
Atsushi Nakatsugawa
April 21, 2026
1 min read
How CodeRabbit built a planning layer on Claudeの意訳です。
David Lokerは個人開発に取り組んでいました。サイドプロジェクトで、メモリエンジンを中心に構築されたセキュアなインフラシステムに、テスト用のチャットインターフェースを重ねたものです。特に画期的なものではありません。開発者が週末にやることをやっていただけです。
彼には明確なビジョンがありました。全機能をログイン後にすること。ユーザーを認証すること。セッションをアカウントに紐付けること。最初からすべてをセキュアにすること。
そこでCodeRabbitのAI担当副社長であるLokerはClaude Codeを立ち上げ、実行させました。彼は望むものを記述しました。イテレーションしました。トークンが流れるのを見守りました。数時間にわたり、システムは構築し、コンパイルし、進捗を出し続けました。最終的に完了したと報告されたとき、Lokerは身を乗り出して試してみました。
彼はログイン方法を尋ねました。
システムはユーザートークンを使うように言いました。
彼はトークンをどこで取得するか尋ねました。
答えはありませんでした。なぜならログインページが存在しなかったからです。ユーザーを作成する方法もありませんでした。いかなる種類の認証フローも存在しませんでした。アプリケーションは、ユーザーという概念を中心に、徹底的に、誠実に、正確に構築されていましたが、ユーザーを実際に作成する指示は一度も与えられていなかったのです。
「それは単純に私が見落としたものでした」とLokerは、Anthropicとの最近のウェビナーでこのエピソードを振り返りながら語りました。「指定する必要があるということに気づかなかったのです。明確ではありませんでした。」
数時間のAIコーディングを経て得られたのは、機能的に洗練されたアプリケーション。しかし、追加の作業なしでは完全に使用不能でした。
CodeRabbitは世界中のエンジニアリングチームのプルリクエストワークフローの中に位置しています。数千万件のコードレビューを処理するという観点から、CodeRabbitはAI駆動開発を内側から見ています。しかし、ボリュームとスピードは物語の一部にすぎません。もう一つの部分は語りにくいものです。
確かに、AIコーディングツールは開発者を加速します。開発者あたりのプルリクエスト数は20%増加しています。機能のリリースは速くなり、バックログは縮小します。実際に生産性の向上が見込めます。
しかし、その反対側にコストもまた存在します。インシデントは23.5%増加しています。AI生成コードは人間が書いたコードよりも1.7倍多くの問題を生み出します。可読性の問題は3倍に急増しています。
Lokerはこれを「AIの隠れた品質税」と呼んでいます。そして、Anthropic Applied AIエンジニアのEthan DixonおよびAnthropicアカウントエグゼクティブのBrittney Tongがモデレーターを務めたウェビナーで展開された彼の主張は、ほとんどの人が原因を誤認しているというものです。
「私が言いたいのは、これは必ずしもモデルだけの問題ではないということです」とLokerは聴衆に語りました。「これは実際には、私たちがツールをどのように活用するかの結果なのです。」
モデルが壊れているのではありません。そう、ワークフローが壊れているのです。
ウェビナーの途中、AIプロジェクトが失敗する原因について参加者に尋ねるライブアンケートが行われました。結果は圧倒的で、「重要な要件が明示されず、当然のこととして想定されていた」というものでした。
これは一見シンプルな問題です。開発者がAIコーディングエージェントに機能を記述しようとするとき、彼らは自分のコードベース、チームの規約、会社のインフラに関する長年のコンテキストを持っています。あまりにも当たり前に感じるので、前提として認識すらされないものです。しかしAIにはそのような背景がありません。新入社員にもありません。AIは多くの場合、ギャップを自分で埋めて構築を続けてしまいます。
「私たちの頭の中には、最初は知らなかったけれど教えてもらった知識があります。そしてその知識があると、誰もが知っていると思い込んでしまいます。そう、AIシステムに対しても同じ思い込みをしてしまうのです」とLokerは投票結果に反応して述べました。
ログインページが欠けていたのは、AIが失敗したからではありません。Lokerが、AIコーディングツールを使ったことのある実質的にすべての開発者と同様に、完全だと感じていたメンタルモデルから作業していたからです。そしてそれは完全ではなかったのです。
この失敗が非常に厄介なのは、プロセスの後半まで事実上見えないことがあるという点です。コードはコンパイルされます。テストは通ります。ビルドは前進します。従来のあらゆる指標では問題なく進んでいるように見えます。そしていざログインしようとすると、何もないのです。
「テストには通りますが、テストに通ったからといって根本的な問題を解決したわけではありません」とLokerは述べました。「問題がコードのコンパイルにないこともあるのです。」
これは正確には新しい種類の失敗ではありません。開発者は常に時として間違ったものを構築してきました。意図と出力の不一致はソフトウェアそのものと同じくらい古い問題です。
変わったのは、それが積み重なるスピードです。AIコーディングツールの前は、機能の構築に十分な時間がかかったため、問題は途中で自然に表面化する傾向がありました。次のステップを考えるために立ち止まりました。同僚に何をしているか説明しました。作業そのものが振り返りの瞬間を生み出していたのです。AIはそのペインポイントの大部分を取り除きます。それがポイントであり、概ね良いことです。
しかし同時に、何かがあなたを止めるまでに、間違った方向にとても遠くまで進んでしまえるようになったことも意味します。かつて数日かかっていたフィードバックループは、今では自然には発生しないため、意図的に設計し直す必要があります。
「構文の生成はかなり速い作業です」とLokerは述べました。「しかし、ある方向に進みすぎて、そのギャップの発見が遅れると、戻るのにコストがかかる可能性があります。」
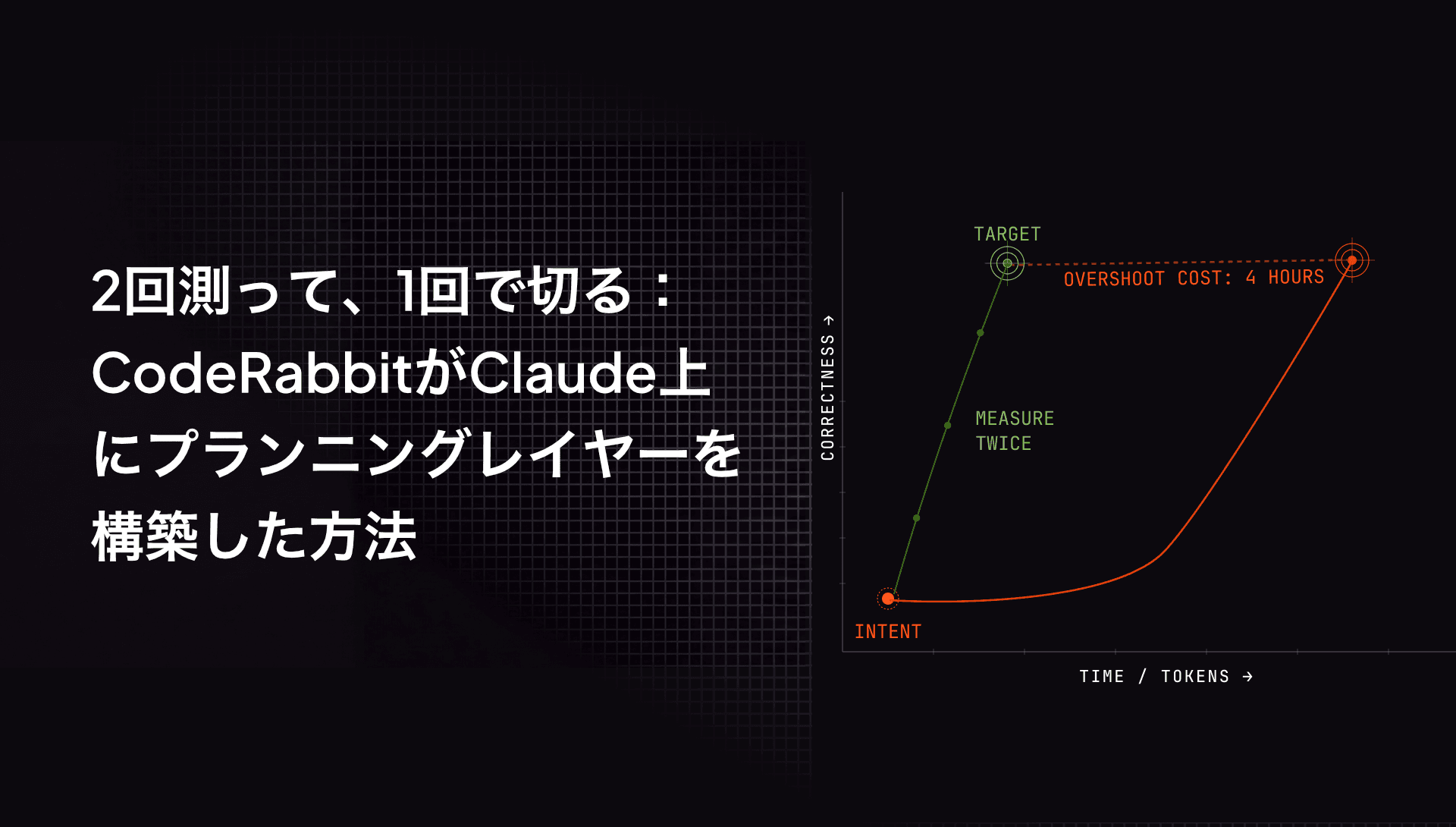
カナダで育ったLokerは、父親と一緒に家の周りのものを作ることに多くの時間を費やしました。フェンス、デッキ、地下室の仕上げ。父親にはいつも繰り返す口癖がありました。正しいがゆえに子供を苛立たせる種類の言葉です。「測定は2回、切るのは一度(measure twice, cut once)」。
「その木材を切ったら、それで終わりです」とLokerは説明しました。「正しい長さか、戻って別のものを使ってやり直すかのどちらかです。子供の頃、このいつも物事を遅くするという考え方には腹が立ちました。しかし最終的には、より慎重に作業し、正しいことをしているか確認することで、全体的なプロセスはより速くなるのです。」
もう一つの口癖も、急いでいる子供には同様に苛立たしいものでした。「急がば回れ(less haste, more speed)」。
「今では理解できます」とLokerは語りました。「Claude Codeを使えば本当に速く進めます。そして結局のところ、何時間もイテレーションを重ねた末に、実際に作りたかったものを作っていなかったと気づくよりも、間違ったものを作っていることに早く気づく方がいいのです。」
これらは古くからのエンジニアリング原則です。ソフトウェアよりも何世紀も前から存在しています。しかしAIが経済性を変えたことで、これらは新たな緊急性を帯びています。エージェントが数分で数千行のコードを生成できるとき、間違った方向に進むコストはかつてないほど高くなっています。
現在のAIコーディングツールの支配的なパターンは、Lokerが「プロンプトオンリーワークフロー」と呼ぶものです。開発者がプロンプトに説明を入力し、エージェントが実行し、コードが出力されます。それは速く、直感的です。そして、前提が隠れる場所でもあります。
「多くの場合、そこで私は自分の前提を見落とします」とLokerは述べました。「積極的に関与してプロセスを考え抜き、レビューしているわけではないからです。意識の流れのようにやっているのです。」
個人の問題としてもコストは十分に大きいです。チームレベルになると、それは構造的な問題になります。
チームの一人の開発者が孤立してエージェントにプロンプトを出すと、その前提、コンテキスト、要件の解釈は他の誰にも見えません。チームメイトは見えないものを指摘できません。シニアエンジニアは、会社の既存のRedisセットアップを考慮していないアーキテクチャ上の決定にフラグを立てることができません。プロダクトマネージャーは、元のスペックからドリフトした機能スコープを発見できません。前提は散在し、無言で、積み重なっていきます。
Dixonは、プロセスを超えたプランニングの重要性について技術的な視点を提供しました。Anthropicでは、コンテキストエンジニアリングと呼ばれるものについて深く考えています。これは、AIモデルのアテンションウィンドウにどの情報をいつ入れるかを管理するプラクティスです。
コンテキストは有限なリソースであるとDixonは説明しました。プロンプトに追加されるすべてのトークンは、モデルのアテンションを他のすべてのトークンと奪い合います。多すぎるものを読み込んだり、間違ったものを読み込んだり、間違ったタイミングで読み込んだりすると、長いタスクにわたるモデルの一貫性が低下します。
DixonはOpus 4.6がneedle-in-a-haystackのようなテストでリーダーボードを上昇するなど、長コンテキストの一貫性で意味のある進歩を遂げていると指摘しつつ、「コンテキストエンジニアリングは解決済みの問題ではない」と付け加えました。
プランニングは、実行途中にその問題を追いかけるのではなく、先手を打つ方法であると彼は主張しました。
「プランニングをこのような先行的なコンテキストエンジニアリングの手段として扱うことの素晴らしい点は」とDixonは述べました。「この前作業がすべて事前にロードされることです。すべての探索を行い、発見する作業を行い、本当に一貫性のあるプランを立てれば、長期的にエージェントの動作がはるかに効果的になります。」
この前段階の投資がなければ、エージェントはファイルの再読み込み、予期しないバグに遭遇した際のバックトラック、最初から持っているべきだったコンテキストの再確立に高価なコンピュートを費やすことになります。この文脈でのプランニングは、単なる良いプロジェクト管理ではありません。良いシステムアーキテクチャなのです。
これらすべてに対するCodeRabbitの回答がCodeRabbit Planです。コーディングエージェントの上に位置し、エージェントを置き換えるのではなく、エージェントを指揮するオーケストレーションレイヤーです。
この区別はLokerにとって重要です。「このプランニングシステムは、Claude Codeのプランニングシステムを排除するためのものではありません」と彼は述べました。「それを本当に狭い正しい方向に向けるための、より高レベルなオーケストレーションであり、協調的であることが目的です。明示的にすべきことがすべて明示的になるようにするためです。」
ワークフローはイシュートラッカーから始まります。Jira、Linear、GitHub Issues、またはGitLabからチケットが届くと、プランナーが作業を開始します。Claude Opusをメインのブレイン・オーケストレーションループとして、コードベースを探索し、過去のプルリクエストから関連コンテキストを取得し、暗黙の前提を表面化させ、レビュー可能なフェーズに分割された構造化されたコーディングプランを生成します。重要なのは、そのプランがチームのアーティファクトであるということです。コードが書かれる前に、可視的で、編集可能で、バージョン管理されます。
「プランそのものが...品質ゲートです」とLokerは述べました。「それを本当に良いものにできれば...下流への効果は非常に顕著です。最終的にはるかに良いコードが得られるのです。」
CodeRabbit Planは単一のAIモデルでは動作しません。Claude Opus、Sonnet、Haikuの3つのモデルで動作します。各モデルは、Lokerの言葉を借りれば、タスクの複雑さに合わせてマッチングされます。
中心に位置するのはOpusです。Lokerはそれを「メインのブレインおよびオーケストレーションループ」と表現し、システム内で最高レベルの推論を担当するとしています。「より高レベルで非常に戦略的な決定を行っています」と彼は述べました。「問題について何を理解する必要があるか、何がわかっていないか、そしてその情報を体系的に発見するための戦略をどのように立てるかを理解するのです。」
Sonnetは、Lokerが「もう少し低いレベルで、おそらくもう少しターゲットを絞ったタスク」と表現するレイヤーで動作します。明確に定義されているが、それでも実質的な構造化された作業です。
Haikuは最も粒度の細かいレイヤー、つまり複雑度の低いタスクとコンテキストの蒸留を処理します。Lokerは実際にどのようになるかの具体例を示しました。「ここに大きなファイルがあります。この関数が必要です。それが何をするか理解する必要がありますが、コード自体は本当は必要ありません。」その種の抽出にHaikuを使用することで、システムは必要のない作業に高価なOpusやSonnetのトークンを消費することを避けられます。「Haikuはトークンコストが安く、速いです」とLokerは述べました。「そしてこれを行うことで、これは頻繁に発生するのですが、多くのコストと時間を節約できます。」
HaikuティアについてのDixonの見解は次の通りです。「ほとんどのユースケースで軽量版Sonnetとして扱っています。」彼はHaikuが高負荷の下で性能低下を見せ始める点を付け加えました。「多くのファイルをトラバースしたり、非常に複雑なプランの途中にいる場合、そこがHaikuクラスのモデルとSonnetの性能低下の違いが見え始めるところだと思います」と述べました。
ティアリング全体の目標は簡潔であるとLokerは述べました。「必要な場所でオペレーションのブレインを使い、すべての場所では使わないということです。」
プランナーの構築には、CodeRabbitが持っていなかったもの、つまりコード品質だけでなくプランニング品質の評価システムを構築する必要がありました。そしてそれは予想以上に難しかったとLokerは認めました。
「最初は手動でチューニングしていました」とLokerは述べました。「大量の手動検査を行う必要があります。プランの特定の側面を評価できるLLMジャッジの良いセットをゆっくりと構築していく必要があります。」
一つのチャレンジは、プラン自体の適切な詳細レベルを見つけることでした。詳細すぎると、コードが進化し始めた瞬間にプランが陳腐化します。「その転換点を見つけるのは困難でした。多くのイテレーションが必要でした。」
後から得られた別のインサイトもありました。探索フェーズで消費されるトークンを測定し、プランニングステップが実際に下流の効率性を生み出しているかどうかのシグナルとして使用するというものです。システムは最終的にコードを出力するため、コードを評価し、プランニングステップを完全にスキップした場合の出力と比較できます。
Dixonはこの種の評価規律が一般化できることを指摘しました。「この種のテクノロジーの上にプロダクトを構築するチームは、自分たちのドメインにとって適切な粒度のレベルは何かを考えることで、実際に大きな恩恵を受けられます。」
協調的なプランニングには、目の前の成果物を超えたメリットがあり、Lokerはウェビナー中にその点について時間を割きました。チームがプランを一緒に練り上げ、前提を表面化させ、スコープを議論し、成功基準を合わせると、何が決定され、なぜ決定されたかの記録が生まれます。
「新しい人が来て、これをどのように構築したか、なぜ構築したかを理解したい場合」とLokerは述べました。「今やその記録があります。一過性のものではありません。」
その記録はバリデーションツールとしても機能します。コードが戻ってきたとき、チームはテスト結果だけでなく、元のプランと照合して確認できます。意図に対して確認するのです。私たちがやると言ったことを行ったか?合意した成功基準を満たしたか?
Dixonは新しい現実、AIコーディングの一種の新しいステージをまとめました。「プランの品質は、一般的にLLM駆動のナレッジワークにおける、この新しい種類の重要な瞬間です。」
これは新しいアイデアではありません。エンジニアは常に知っていました。自分が何を構築しているかを理解すること、それを漠然と示すのではなく本当に理解すること、それがプロジェクトを出荷できるか3回やり直してからようやく間違っていたと認めるかの違いです。
新しいのは経済性です。AIが意図と実行の間の時間を劇的に圧縮したことで、不整合のコストが非対称になりました。かつて数週間かかっていたものを数時間で構築できるようになりました。つまり、かつてないほど速く、大規模に、間違えられるようになったのです。
ログインページの話は振り返ると面白いものです。何時間ものトークン、洗練されたアプリケーション、ログインする方法がない。しかしこれは、ボトルネックが移動したことをまだ学んでいる業界へのストーリーでもあります。かつてはコードを書くことがボトルネックでした。AIがそれを移動させました。今やボトルネックは何を書くかを知ること、そして最初の一行が生成される前に全員が合意することです。
Lokerの父親はずっと正しかったのです。測定は2回、切るのは一度、そして急がば回れは正しい教訓でした。
ただ、その教訓を定着させるのに、AIコーディングエージェントとログインページの欠落が必要だっただけです。
CodeRabbit Planは現在ご利用いただけます。こちらからお試しください。


