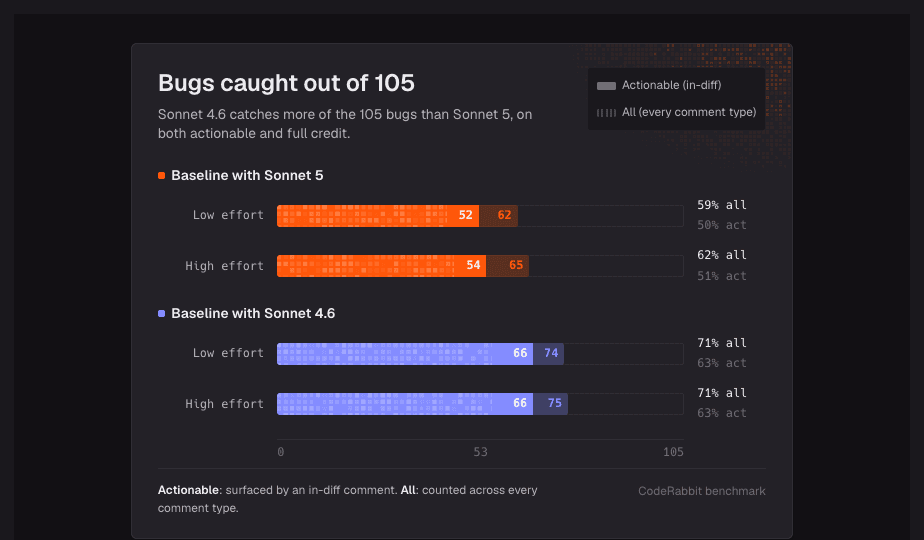
Inside our review harness, Sonnet 5 catches fewer bugs than our current production setup. On the strict "did it find the bug" measure, our baseline catches about 57%, and Sonnet 5 lands around 50 to 51%. What surprised us was that Sonnet 4.6 caught more than either of them, around 63%, even though it's a noisier reviewer. So the model that buries you in comments was also the one that missed the fewest bugs. Turning Sonnet 5's effort dial up barely moved its score and roughly doubled the cost. On a looser score that counts more types and variations of comments, high effort brought its findings back to about even with the current baseline, but it didn't pull clearly ahead.
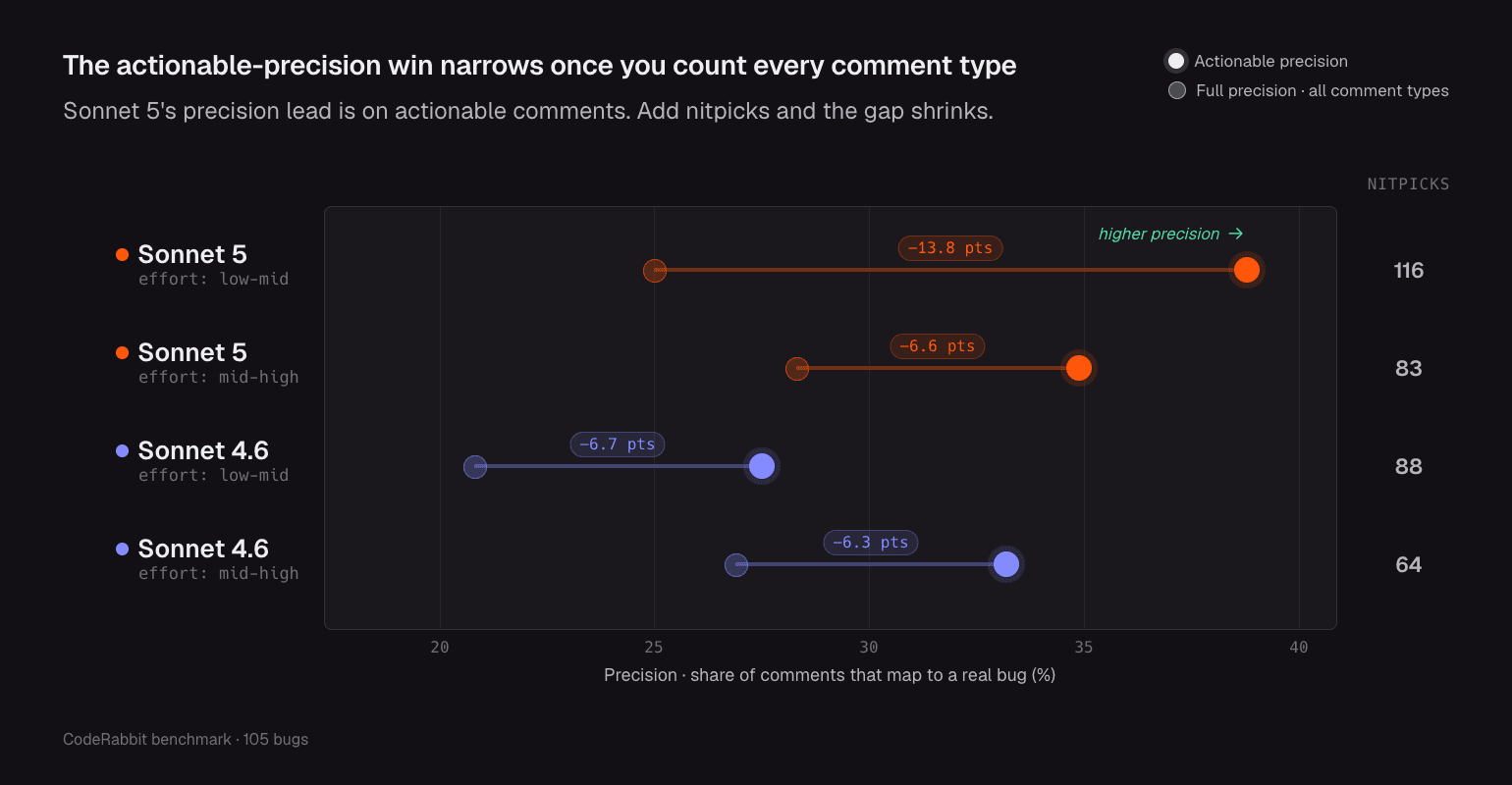
There's a bit of noise hiding in the comments too. Sonnet 5 posts three to four times more nitpicks than our baseline and almost 80% more than Sonnet 4.6 in high effort runs. Its best comments read cleaner, but you have to look past more minor ones to find them. We also tried it with thinking turned off. On some jobs it matched our baseline, on others it slipped a little. So there's a class of lighter review work you can run cheap with thinking off and lose almost nothing, as long as it isn't your most important code. The takeaway isn't that Sonnet 5 is a weak reviewer. It's actually a quieter, more careful one, and for teams drowning in review noise, that's often the better trade.
Reach for Sonnet 4.6 when raw coverage is what you need and you've got the bandwidth to wade through its comments. Reach for Sonnet 5 when you'd rather get fewer, sharper comments and a much stronger partner for actually writing code. Sonnet 4.6 finds a few more bugs, while Sonnet 5 wastes far less of your attention.
Against flagship models, like the Opus family that teams keep for their hardest jobs, Sonnet 5 does nearly as well on review quality for a lot less money. If you're paying flagship rates today only because nothing cheaper was good enough, Sonnet 5 is worth a look. Keep an eye on the token bill while you test, because a model that thinks this much can eat into its own savings. Cranking the effort to maximum was the worst deal of the bunch. It roughly doubled the cost without finding meaningfully more bugs, so don't reach for the top tier by default. We saw the same pattern when we reviewed what Claude Opus 4.7 means for AI code review.
For most teams, the answer is yes. Sonnet 5 is the most exciting coding model we've used in its class. It works like a careful teammate, the kind who would rather take an extra few minutes than hand you something that breaks later, and that instinct makes it a clear step up from 4.6 for anyone doing real building work.
In plain terms: switch now if you write or ship real software and want a model that tests its own work and sticks with a hard problem until it's solved. Run it at medium effort and you get most of the upside without the top-tier price. And if you're paying flagship rates purely for quality, line Sonnet 5 up against your current model before the next renewal, since it may match the work for a fraction of the spend.
The one group that should wait is high-volume teams with tight latency budgets and lots of tiny diffs. That's the workflow where its slower, more careful style doesn't earn its keep yet.
It isn't perfect, and we've been upfront about where it lags on review. But its strengths in writing and reviewing code outweigh that easily. If you've been waiting for a reason to upgrade, this is it.
Want the full picture on AI-generated code quality? Read our State of AI vs Human Code Generation report, see how teams are actually using AI dev tools, or try CodeRabbit free in your IDE.



