


Juan Pablo Flores
Abhilash Harish Srivathsa
April 23, 2026
7 min read
April 23, 2026
7 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GetStarted in2 clicks.
Our early testing shows the model communicates more directly, finds higher-signal issues, and performs better in practical coding and review workflows.
Note: During release, you can try GPT-5.5 in ChatGPT and Codex.
Using GPT-5.5 felt different in a fairly specific way: it was quicker, leaner, and more direct. In practice, that meant shorter responses, more selective review behavior, and a stronger bias toward small workable changes instead of broad rewrites.
This is most relevant for teams using CodeRabbit, building agent workflows, or asking the model to make real changes in codebases.
The model responded quickly, communicated with less overhead, and moved toward practical answers without much wasted motion. Part of that speed was also visible in how quickly it surfaced user-facing progress instead of waiting to finish all of its internal work before responding.
That directness carried over into the quality of the output. Across code review, bug-fixing, and debugging tasks, the model consistently leaned toward scoped changes, preserved behavior more often, and usually focused on the actual failure mode rather than drifting into speculative redesign.
One of the clearest strengths in our testing was code review. In the stronger examples, the model focused on bugs that were concrete, actionable, and worth interrupting a developer's flow.
It showed up clearly in debugging-oriented reviews. When the task involved access control, error handling, or API behavior, the model was often able to isolate the actual regression, reject a weak diagnosis, and point toward a fix that preserved the intended behavior.
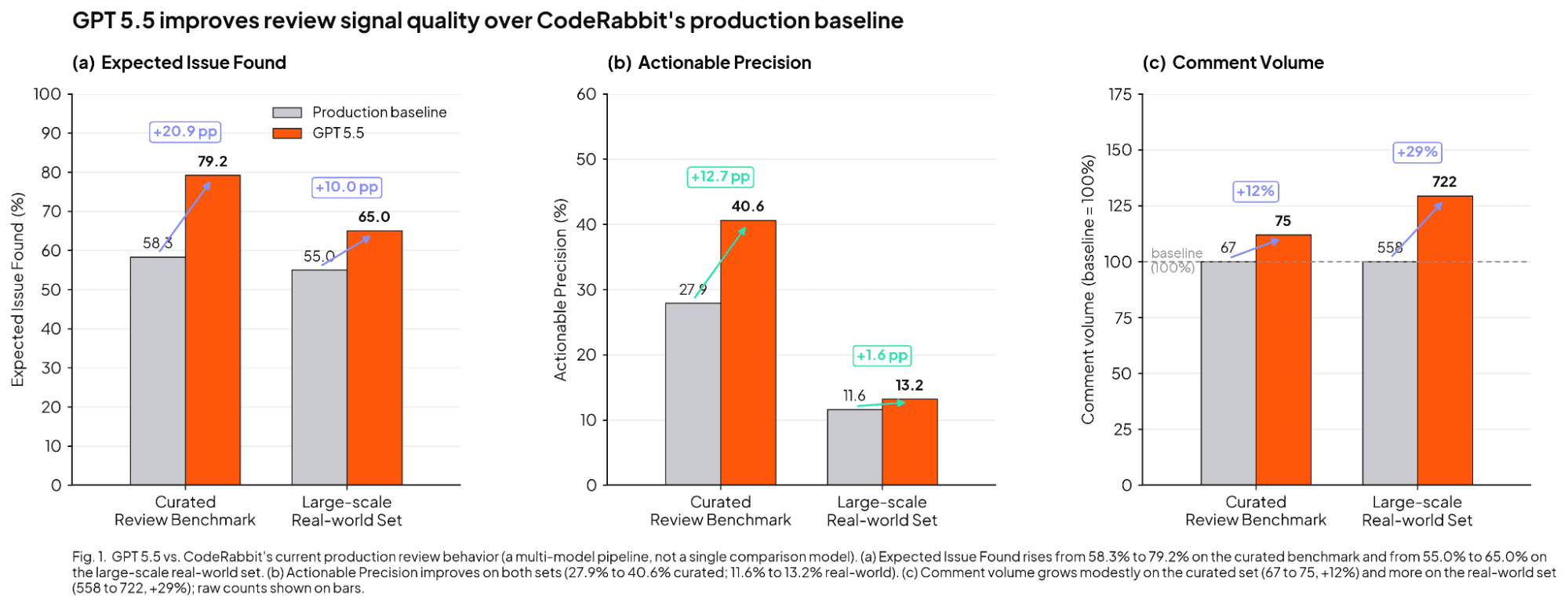
The benchmark results align with this observation. The "baseline" mentioned in the subsequent diagram and text does not refer to a single comparison model. Instead, it signifies CodeRabbit's current live review system, which employs a combination of various models rather than relying on just one.
In our early testing with GPT-5.5, the agent reached 79.2% expected issue found on our curated review benchmark versus 58.3%, improved precision from 27.9% to 40.6%, and produced 75 comments versus the baseline's 67. That means it found substantially more useful issues with only a modest increase in comment volume. In testing, GPT-5.5 improved performance across several key metrics on our large-scale, real-world review set. Specifically, the expected issue found rate increased from a 55.0% baseline to 65.0%. Furthermore, precision improved from 11.6% to 13.2%. The agent also became more verbose, generating 722 comments compared to 558 with the previous baseline.
The practical takeaway is that GPT 5.5 outperformed the baseline on signal quality, even though its review volume was not uniformly lower than baseline.
Part of that behavior appears to come from the review standard behind the prompt. In plain terms, the model is being pushed to flag bugs that are real, local to the change, and specific enough that the author could fix them.
It is not supposed to guess about hidden intent, complain about broad codebase quality, or flag issues that a compiler, type checker, or linter would already catch. The associated comment guidance follows the same logic: comments should be brief, explicit, and matter-of-fact.
If this performance carries into a future rollout, it would be a tangible benefit for CodeRabbit users. Increased selectivity translates to reduced time spent sifting through irrelevant comments, fewer redundant review threads, and a greater likelihood that the feedback you receive highlights the issues most worth addressing.
Separate from review, the model performed well at code generation and implementation work. Its main strength here was control, as it tended to choose scoped changes, preserve existing interfaces when asked, and avoid overbuilding.
The examples collected show that pattern clearly. When tasked with extending endpoints, maintaining route contracts, or resolving operational issues, the model consistently favored precise modifications with predictable results: enhanced safety, interface preservation, and minimized unintended consequences. Rather than completely rewriting the code, it prioritized the smallest possible modification to resolve the issue while maintaining the stability of the surrounding system.
GPT-5.5's code generation excels when tasks are specific and limited in scope. It is highly effective for focused tasks such as bug fixes, minor API adjustments, refactoring that maintains original behavior, and adding targeted tests.
In UI tasks, that same pattern produced polished interaction work and solid library use, though originality remained more limited than execution quality. Our team saw better-than-expected animation handling and unusually detailed interactions, but also a tendency to fall back on familiar styling choices, including a noticeable indigo-violet color bias.
For developers using the model directly, the interaction pattern is fairly clear. The model appears to do best when the task is scoped, the constraints are explicit, and the environment can provide feedback. In practice, that means giving it concrete requirements, preserving interface expectations, and letting it run or inspect the system when possible.
The model performed better when it could move through a visible loop of change, inspection, and correction rather than trying to solve everything in one shot. That fits the broader pattern we saw throughout the tests: more direct output, less wasted tokens, and better results on bounded tasks.
Our team's testing revealed that the model followed instructions too literally, especially when the prompt was poorly structured, lacked detail, or had weak underlying concepts. In those cases, the model often did not repair the direction on its own. It tended to execute the request as written, even when a more experienced collaborator might have paused, clarified, or challenged the premise.
That means the prompt quality has a bigger effect on the result than developers expect. The model looks strongest when the request is specific about the intended behavior, the constraints, and the success criteria.
A vague or internally inconsistent prompt can lead the model to generate a rapid response, but that output is more likely to mirror the prompt's existing weaknesses rather than correct them.
A noteworthy focus of GPT-5.5 is efficiency. While this is harder to measure with benchmarks than performance in reviews, it emerged as one of the most distinct trends in our testing. The model was often less verbose and surfaced visible progress quickly. This suggests the new version requires fewer tokens for equivalent tasks compared to previous models, a benefit that is difficult to isolate in a single benchmark figure.
This is especially relevant for agent harnesses that depend on repeated iterations to converge on the right answer. In systems that follow OpenClaw-like patterns, or any workflow where an agent has to plan, act, inspect, retry, and refine over many cycles, token inefficiency compounds quickly.
If the model can stay concise while still being effective, it can reduce the amount of token-heavy overhead in those longer loops. For teams building on external services or agent platforms, that can mean more room for iteration before token usage starts to drag down the workflow.

GPT-5.5's primary strengths lie in the developer workflow, specifically excelling at: identifying more substantive issues than the previous model, implementing focused changes without broad refactoring, and effectively self-correcting after initial errors.
For teams evaluating tools like CodeRabbit, the more defensible claim is better signal per review than baseline, not universally lower review volume. For developers using the model directly, the pattern is just as clear: give it a scoped task, make the constraints explicit, and let it verify its work against the actual system.
Get started with CodeRabbit, connect your repo, get your first AI review in minutes. Free to try, no credit card required.



