

Atsushi Nakatsugawa
May 08, 2026
2 min read
Do you trust your AI Agent?の意訳です。
説明可能性こそが、AIエージェントが現実の問題解決に使われるか、それとも重要度の低い社内タスクのお供にとどまるかを分けます。
1年前、エージェント型AIが登場し、誰もが衝撃を受けました。LLMはチャットツールから、実際にあなたの代わりに「物事をやってくれる」存在へと変わったのです。しかしエージェントが当たり前になった今、より厄介な課題に直面しています。それは「信頼を勝ち取ること」です。
エージェントはいくらでも「自律的」と謳えます。けれども、自分のステークホルダー(マネージャー、顧客、監査チームなど)に対して、エージェントが「何を」「なぜ」やったのかを説明できないのなら、その自律性に大した価値はありません。
エージェントが本気の仕事に使われるか、それとも重要度の低いタスクの脇役にとどまり続けるか。それを分けるのは、たった1つのことです。「人がそれを本当に理解できるかどうか」です。
まず、「説明可能性(explainability)」と「観測可能性(observability)」を区別しておきましょう。両者はしばしば(誤って)同じ意味で使われています。
観測可能性は「何が起きたか」に関するものです。アクション、ツール呼び出し、入力、出力、分岐パスといった、機械的な記録のことです。これは主にエンジニアリングの問題で、すでにかなり解決されています。構造化ログを構築できますし、課題はそうしたログをスケールしたときに有用な状態に保つことです。
説明可能性は「なぜ起きたか」に関するものです。エージェントが意思決定に至った推論、検討して却下した代替案、どの程度の確信度を持っていたか、といったことを理解することです。こちらはより難しく、まだ完全には解かれていない問題です。
そして、以下のいずれかに当てはまる場合、エージェントは自身の振る舞いをさらに説明する必要があります。
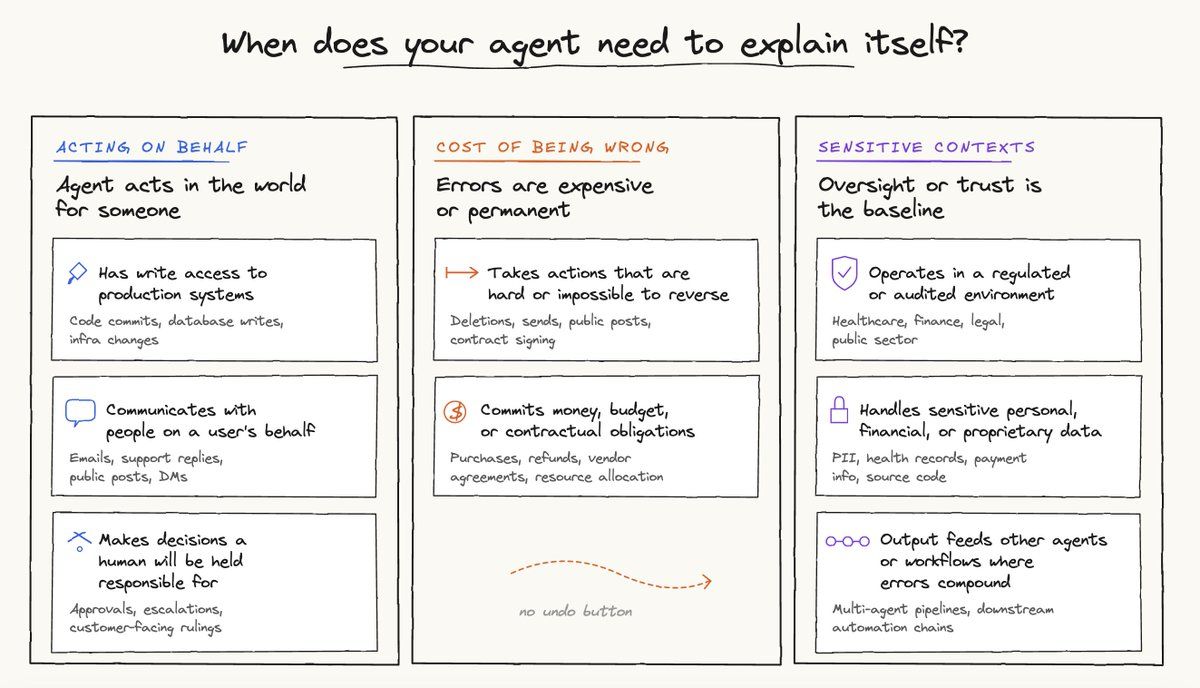
こうした状況でエージェントが自分の振る舞いを説明できないと、「信頼の負債」が積み上がります。
これは、エージェント開発に取り組むチームならよく知っている古典的な例です。インシデントが発生し、開発者がエージェントの動作をデバッグしようとします。ログを開いてみると、エージェントはXを依頼されていたはずなのに、YとZもやっていたことがわかります。タイムラインを組み立て、根本原因を突き止めようとします。しかし、エージェントの行動から実世界の結果に至る経路は不明瞭で、その行動の背後にある推論も見えてきません。
この信頼コストは静かに、しかし確実に積み上がります。ユーザーがエージェントの動きを理解できなくなった瞬間、「正しいことをやってくれる」という確信は失われます。やがて、ミッションクリティカルな仕事を任せることをためらうようになり、生産性向上を打ち消すような手動レビューのステップを追加するようになります。エージェントは確かに自律性を提供しますが、確信を生むことには失敗しているのです。そして確信がなければ、自律性は(少なくとも本当に重要な仕事においては)使われなくなります。
これは仮想的な失敗パターンではありません。あらゆるAI活用カテゴリで実際に起きていることです。精度が高くても開発者が結果を疑ってしまうコードレビューエージェントから、品質に問題があるからではなく、顧客がサポートに問い合わせてきたときに「何が起きたのか」を誰も説明できないために、サポートチームがあらゆる対話を裏でモニターし続けている顧客向けエージェントまで、状況はどこでも共通しています。
エージェントがログとして残しているものと、人間が実際に理解できるものとのギャップ。これこそが、結局のところエージェント型プロダクトの定着を阻んでいる正体です。
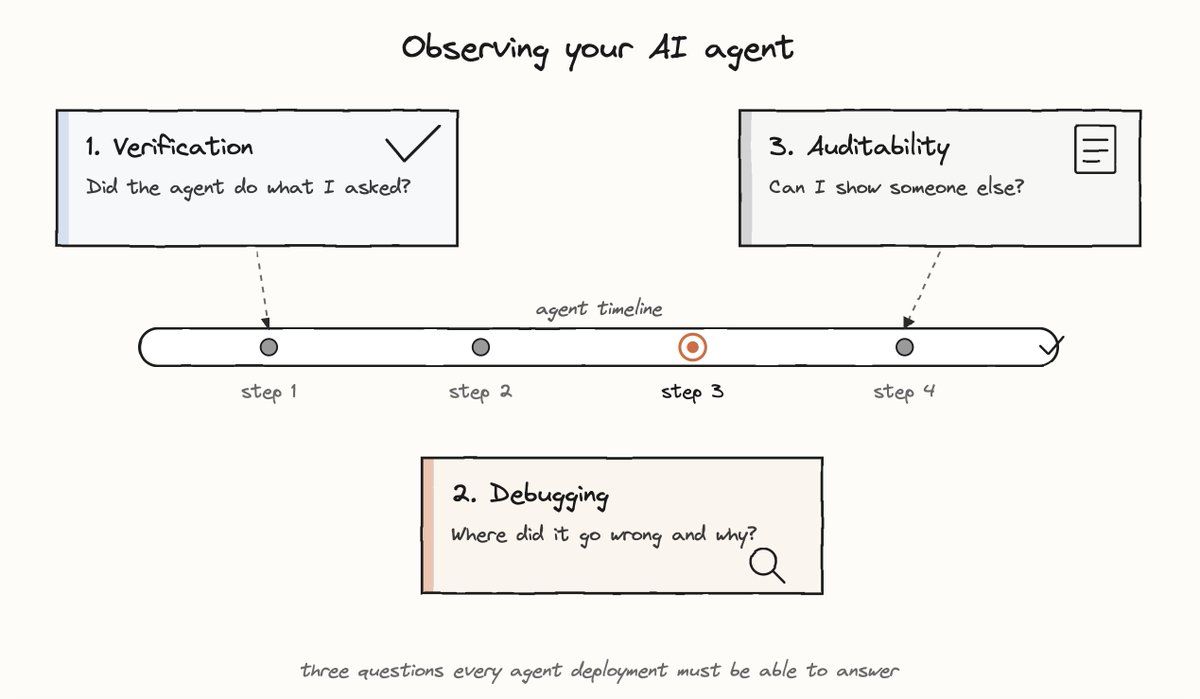
説明可能性が果たすべき主な役割は3つあり、それぞれに対して異なるプロダクト上の対応が必要になります。
ユーザーが求めているのは、素早く確信できる確信です。デバッグしているわけでも、トレースを追っているわけでもありません。ただ「OK」のチェックマークが欲しいだけです。ここでツール呼び出しのログを見せるのは間違いです。「決済は通った?」と聞かれてデータベースのクエリ結果を返すようなものです。
このユーザーはすでに失敗を疑っています。意思決定の経路をたどり、分岐したポイントを特定し、根本原因を理解する必要があります。ここで必要なのは「深さ」です。結果や安心材料だけでは足りません。
ここでの主な利用者はユーザー本人ではありません。マネージャー、コンプライアンスチーム、顧客、あるいは半年後に過去の意思決定を振り返ろうとする「未来の自分」です。そのため成果物は、エクスポート可能で、改ざん不能で、前提知識のない読み手にも伝わるよう構造化されている必要があります。
これら3つを単一のインターフェースで提供しようとすると、どれも中途半端になります。それぞれの目的に求められるものは異なります。検証には情報の圧縮が、デバッグには深さが、監査には構造と永続性が必要です。
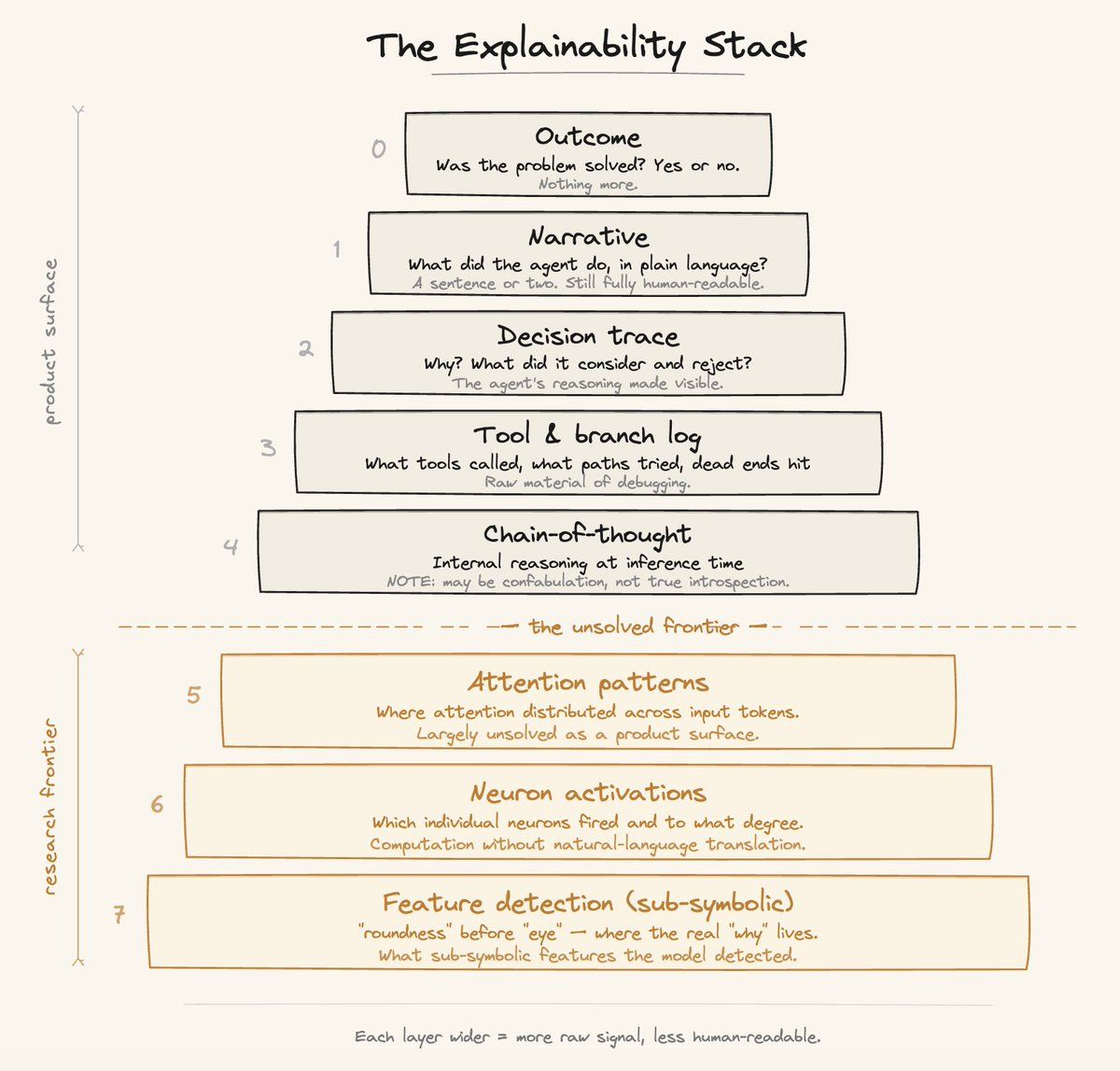
私は説明可能性と観測可能性を、単一の機能ではなく階層化されたアーキテクチャとして捉えています。各レイヤーは、異なる文脈にいる異なるユーザーに対しての正解です。
Layer 0 - 結果(Outcome): うまくいったか?単純な二択です。日常的なタスクでは、ほとんどのユーザーがほとんどの場合に求めているのはこれだけです。
Layer 1 - ナラティブ(Narrative): エージェントが何を行い、なぜそうしたかを平易な言葉でまとめたサマリーです。「PRを作成し、3件の問題を指摘し、42行目、87行目、203行目にインラインコメントを投稿しました」といった具合です。探検報告書のようなものだと考えてください。エージェントが出かけていって、戻ってきて、これがその成果です、という形です。
Layer 2 - 意思決定トレース(Decision Trace): エージェントはなぜそういう選択をしたのか?どんな代替案を検討し、なぜ却下したのか?ここで初めて、行動だけでなく「推論」が見えてきます。
Layer 3 - ツール呼び出し・分岐ログ(Tool and Branch Log): どのツールがどんなパラメータで呼ばれ、何が返ってきて、どんな経路を探索し、どこで行き止まりに当たったか。何かが壊れたとき、エンジニアがたどり着く場所です。これも推論ベースではなく出力ベースですが、エージェントが辿った機械的な経路を示してくれます。
Layer 4 - モデルの推論(Model Reasoning): 推論時の連鎖思考(chain-of-thought)です。モデルが実際にどんな推論プロセスを経ているかを見せ始める層です。評価、モデルの改善、ファインチューニングのパイプラインで非常に価値があり、本番環境でも何かがうまくいかなかった際にエンドユーザーにとって意味を持ちます。
Layer 5〜7 - ディープスタック: 注意機構のパターン、ニューロンの活性、解釈可能性研究の領域です。機械的理解の最先端であり、魅力的なサイエンスですが、(今のところ)プロダクト機能ではありません。
パターンは一貫しています。実装に近い人ほど、より深い層に降りていきたがるのです。週次のエージェント要約を確認するソリューションズエンジニアは Layer 1 にいます。想定外のツール呼び出しをデバッグしている開発者は Layer 3 にいます。創発的なモデル振る舞いを研究する研究者は Layer 5 にいます。説明可能性と観測可能性は万能の「サイズ1」では作れません。あなたのユーザーが実際にどこに立っているかで決まります。
説明可能性スタックには、実用上2つの使い道があります。(1) 適切なユーザー体験を定義すること、(2) どこで成果指標が崩れているかを診断することです。
まず、エージェントに触れるすべてのオーディエンスを書き出します。例えば、エンドユーザー、サポート、セールスエンジニア、コンプライアンスレビュアーなどです。それぞれについて、本当に必要なレイヤーはどれかを問います。多くのチームはこれを単一の「ログ表示」トグルにまとめてしまい、技術者でないユーザーには見せすぎ、エンジニアには不足している状態になっています。解決策は、特定のサーフェスに紐づけた段階的な情報開示です。
Layer 0 はメインのUIに: PR上の緑のチェック、または「3件のチケットを解消」バッジ Layer 1 は非同期のサマリーに: Slackの月曜ダイジェスト、または週次のメールサマリー Layer 2 はワンクリックの「なぜ?」の裏に: ユーザーが同意しないかもしれない決定に対して Layer 3 と 4 は: 開発者向けコンソール、または監査用エクスポートの背後に
この切り分けの効果はサポートで現れます。顧客から「エージェントが間違ったことをやった」と言われたとき、結果から始めて、必要な分だけ深層に下りていくという形でスタックを一緒に降りていけるのです。これが現実に信頼を築く方法です。
スキップしたレイヤーには代償があります。そして、運用が進むほどその代償は積み上がっていきます。
Layer 0 や 1 をスキップすると、定着率が落ちます。 ユーザーとの基本的な信頼ループが築かれず、2回目のタスクを任せる気にならなくなります。エージェントは目新しさだけで止まってしまいます。 Layer 2 をスキップすると、リテンションが落ちます。 ユーザーは、「自分の判断で覆せる」と確信できるエージェントにしか継続的に仕事を任せません。Cursorのdiffビューや Codexの変更プレビューが、モデルのアップグレードに匹敵する(あるいはそれ以上の)定着貢献度を持つのはそのためです。 Layer 3 をスキップすると、エンタープライズ案件が止まります。 この層の重要度は、業界やプロダクトが置かれた規制環境によって変わります。 Layer 4 をスキップすると、評価(eval)の信頼性が損なわれます。 推論トレースがなければ、評価パイプラインは結果のみを根拠にせざるを得ません。すると、エージェントが結果に至るまでに正しい経路を通ったのか、それともテストデータで運よく当たっただけなのかを判別するのがほぼ不可能になります。
説明可能性には時間的な側面があり、多くのチームがこれを十分に定義していません。そしてそこは、プロダクトのアーキテクチャを大きく変える要素です。
同期型の説明可能性では、ユーザーがエージェントの作業をリアルタイムに見守れます。思考のトレース、ライブのツール呼び出しストリーム、目に見える軌道修正、といったものです。この形式は最終出力とは異なる目的を持ちます。実行中に確信を育てるのです。エージェントが非生産的な経路に進みかけて、自分で軌道修正する様子をユーザーが見られると、その「目に見える回復」が信頼をさらに育てます。さらに重要なのは、ユーザーが早期に介入する機会が生まれ、時間とトークンを節約できることです。
非同期型の説明可能性は、事後の報告書です。エージェントが実行し、戻ってきて、どこを通って何を判断したかが構造化された形でまとめられます。この形式があるからこそ、エージェントを並列に大量に走らせるワークロードを管理できます。コードベース全体に対してレビュー、依存関係チェック、セキュリティスキャンを同時並行で走らせるエージェント群を運用しているとき、1つひとつをリアルタイムで見ることはできません。先ほどの「探検報告書」の形式が、そうした管理レイヤーを支えてくれます。
同期型と非同期型の説明可能性は、同じプロダクトではありません。情報の階層構造が違い、許容できるレイテンシが違い、ユーザーとの「感情的な契約」も違います。片方を作ったからといって、もう片方が手に入るわけではありません。
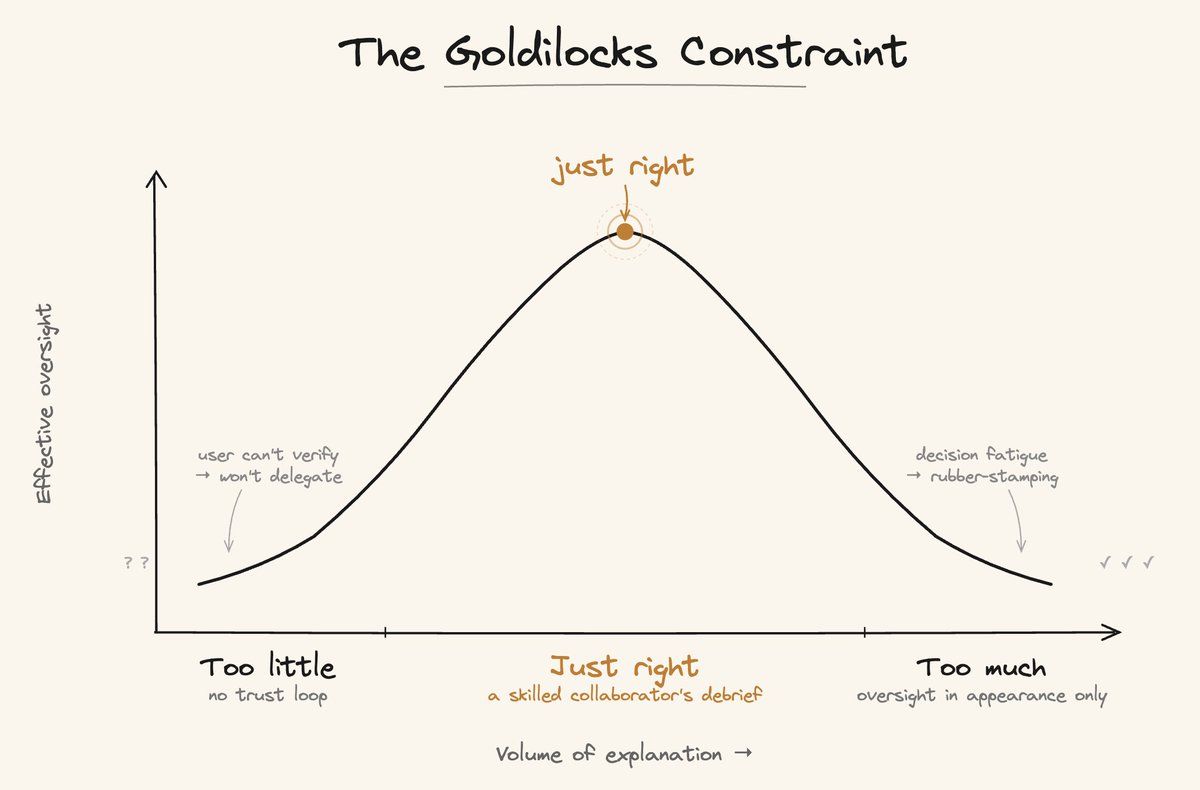
すべての中心には、デリケートな調整問題があります。
説明可能性が少なすぎる:ユーザーがエージェントの推論を検証できないため、重要な仕事を任せようとしません。
説明可能性が多すぎる:ユーザーは判断疲れを起こします。あまりの出力量に、ちゃんと読まずにとりあえず承認するようになり、そのエンゲージメントは形式的なものになります。やがて定着が止まるのは時間の問題です。
最初の失敗パターンの怖さは、ここまでで十分に説明しました。しかし2つ目の方が、もっと地味に効いてきます。「監督しているように見える」だけで、その実体がない状態を作り出してしまうからです。規制環境にいる組織にとっては、見た目以上のスピードでコンプライアンス上の負債になり得ます。
これは新しい領域に現れたグッドハートの法則でもあります。「指標が目標になった瞬間、それは良い指標ではなくなる」というものです。「説明の量」が「監督の質」の代理指標になってしまうと、プロダクトはその代理指標を最適化し、本来測りたかったものを失います。ログ、トレース、推論テキストが増えても、その先には、もう何も読まなくなった読み手しかいない、という状況になります。
私がいつも立ち戻る基準点はこれです。優秀な人間のコラボレーターが何かを独力でやり終えた後、あなたにどう伝えるでしょうか。検索クエリを1つずつ実況したり、ブラウザ履歴をまるごと共有したりはしません。こう言うはずです。「XとYを見ました。Xはこういう理由で行き止まりでした。Yがこの先進む道で、その理由はこれ、確信が持てない部分はこのあたりです」。
説明可能性を見せる形式はいくつもあります。自然言語による説明、構造化されたタイムライン、ビジュアルなdiff表示、折りたたみ可能なツール呼び出しツリーなどです。文脈次第でどれも妥当な形式です。より興味深いプロダクト上の問いは、どの形式を選ぶかではなく、文脈とユーザーに応じてエージェント自身が適切な形式を判断できるようにするにはどうすればいいか、ということです。
同期型のトレースなら、ユーザーがその場にいて自分でナビゲートできるので、生のままの構造でもある程度許容されます。一方、読み手に前提知識がない非同期レポートでは、生ログを解読することを期待できません。ここでは「キュレーション」が前提条件になります。関連性、可読性、構造化された理解しやすさが必須です。
この問題に対して、業界全体で通用する最適解はまだないと思っています。しかし、これを単なるエンジニアリング上のロギング問題ではなく、プロダクトデザインの問題として捉えるチームが、より早くそこに辿り着くはずです。
数年後、私たちは「なぜあるプロダクトは他より成功したのか」を振り返ることになります。1つはっきりしているのは、より良い説明可能性を備えたプロダクトの方がユーザーから大きな信頼を得て、ミッションクリティカルなタスクに選ばれるようになる、ということです。
基盤モデルがコモディティ化に向かう中で、本当の差別化要因は、プロダクトがどれだけユーザーとの絆を深く築けるかになります。信頼は、人と人の間でも、人とプロダクトの間でも、あらゆる絆の土台です。

これは、CodeRabbitにおいて机上の空論ではありません。すべてのプロダクトを横断する形で、説明可能性の構築を進めています。出力で開発者を埋もれさせずに、何が起きてなぜそうなったかをどう見せるか、という問いに、いま本番環境で取り組んでいるところです。具体的にどんな形になるかは、近々お伝えします!


