
CodeRabbit is now in the Claude Marketplace!Learn more


Juan Pablo Flores
Gowtham Kishore Vijay
May 28, 2026
6 min read
May 28, 2026
6 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Anthropic just shipped Opus 4.8. Before its release, we spent some time putting it through its paces, most of it on code review tasks. We ran it against our standard evaluation harness, watched how it behaves on real pull requests, and probed where it holds up and where it strains. Alongside that, we used it for the kind of long-running coding work that tends to break agents before they finish.
On review, it lands at parity with some of our tuned production ensemble. The surprise was how much it pulled ahead on code generation and long-horizon agentic sessions.
Three things actually shipped, and everything else is downstream:
{"role": "system", ...} entries mid-conversation without invalidating prompt caches. The model follows them most reliably as context rather than overrides. It also narrates its plan, second-guesses, and requests more permission than prior Opus versions, all useful behaviors, but ones that require active budgeting and steering.On code review, it lands at parity, with an actionable pass rate of 61% vs 62%, and full-system 72% vs 68% at unchanged precision. But the comment mix shifts and critical findings dipped (35 to 29), which gives us pause. In our “Results” section below, we dig into why, and whether it is recoverable.
CodeRabbit is integrating it selectively where its strengths fit, and routing other models that win on cost without sacrificing quality or pass rate.
We ran Opus 4.8 through the same harness we use for every model release: 100 open-source pull requests sampled across trivial, minor, and major complexity tiers. We compared two thinking configurations (a default escalating medium/high/x-high by tier, and a lower-thinking variant running low/medium/high) against a baseline running our current production model mix on the same PRs.
Two metrics drive the analysis: pass rate (the fraction of PRs on which the model surfaced the equivalent of what a senior human reviewer would flag) and precision (the fraction of comments that were actionable rather than noise). "Actionable" is adjudicated by senior reviewers.
The default Opus 4.8 config edges past our baseline on full-system pass rate (+4pp, 72% vs 68%) and sits within noise on actionable pass rate (61% vs 62%). Precision holds at 33.8% on actionable comments and ticks up a point on the full system.
For a model going head to head with a tuned ensemble on a surface it was not specifically optimized for, that is a strong result, and the cross-file reasoning is clearest on senior-tier PRs.
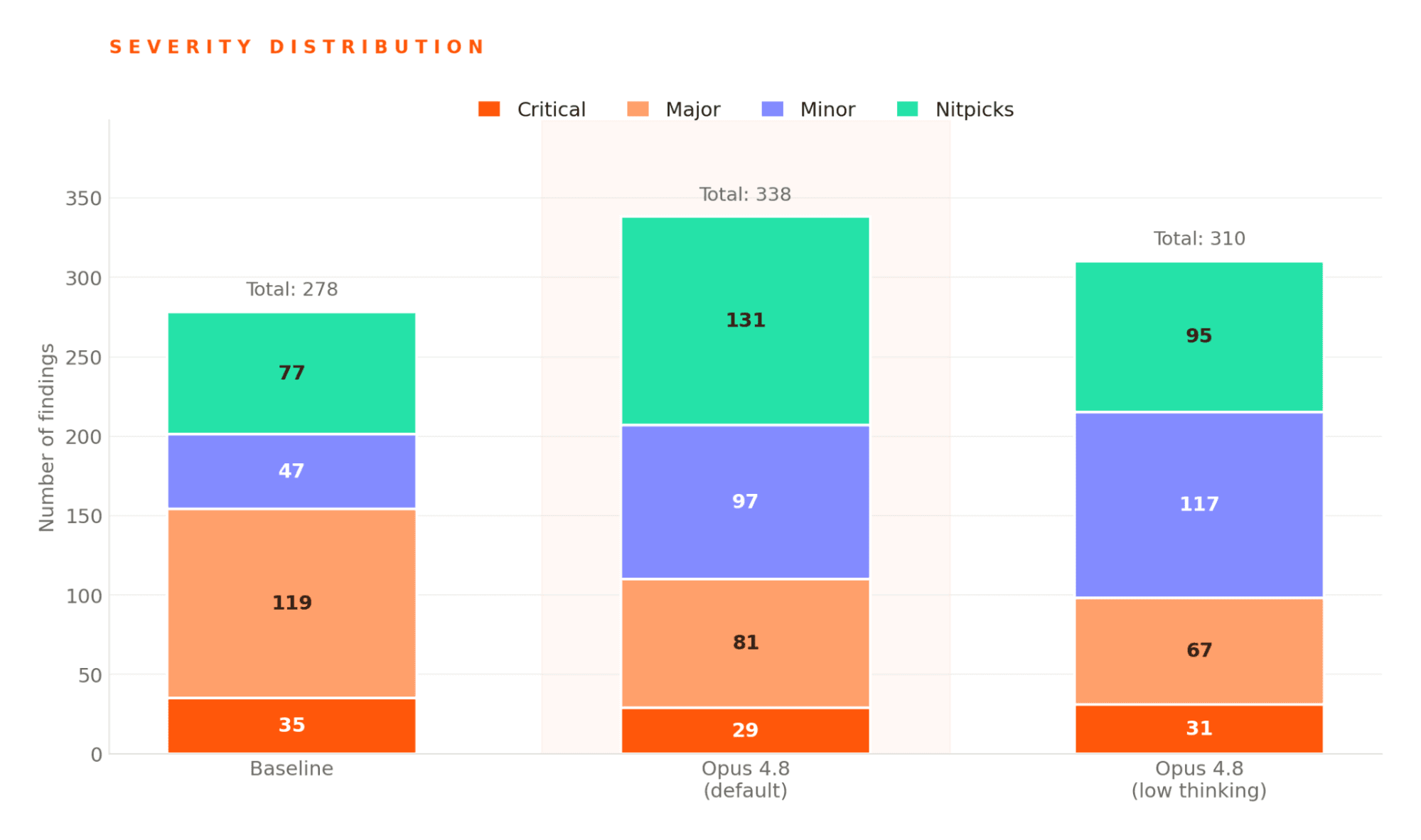

The comment mix is noisier than baseline, however. Major findings drop from 119 to 81, while minor and nitpick findings both roughly double. The model is shifting volume from the middle of the severity range toward the bottom.
The one result that gives us pause is critical findings, which fell from 35 to 29. For a code-review tool, missed criticals matter more than any other category of finding. Our working explanation is that Opus 4.8 follows review instructions literally. Consequently, conservative prompts ("only report high-severity issues") suppress recall more than they did with prior models, and that the higher-severity bug-finding capacity is real once the model is allowed to report broadly and we filter downstream rather than constraining at the source.
The lower-thinking variant tells a useful secondary story. Cutting reasoning effort drops precision four points and actionable pass rate five points. Thinking level is a first-class configuration decision.
We also found the default config costs more. We measured $0.20 to $0.28 per call against roughly $0.13 for Opus 4.5 and $0.04 to $0.12 for Sonnet 4.5. On code review alone, the model is at parity, making the premium hard to justify for review-only use. What earns its value is on long-horizon agentic and code-generation work below. That cost-versus-surface tradeoff is exactly why we route it selectively rather than everywhere.
Performance degrades visibly once context crosses 200k tokens. The model slows and starts to miss references and edge cases it would have caught cleanly at lower context windows. This is an observational finding from hands-on use, not a controlled measurement. CodeRabbit's context engine works around this, but teams using Opus 4.8 directly will hit a wall in monorepos and large codebases.
We are integrating Opus 4.8 selectively. Its strengths (cross-file reasoning, long-horizon agentic quality, planning under a single up-front spec) show up most on senior-tier changes. So that is where you will see it engaged. For trivial and junior-tier PRs, we continue routing to the models that win on cost and pass rate at those tiers. For our agentic features, we expect Opus 4.8 to be the strongest backbone we have integrated.
If you run Opus 4.8 directly, most existing Opus prompts work without modification. A few tune-ups produced measurable differences in our testing. Start at "high" thinking rather than "x-high" and test across tiers. Front-load the full task context for long-horizon work. Add an explicit search-first or delegation instruction to recover depth on research-heavy work. Drop conservative language from review prompts and filter downstream instead. Name the small decisions the model can make on its own.
We will keep evaluating as the model and our harness change. If the picture shifts, we will publish updated numbers.



