Juan Pablo Flores
Gowtham Kishore Vijay
June 09, 2026
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GetStarted in2 clicks.
Fable 5 is worth testing for autonomous coding work, especially when the prompt is incomplete and the agent has to discover the environment before it can build. For production code review, the current baseline and Opus 4.8 still look safer.
Fable 5 is the kind of model that changes how an agent feels when the task is underspecified. It directs exploration well: first learning the environment, then identifying what files, tools, and constraints are available, then building from that grounded picture. It does not spend much time narrating what it is about to do. If it has enough context, it starts building.
We saw that across multiple coding projects we used to test the model's capabilities. We could give Fable 5 vague prompts and still get complete projects rather than prototype shells. It also found solution paths that felt less obvious, including approaches that earlier model reviews struggled to reach without more hand-holding.
The same behavior also shows up as a cost. In our coding task benchmark, Fable 5 often kept working until the harness cut it off. That makes the model feel capable, but it also makes it expensive and slower in agent workflows that do not have strong stop rules.
So the recommendation is not a clean "switch everything." It is: use Fable 5 where autonomy is the product, keep the current code review path while precision and comment volume are tuned.
Use Fable 5 when the job is to explore, plan, and build, especially when the task can take longer in exchange for a more thorough implementation. Keep the current reviewer in place for now. The code-review signal is close on coverage, but not yet strong enough on precision or volume to become the default.
Fable 5 is positioned as a Mythos-class model for autonomous knowledge work and coding, which sets a different bar than a routine model upgrade. The promise is not just better answers or a faster Opus 4.8. It is a model built for longer-running agent work: holding more context, making a plan, and carrying the task further before it needs a human to step in.
The launch constraints are still important to the capability story. The model includes blocking classifiers for some cybersecurity and biology requests, and the product supports opt-in fallback to Opus 4.8 after classifier blocks. For developers, the practical takeaway is simple: use Fable 5 when the task needs depth, and keep the existing path for workflows that need predictable speed or precision.
The public launch price in the release brief is $10 per million input tokens and $50 per million output tokens, with a 10 percent surcharge on regional endpoints. We have seen prices like this before from reasoning models, especially when they introduce a new model category. Those costs may come down over future iterations, but the early picture is clear: developers should evaluate Fable 5 by cost per solved task, not just by token price.
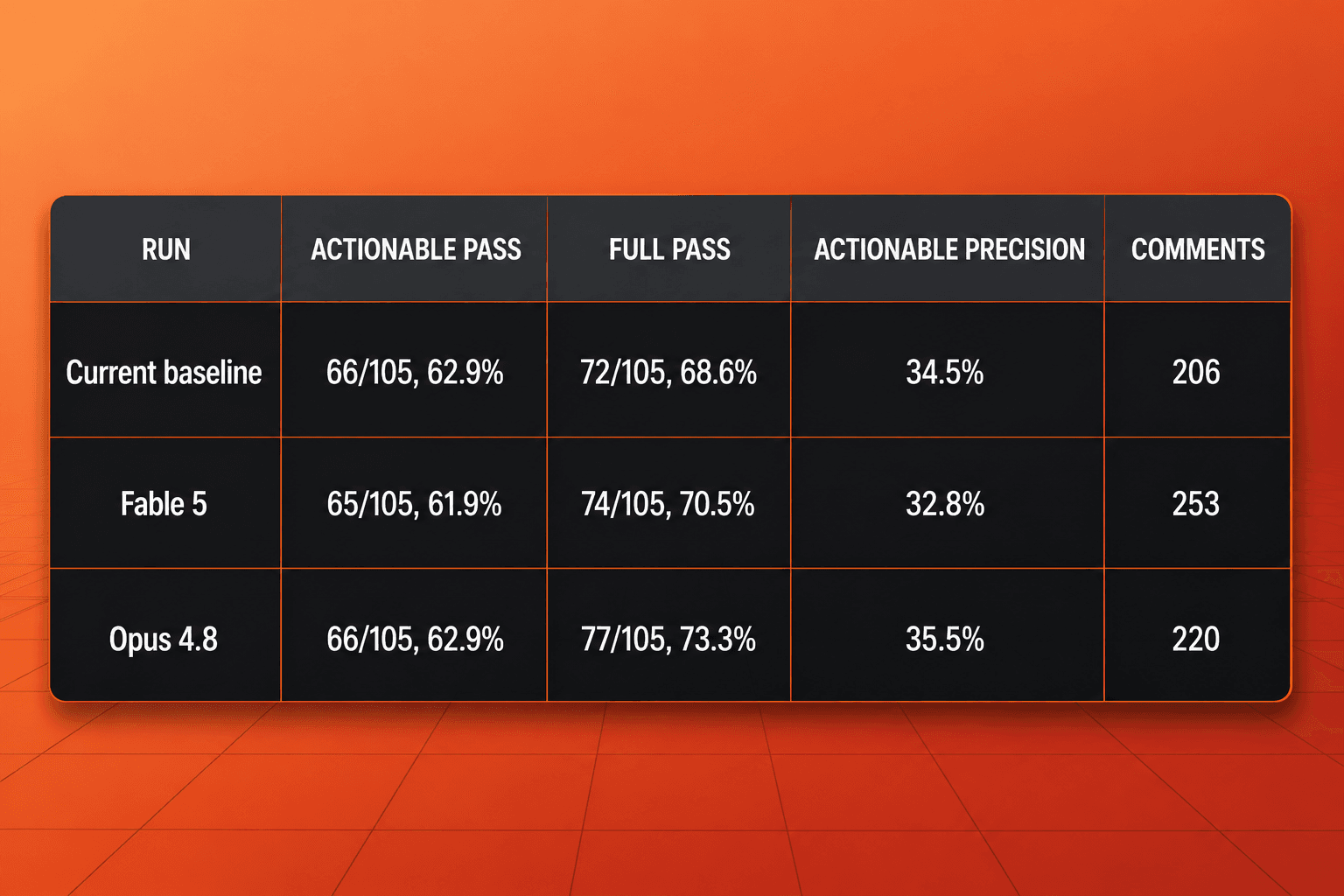
In the 105-EP code review benchmark, Fable 5 stayed close to the current baseline on finding coverage. It passed 65 of 105 actionable EPs, just behind the baseline and Opus 4.8 at 66 of 105. If every comment type is counted, Fable 5 slightly beat the baseline, with 74 of 105 full EP passes versus 72 of 105.
The weaker part is precision. Fable 5 landed at 32.8 percent actionable precision and 19.4 percent full precision, while Opus 4.8 reached 35.5 percent and 26.5 percent. It also produced 253 comments, more than either comparison run, with a large increase in assertive and nitpick-style output. That combination matters for code review because noisy comments create reviewer work even when coverage looks competitive.
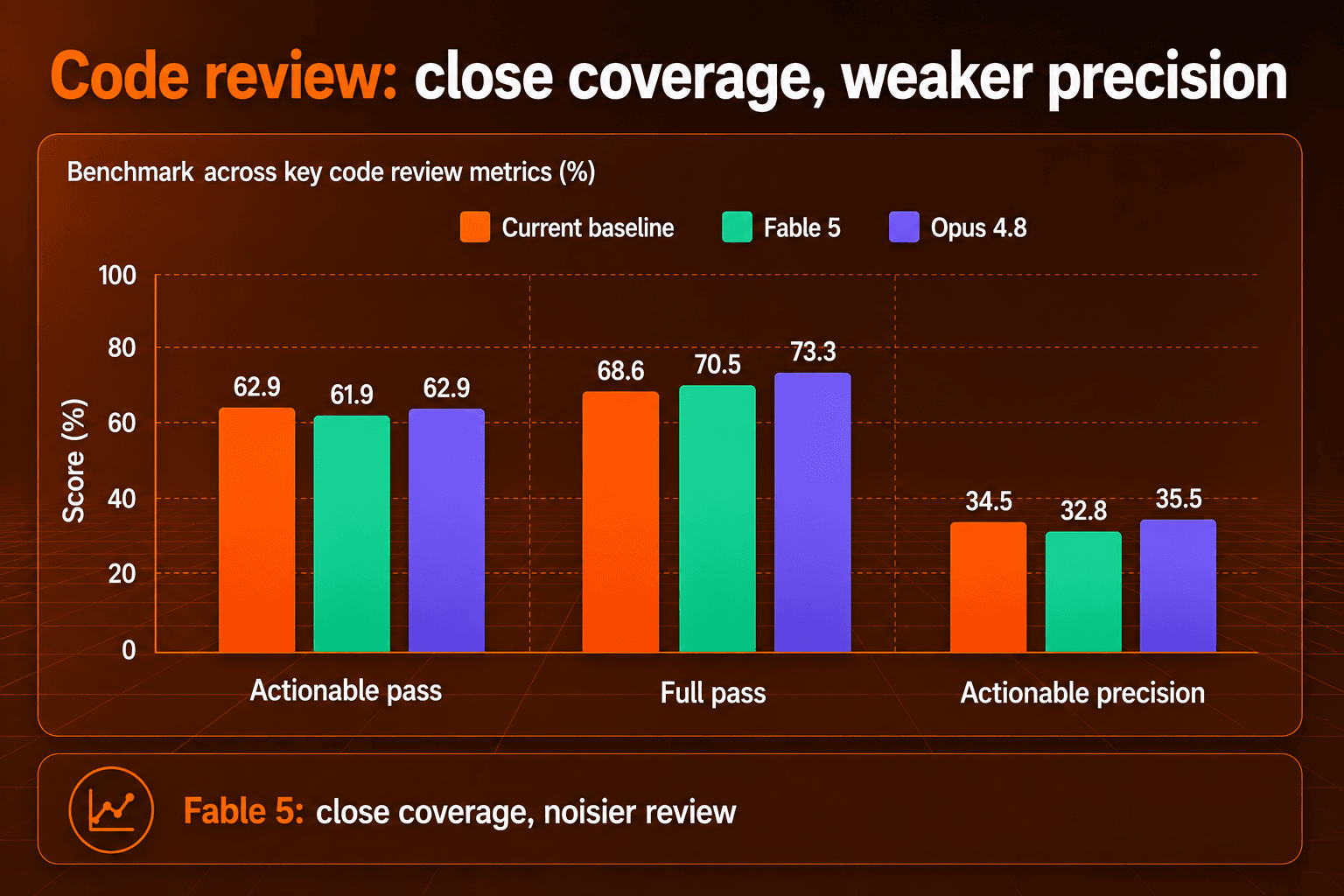
The category breakdown makes the result feel more uneven than the headline coverage number suggests. Fable 5 has useful breadth, but the gains are not consistent across the kinds of issues developers expect a reviewer to catch. In practice, teams should expect helpful findings, while still needing manual triage and fallback coverage for categories where review trust is harder to earn.
The harder examples make the rollout case more cautious. On difficulty 4 EPs, Fable 5 passed 8 of 16, behind the baseline at 10 of 16 and Opus 4.8 at 9 of 16. That does not make Fable 5 a poor reviewer, but it does mean developers should expect more human judgment on the cases where review trust is hardest to earn.
Developers are likely to experience Fable 5 as more security-aware than a generic coding model, especially when the task asks for careful implementation around risky behavior. That does not mean it should be treated as a drop-in security reviewer. The practical posture is to use it for deeper security-sensitive coding work, then keep the review bar high before trusting the findings.
The strongest security signal came from active implementation. In our coding task benchmark, Fable 5 completed a security-relevant Bandit task when it had a clear objective and enough time to work through the code. Fable 5 looks more useful when security is part of a concrete coding task than when it is asked to catch every issue in review.
We stopped the coding task benchmark early after a clear pattern emerged: Fable 5 could make meaningful progress, but many tasks ran long enough to hit the agent timeout. That makes this section an experience signal, not a final leaderboard score. The useful story is how the model behaves on real coding work when the task keeps expanding.
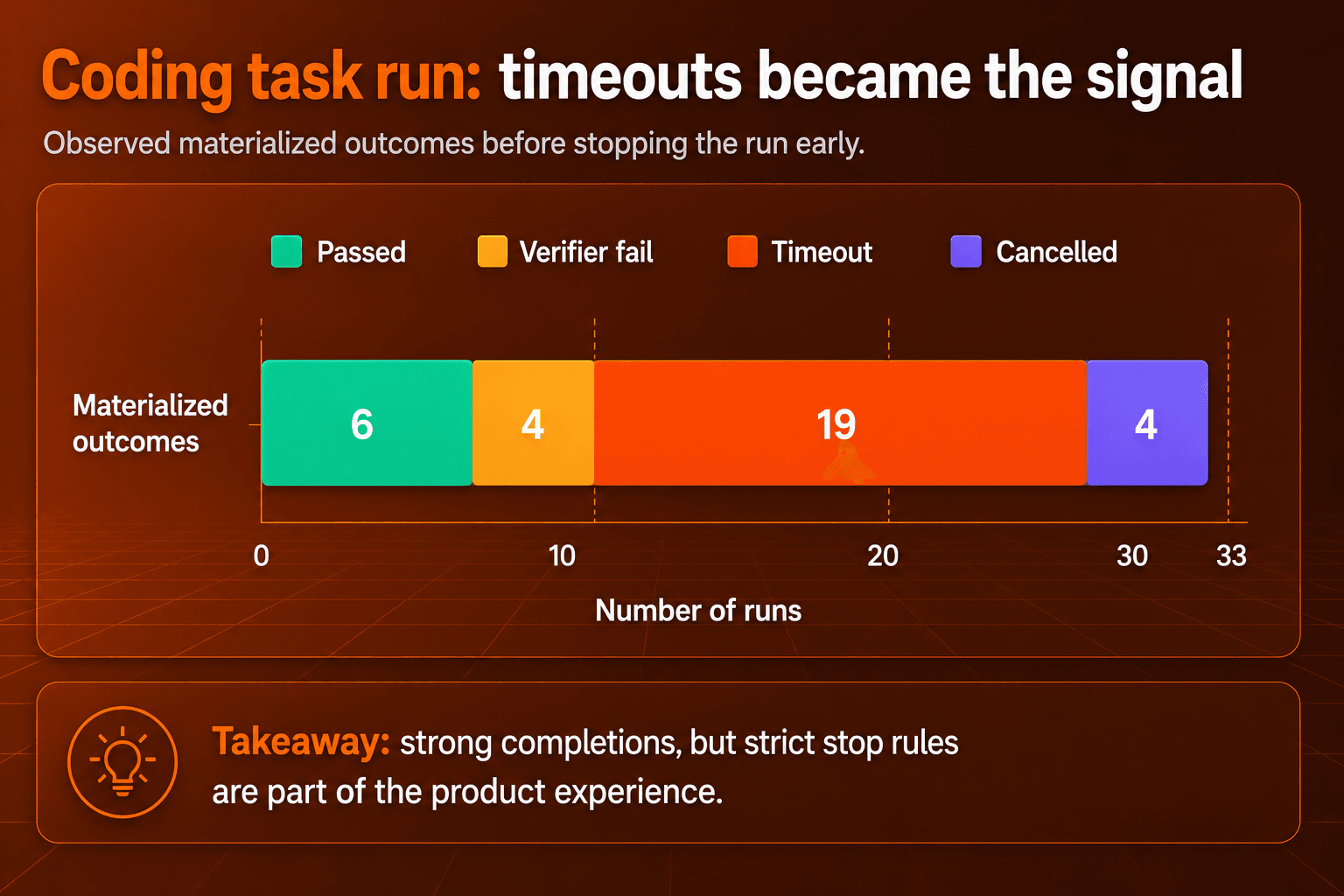
The outcome mix should be read as a signal about agent behavior, not as a completed benchmark score.
The signal cuts both ways. When Fable 5 finished, it produced serious patches rather than shallow edits. When it struggled, it kept exploring longer than the harness could support. For developers, that makes it a better fit for work where depth is worth the wait, provided the agent has clear limits on time, steps, and tokens.
The completed tasks also suggest where Fable 5 is most useful. The wins came from implementation work with real structure: types, APIs, publishing behavior, query logic, caching, and security-relevant code. The misses were useful too. Some were quick wrong turns, while others showed the model investing real effort without converging. That is the tradeoff developers should plan for: more depth, but not always a clean finish.
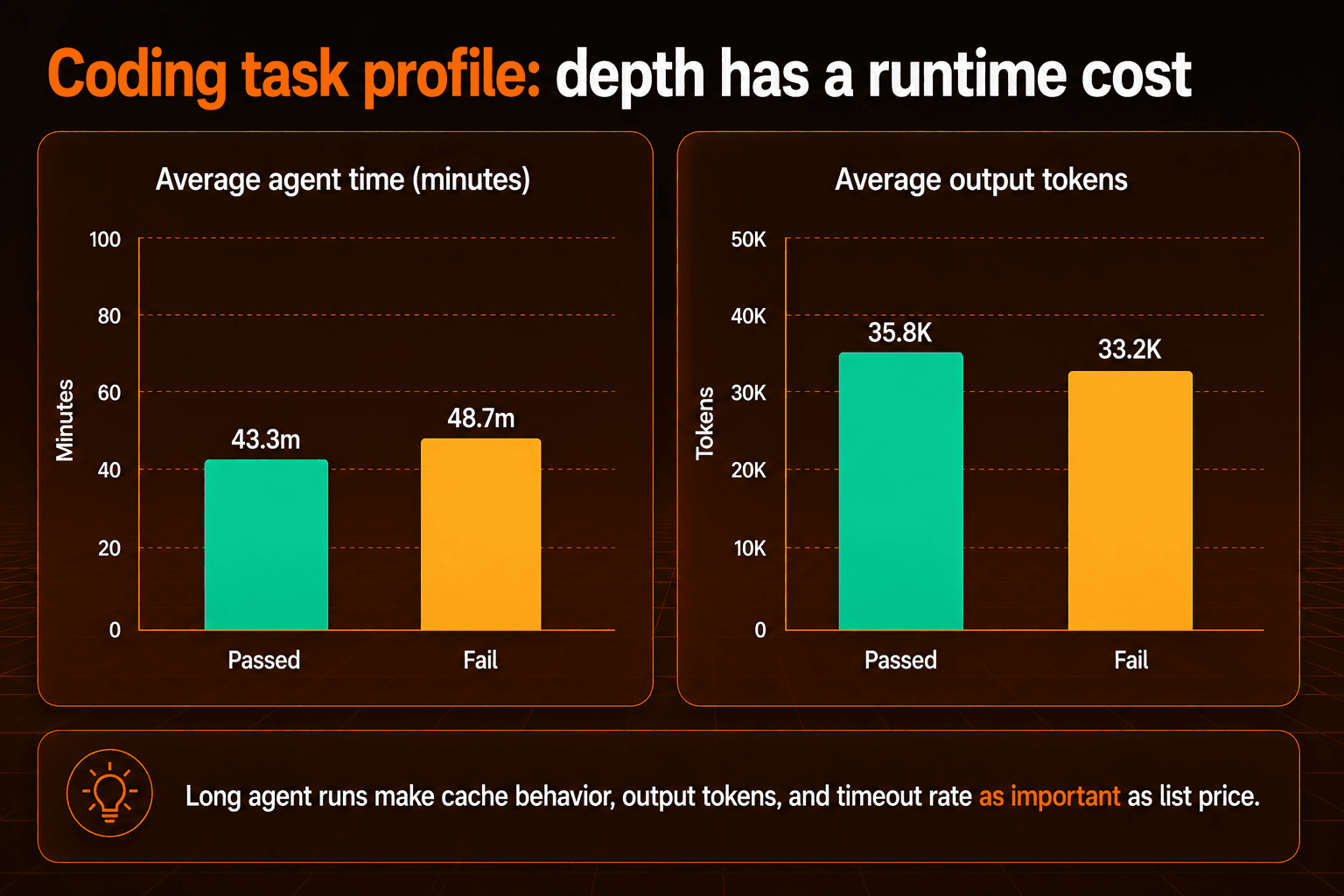
Fable 5 spends real time and output budget when it finishes. When it times out, the harness can still burn substantial context.
The token profile tells the same story as the timing data. Fable 5 does not just cost more because of list price. It can also spend longer thinking, exploring, and generating before it reaches an answer. Cache discounts may reduce the final bill, and prices may come down over future iterations, but teams should still evaluate the model by cost per solved task. For this kind of agent work, timeout rate, cache behavior, and output token usage matter as much as the published token price.
The coding projects gave the clearest view of Fable 5 at its best. In one project, the model did more than assemble a working surface. It organized the implementation into separate layers for state, decision-making, rendering, and controls, then produced a build that passed. The remaining gaps were the kind you would expect from a first complete version: more robust test coverage, safer state handling, and stricter guards around invalid inputs.
Another project showed the same pattern in a more interactive setting. Fable 5 built a working real-time application with a stable loop, procedural visuals, stateful interactions, phase changes, canvas effects, multiple app states, and a successful production build. The issues were not basic completion failures. They were the next layer of engineering work: deterministic tests, small-screen polish, and state edge cases.
This is the clearest qualitative difference from earlier model reviews. With enough context, Fable 5 moves directly into implementation instead of over-explaining the plan or repeatedly asking for permission. It also seems to spend more effort on architecture, interactions, and product shape than a narrower code-completion model would.The recommendation is selective adoption. Fable 5 is worth testing for autonomous coding work, especially tasks that benefit from deeper planning, multi-file execution, and extra time spent on implementation. I would not make it the default for production code review yet.
For code review, keep the current baseline or Opus 4.8 path as the default until Fable 5 improves on precision and comment volume. For coding agents, Fable 5 is more compelling, especially when the work benefits from exploration and deeper implementation. The guardrail is operational: give it clear budgets, stop conditions, and review checkpoints. For security workflows, position it as useful for security-sensitive implementation, not as proof of better security review.