Atsushi Nakatsugawa
April 23, 2026
1 min read
OpenAI GPT-5.5 Benchmark (CodeRabbit)の意訳です。
初期テストでは、このモデルはより直接的にコミュニケーションを行い、よりシグナルの高い問題を発見し、実践的なコーディングおよびレビューのワークフローでより優れたパフォーマンスを発揮することが示されています。
注記: リリース期間中、GPT-5.5はChatGPTおよびCodexで試すことができます。
GPT-5.5を使った感触は、多くの具体的な点で異なるものでした。より速く、よりスリムで、より直接的でした。実際には、より短いレスポンス、より選択的なレビュー動作、そして大規模な書き換えではなく小さく実行可能な変更を好む傾向が見られました。
これは、CodeRabbitを使用しているチーム、エージェントワークフローを構築しているチーム、またはモデルにコードベース内で実際の変更を行わせるケースにおいて、最も関連性が高いです。
このモデルは素早く応答し、少ないオーバーヘッドでコミュニケーションを行い、無駄な動きなく実用的な回答に向かいます。そのスピードの一部は、内部処理の完了を待たずに、ユーザーに見える進捗をいかに早く表示するかという点にも表れていました。
その点は、出力の品質にも引き継がれています。コードレビュー、バグ修正、デバッグタスクにおいて、このモデルは一貫してスコープを絞った変更を好み、既存の動作をより多く保持し、通常は投機的な再設計に逸れるのではなく、実際の障害モードに焦点を当てられていました。
テストで最も明確に現れた強みの一つはコードレビューでした。優れた例では、このモデルは具体的で実行可能な、開発者のフローを中断してでも対処する価値のあるバグに焦点を当てています。
デバッグ指向のレビューでは特に顕著です。タスクがアクセス制御、エラーハンドリング、またはAPIの動作に関わるものである場合、モデルは実際のリグレッションを特定し、弱い診断を却下し、意図された動作を保持する修正を提示することが多くできていました。
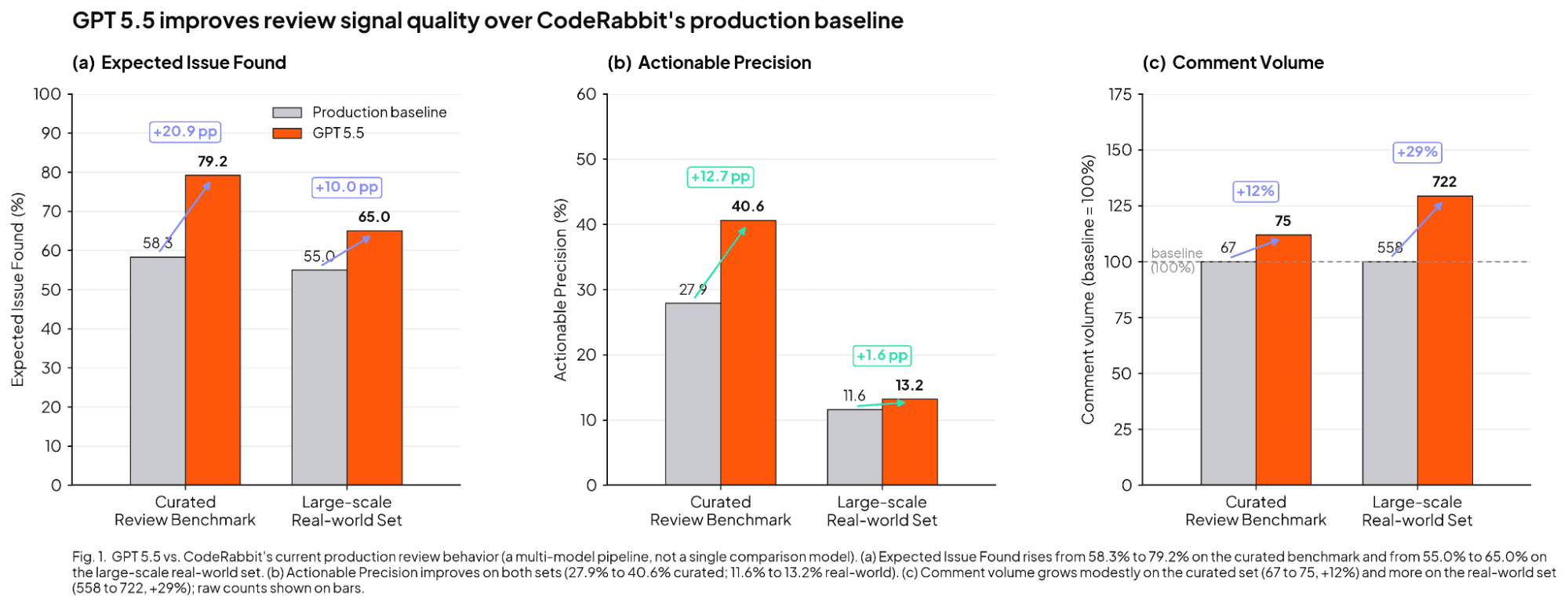
ベンチマーク結果はこの観察と一致しています。以降の図とテキストで言及される「ベースライン」は、単一の比較モデルを指すものではありません。これはCodeRabbitの現在の本番レビューシステムを意味しており、単一のモデルに依存するのではなく、複数のモデルの組み合わせを採用しています。
GPT-5.5の初期テストでは、エージェントはキュレーションされたレビューベンチマークにおいて、期待される問題発見率が58.3%に対して79.2%に達し、精度は27.9%から40.6%に向上し、ベースラインの67件に対して75件のコメントを生成しています。これは、コメント量のわずかな増加のみで、はるかに多くの有用な問題を発見したことを意味します。テストでは、GPT-5.5は大規模な実世界のレビューセットにおいて、いくつかの主要メトリクスでパフォーマンスを向上させました。具体的には、期待される問題発見率がベースラインの55.0%から65.0%に増加しています。さらに、精度は11.6%から13.2%に向上しました。エージェントはより多くのコメントを生成するようになり、以前のベースラインの558件に対して722件のコメントを生成しました。
実用的な観点では、GPT-5.5はシグナルの品質においてベースラインを上回りましたが、レビュー量がベースラインより一様に少ないわけではありませんでした。
その動作の一部は、プロンプトの背後にあるレビュー基準に起因しているようです。端的に言えば、モデルは実際に存在し、変更箇所に局所的で、著者が修正できるほど具体的なバグをフラグするよう促されています。
隠れた意図を推測したり、コードベース全体の品質について不満を述べたり、コンパイラ、型チェッカー、またはLinterがすでにキャッチするような問題をフラグしたりすることは想定されていません。関連するコメントガイダンスも同じロジックに従っています。コメントは簡潔で、明示的で、事実に基づくものであるべきです。
このパフォーマンスが将来のロールアウトにも引き継がれるのであれば、CodeRabbitユーザーにとって具体的なメリットとなるでしょう。選択性の向上は、無関係なコメントの精査に費やす時間の削減、冗長なレビュースレッドの減少、そして受け取るフィードバックが最も対処すべき問題を指摘している可能性の向上につながります。
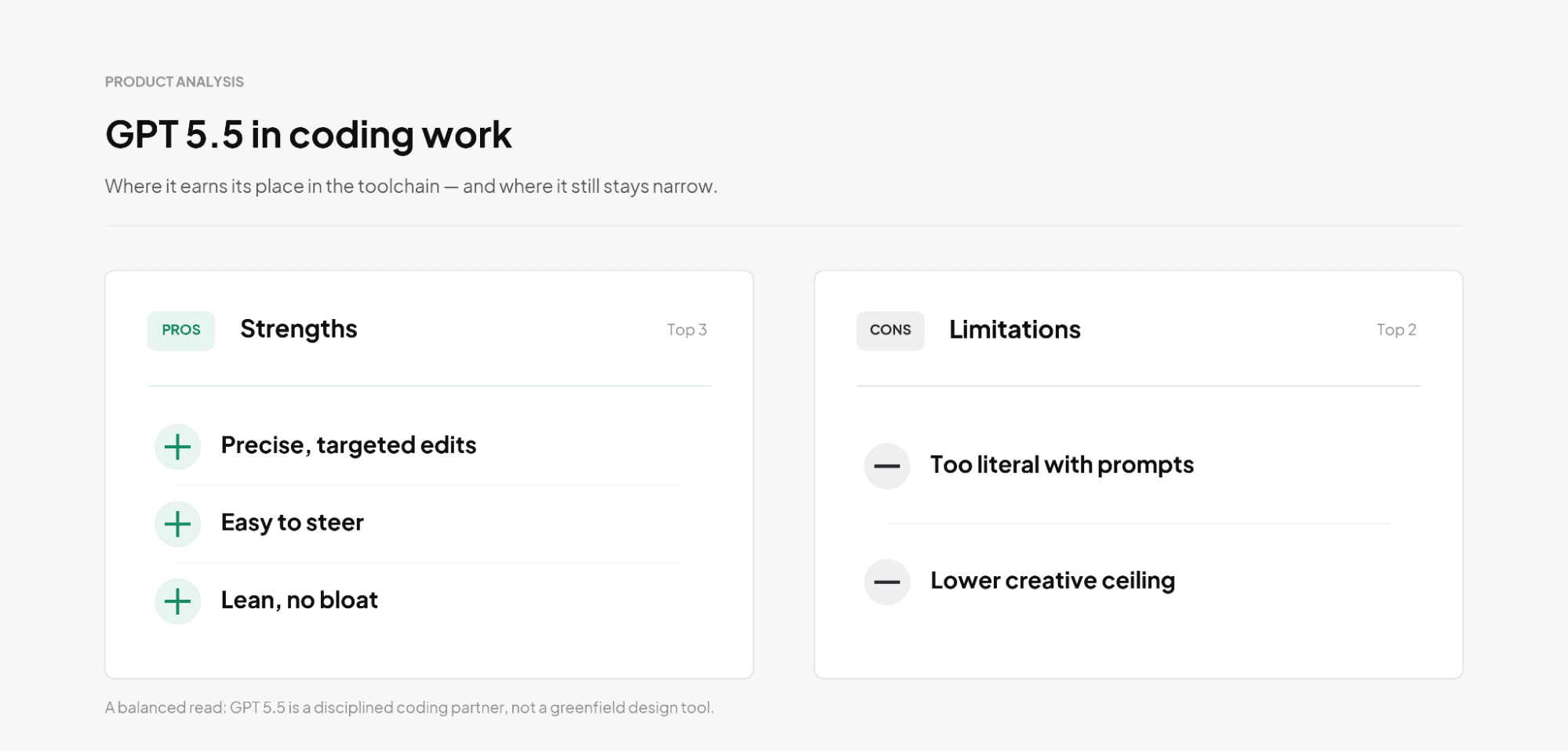
レビューとは別に、このモデルはコード生成および実装作業でも良好なパフォーマンスを示しました。ここでの主な強みは制御力であり、スコープを絞った変更を選択し、求められた場合は既存のインターフェースを保持し、過度な構築を避ける傾向があります。
収集された例は、そのパターンを明確に示しています。エンドポイントの拡張、ルートコントラクトの維持、運用上の問題の解決を任されたとき、モデルは一貫して予測可能な結果をもたらす精密な変更を好むようです。安全性の強化、インターフェースの保持、意図しない影響の最小化です。コード全体を書き直すのではなく、問題を解決するための最小限の変更を優先し、周囲のシステムの安定性を維持しています。
GPT-5.5のコード生成は、タスクが具体的でスコープが限定されている場合に最も優れています。バグ修正、軽微なAPI調整、元の動作を維持するリファクタリング、ターゲットを絞ったテストの追加といった集中的なタスクに非常に効果的です。
UIタスクにおいては、同じパターンにより洗練されたインタラクション作業と堅実なライブラリ使用が生み出されましたが、独創性は実行品質ほどには高くありませんでした。私たちのチームは、予想以上に優れたアニメーション処理と異例に詳細なインタラクションを確認しましたが、同時に馴染みのあるスタイリング選択に頼る傾向もあり、顕著なインディゴ-バイオレットのカラーバイアスが見られました。
モデルを直接使用する開発者にとって、インタラクションパターンはかなり明確です。モデルは、タスクのスコープが定められ、制約が明示的で、環境がフィードバックを提供できる場合に最も良い結果を出すようです。実際には、具体的な要件を与え、インターフェースの期待を保持し、可能な場合にはシステムの実行や検証を許可することを意味します。
モデルは、すべてを一発で解決しようとするよりも、変更、検証、修正という目に見えるループを経ることで、より良いパフォーマンスを発揮しました。これは、テスト全体を通じて見られたより広いパターンと一致しています。より直接的な出力、より少ないトークンの浪費、そして範囲が限定されたタスクでのより良い結果です。
私たちのチームのテストでは、モデルが指示に過度に忠実に従うことが明らかになりました。特にプロンプトの構造が不十分であったり、詳細が不足していたり、根本的なコンセプトが弱い場合に顕著です。そのような場合、モデルは自ら方向性を修正しないことが多くありました。より経験豊富な協力者であれば立ち止まって確認したり、前提に異議を唱えたりするような場面でも、書かれた通りのリクエストを実行する傾向があります。
つまり、プロンプトの品質が、開発者が予想する以上に結果に大きな影響を与えるということです。モデルは、意図された動作、制約、成功基準について具体的なリクエストが行われた場合に最も強く見えます。
曖昧なプロンプトや内部的に矛盾するプロンプトは、モデルに迅速な応答を生成させることがありますが、その出力はプロンプトの既存の弱点を修正するのではなく、反映してしまう可能性が高くなります。
GPT-5.5の注目すべき焦点は効率性です。これはレビューにおけるパフォーマンスほどベンチマークで測定しやすいものではありませんが、テストで最も際立ったトレンドの一つとして浮上しました。モデルは多くの場合、より冗長でなく、目に見える進捗を迅速に表示しました。これは、新バージョンが以前のモデルと比較して同等のタスクに必要なトークン数が少ないことを示唆していますが、単一のベンチマーク数値で分離するのが難しいメリットです。
これは、正しい答えに収束するために繰り返しのイテレーションに依存するエージェントハーネスにとって特に関連性があります。OpenClawのようなパターンに従うシステム、またはエージェントが多くのサイクルにわたって計画、実行、検証、リトライ、改善を行う必要のあるワークフローでは、トークンの非効率性は急速に蓄積されます。
モデルが効果を維持しながら簡潔でいられるなら、長いループにおけるトークンを多く消費するオーバーヘッドの量を削減できます。外部サービスやエージェントプラットフォーム上に構築しているチームにとって、トークン使用量がワークフローの足を引っ張り始める前に、より多くのイテレーションの余地が生まれることを意味します。

GPT-5.5の主な強みは開発者ワークフローにあり、具体的には次の点で優れています。以前のモデルよりもより実質的な問題を特定すること、広範なリファクタリングなしに焦点を絞った変更を実装すること、そして初回のエラー後に効果的に自己修正することです。
CodeRabbitのようなツールを評価しているチームにとって、より根拠のある主張は、普遍的にレビュー量が少ないということではなく、ベースラインよりもレビューあたりのシグナルが優れているということです。モデルを直接使用する開発者にとっても、パターンは同様に明確です。スコープを絞ったタスクを与え、制約を明示的にし、実際のシステムに対して作業を検証させることです。
CodeRabbitを始める。リポジトリを接続して、数分で最初のAIレビューを受けられます。CodeRabbitはクレジットカードは不要で、無料でお試しいただけます。