
Atsushi Nakatsugawa
May 12, 2026
1 min read
Nobody Is Going to Read the Code | CodeRabbitの意訳です。
私の立場からすると言いにくいことですが、あえて言わせてください。AIコーディングツールは、正しいコードを生成する能力という点で、いまだに人間に大きく劣っています。そもそも人間のコードもけっして優秀とは言えませんでした。AIが人間と同水準に達したかというと、まだそこには至っていません。むしろ間違った方向に大きく踏み出してしまっている状況です。
だからといって、AIコーディングツールを使うのをやめろという話ではありません。これから何が起きるのかを、正直に見据えるべきだ、ということです。
私の予測はこうです。今後12か月のうちに、ほとんどの開発者はもうコードそのものを見なくなります。その理由をお話しします。
人間によるコードレビューは、もう何年も前から限界に近づいていました。私自身、かつてはレビューに業務時間の20〜30%を費やしていたものです。当時もそれは多すぎると感じていましたし、長く続けられるやり方ではありませんでした。そこにAIがアシストする開発スタイルが入ってきて、レビューに費やせる時間は変わらないまま、流れ込んでくるコード量だけが一気に増えました。もともとあったプレッシャーが、いま深刻な水準にまで達しています。
ここまでの話は、すでにあちこちで語られてきました。ただ、まだきちんと語られていないのは、AIが持ち込む問題が、なぜ人間のレビュアーが構造的に見落としやすい性質のものなのか、そしてその「ミスマッチ」こそが、なぜ来年中に人間のレビューを「きつい」ではなく「成り立たない」ものにするのか、という点です。
データを見ると、これは具体的かつ直視しづらい話になります。
CodeRabbitのState of AI vs. Human Code Generation Reportでは、オープンソースのGitHubプルリクエスト470件を分析しています。それによれば、ロジックや正しさに関する問題は、AIによるPRで人間のPRより75%多く発生しています。エラーや例外処理のハンドリングの抜けは、ほぼ2倍です。これらは障害を引き起こす類の不具合であり、ロジックエラーは修正コストが特に高く、後段でインシデントを引き起こす可能性も高い問題です。これを見つけるには、レビュアーが正常系の流れからいったん意識を外し、自分が書いたわけでもなく、十分に理解していないかもしれないコードについて、あらゆるエッジケースを頭の中でたどる必要があります。
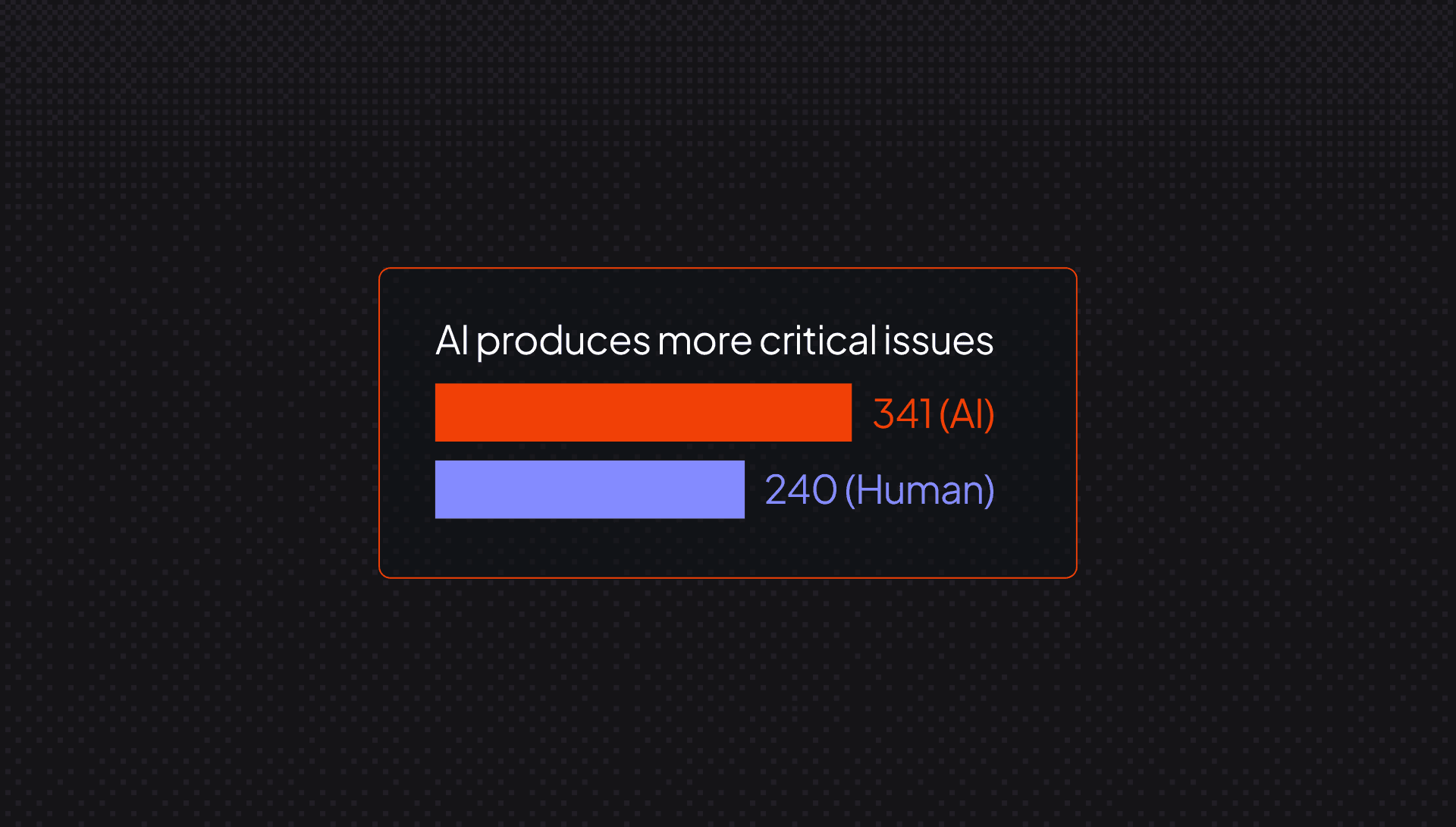
セキュリティの問題はこれにさらに拍車をかけます。AIのPRでは、人間のPRと比べてセキュリティ上の問題が最大2.74倍にのぼります。よく見られるパターンは、パスワードの扱いが適切でなかったり、不適切なオブジェクト参照(insecure object reference)だったりするものです。これらは、ひと目で気づけるバグではありません。発見するには、攻撃者の視点で考え、「これは動くか?」ではなく「これは悪用できるか?」と問う必要があります。これはまったく別種の思考モードであり、ましてや自分が書いたわけでもない巨大な差分を相手に、それを安定して維持できるレビュアーはそう多くありません。
加えて、すべてをいっそう悪化させる「読みやすさの問題」もあります。AIが生成したコードは、可読性に関する問題が人間のコードの3倍以上発生しています。なぜなら、見た目はきれいなのに、ローカルなコーディング規約や構造をひそかに破っているからです。レポートの表現を借りれば、AIが生み出すコードは「一見すると一貫しているように見えるのに、命名・明確さ・構造といったローカルなパターンを破っている」ことが多いのです。これはレビュー観点では最悪の部類に入ります。コードはざっと読むぶんには問題なさそうに見えるのに、本当の問題に気づくには、そのコードベースに対する深い理解が必要だからです。
そして、AIによるコード生成を多用していると、目の前のコードに至るまでに、どんな判断が下されたのか自分でもまったく把握できていない、ということが本当に起こり得ます。理由づけは不透明です。レビュアーが見ているのは、思考過程ではなく出力結果だけです。どこを見ればいいかすらわかりません。なぜなら、判断がどこで行われたかを知らないからです。
AIとコード品質をめぐる議論は、たいていここで止まってしまいます。でも、議論はまったく別の方向へ進む必要があると私は考えています。
これから12か月のあいだに起きるであろうと私が見ているのは、検証の重点が「コードを読むこと」から「意図どおりかを確かめること」へ移ることです。自分がやらせたかったことは、実際に起きているのか。プロンプトで指示した通りの挙動になっているか。これらは答えを出せる問いであり、ばらまかれたExceptionハンドラを差分の隅々まで読み解かなくても確認できる類のものです。
実際にコードを読む層は、自動化されていきます。AIコードレビュー、静的解析、セキュリティ向けのLint、必須のテストカバレッジなどです。これらはその場しのぎではありません。すでにこの方向で動き出している組織は、自動レビューを任意の追加レイヤーではなく、構造上の必須要件として扱っています。出力が意図と合っているかをチェックする検証パイプラインを構築しているのです。「このコードは正しそうに見えるか」を議論することはもうしていません。そもそも、自分たちはコードを見る側ではない、と受け入れているからです。
私がお話しするAIコード生成を使っている企業はどこも、自社の内側で何が起きているかを肌で感じています。最初の興奮は本物でした。スピードの向上も本物でした。そして、しばらく経った後にやってくる現実もまた、紛れもない現実です。その現実とは、PRのrevertが続き、原因の特定が難しいバグを追いかけ、もっと早い段階で捕まえるべきだったものを後追いで直し続ける日々です。
本当に正しいコードを生成するためにモデルが同時に保持すべきコンテキストの量を考えると、完璧な出力という問題を短期間で解決するのは難しい話です。これらのシステムは、当面は問題を生み出し続けます。私たちはAIを使ってコードを書き続けます。もう抜けられないからです。そうなると次に問うべきは、AIが間違えたものを本番環境に届く前に捕まえるためのインフラを自分たちは持っているか、という問題です。たいていのチームは、そのインフラを持っていません。そして、AIのスピードと、その出力を検証できる能力との間にあるギャップは、開く一方です。

10,000行のPRを、100行のPRと同じやり方でレビューすることはできません。誰にも無理です。エンジニアリング組織がそれを早く受け入れ、それに合わせて仕組みを作るほど、人間によるレビューモデルが完全に破綻するそのとき(来るかどうかではなく、いつ来るかの問題です)に、より有利な立場に立てます。
コードはこれからも流れ込んできます。問われているのは、そのコードと本番環境とのあいだに何を据えるか、ということです。


