

Atsushi Nakatsugawa
March 12, 2026
2 min read
Gemini 3.1 Pro for code-related tasksの意訳です。
実際のところ、開発者はプルリクエストに残されたコメントを通じてAIコードレビューを体験します。つまり、実際の問題をどのくらいの頻度で見つけるか、どのくらいノイズを発生させるか、そしてそのフィードバックがどの程度実行可能かです。
これらの質問に答えるため、GoogleのGemini 3.1 Proと、CodeRabbitのエージェント的PRレビューワークフロー向けに調整されたOpenAIとAnthropicモデルの独自ブレンドである内部レビューベースラインとの比較ベンチマークを実施しました。
意図的にバグを注入した実際のプルリクエストを使用して、検出率だけでなく、レビューコメント自体の構造と品質を測定しました。結果は明確なトレードオフを明らかにしています。Geminiはより少なく集中的なコメントを残し、高いS/N比を持ちますが、全体として発見するバグの数は少なくなります。

私たちのベンチマークでは、特定の既知のエラーパターンが対処されなければならない実際のGitHubプルリクエストで構成された内部データセットを使用しています。各エラーパターン(EP)には、問題のグラウンドトゥルース記述があります。
モデルがEPに「合格」するのは、そのレビューコメントの少なくとも1つが、注入されたバグの根本原因に直接対処するか、具体的な修正を提案するか、実行可能な方向性でリスクを明示的に特定する場合です。
25の難しいPRのスイートを使用し、それぞれに既知のエラーパターン(EP)を仕込みました。スコアリングは以下に焦点を当てています。
実行可能なコメントのみ:投稿されたコメント(追加の提案や差分外のメモは除く)
EP PASS(コメントごと):コメントがEPを直接修正または指摘する
重要なコメント:EP PASSまたは別の重大/クリティカルな実際のバグのいずれか
精度:EP PASS ÷ 総コメント数
S/N比:重要 ÷(総数 - 重要)
比較対象:
Gemini 3.1 Pro
CodeRabbit Production(CodeRabbitのエージェント的PRレビューワークフロー向けに調整されたOpenAIとAnthropicモデルの独自ブレンド)

Gemini 3.1 Proは、カバレッジで4.3ポイント遅れています。実行可能なコメントを24%少なく生成しながら、ターゲットに到達する割合がわずかに高くなっています(33.3%対29.8%)。純粋なカバレッジでは、ベースラインが優位です。
ベースラインのnitpickレベルのコメントは、メインコメントを超えて2つの追加EP(+8.7pp)を検出しますが、GeminiはnitpickコメントでEPを検出しません。

Geminiは、重要なコメント率が高く(77.8%対71.9%)、S/N比が優れています(3.5対2.6)。そのコメントは深刻な問題として分類される可能性が高くなります。ベースラインと比較して、比例的に軽微なコメントが少なくなります。コメントあたりのシグナル品質では、Geminiが先行しています。
ほとんどのベンチマーク記事は、合格率と精度で終わります。しかし、この記事は違います。すべてのコメントにトーン分類を実行して、各モデルがどのようにコミュニケーションするかを測定し、意味のある違いを発見しました。
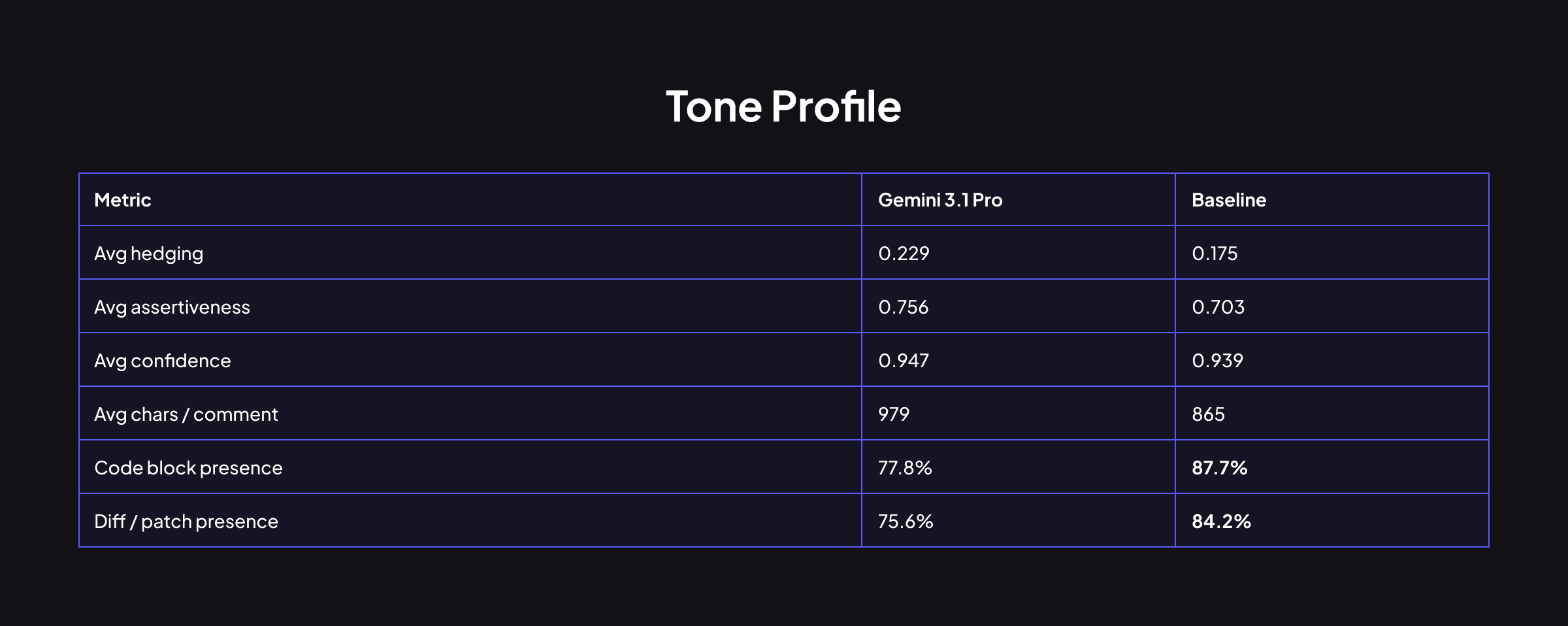
Geminiはより慎重(0.229対0.175)ですが、同時により断定的(0.756対0.703)で、より自信に満ちています(0.947対0.939)。これは矛盾していません。Geminiがフレーミングを柔らかくする(「検討することをお勧めします…」など)一方で、技術的結論は決定的なままであるスタイルを反映しています。そのコメントは平均的に長いですが、ベースラインと比較してコードブロックや差分パッチを含む可能性は低くなります。
トーンメトリクスを合格/不合格の結果で分割すると、強いパターンが現れます。
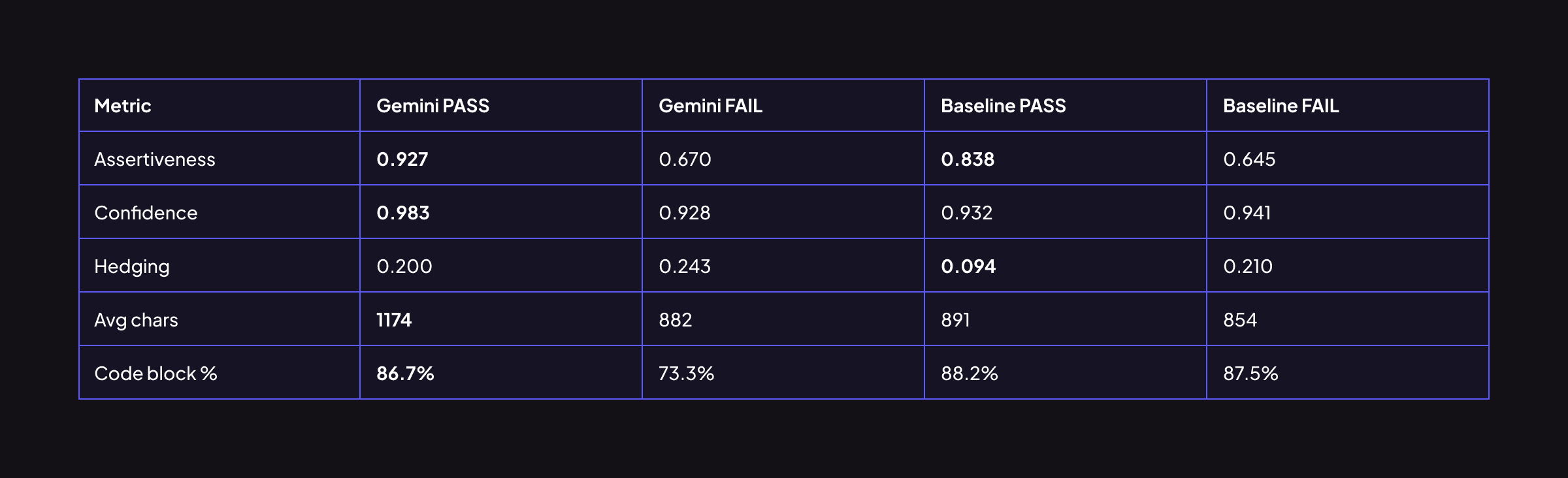
Geminiの合格コメントは、不合格コメントよりも38%断定的で、33%長くなっています。 Geminiがバグを捕捉すると、測定可能なほど決定的で、詳細で、コードを多く含みます。その内部信頼シグナルは信頼できます。Geminiが断定的で長い場合、おそらく正しいです。
ベースラインは同じ方向性のパターンを示しますが、ギャップは狭くなります。合格コメントと不合格コメントがより似ています。ベースラインのコードブロック率は、コメントが合格するか失敗するかにかかわらずほぼ同じです(88.2%対87.5%)。ベースラインは労力を広く分散させるのに対し、Geminiは集中させる傾向があります。
これは、これらのモデルを使用するチームにとって実用的な意味を持ちます。Geminiのコメントトーンはコメント品質の有用なプロキシです。 簡潔で慎重なGeminiコメントは、断定的でコードの多いコメントよりも懐疑的に見る価値があります。ベースラインのコメントは、精度に関係なく、より均一にフォーマットされています。

ターゲットに的中したときのコメント密度:両方のモデルが合格するEPにおいて、Geminiの合格コメントはより具体的になる傾向があります。平均的な合格コメントは1174文字で、典型的なベースラインの合格コメント(891文字)よりも約32%長く、症状ではなく根本原因により集中しています。

並行性とスレッディング(9 EPで56%対78%):これが重大なギャップです。9つのエラーパターンは並行性バグ、ロックの誤用、タイミング依存性、競合状態、ライブロックをカバーしていました。Geminiは5つを検出し、ベースラインは7つを検出しました。このデータセットの支配的なカテゴリでの22ポイントのギャップが、カバレッジの差を引き起こしています。
Gemini 3.1 Proは、より高品質で集中的なコメントを生成し、より良いS/N比を持ちますが、全体として検出するバグは少なくなります。3.5対2.6のS/N比は、Geminiのレビューを読む開発者が低品質のコメントに時間を無駄にする可能性が低いことを意味します。
しかし、ベースラインの65.2%に対して60.9%のEP検出率では、より多くの実際のバグが検出されずに残ります。並行性バグが重大なリスクであるコードベースでは、このギャップは重要です。
今後の評価全体で追跡する価値のある発見が1つあります。Geminiの内部トーン調整は強力です。 その断定性スコアは、コメントが根本的な問題に対処する可能性があるかどうかについてのシグナルを提供しているようです。
とはいえ、これらの発見には範囲があります。ベンチマークは、Python、TypeScript、C/C++、混合言語のGitHub Actionsコードベースにまたがる5つのリポジトリの25のエラーパターンをカバーしていますが、エラー分布は並行性バグに大きく偏っています(25 EPのうち9つ)。これは、Geminiが最も苦戦する領域であり、ギャップが最も広い領域でもあります。OOP、トランザクションセマンティクス、または他のバグが支配的なコードベースでは、結果が異なる可能性があります。特にトーン調整の発見は、コメントが正しい可能性が高いという信頼のソースとして扱う前に、より広範なエラー分布で検証する必要があります。
評価実施日:2026年2月24日。ベースライン:Gemini 3.1 Proに対して評価された25の難しいPRの内部ベースライン。GPT-5.1によるトーン分類。グラウンドトゥルースエラー記述に対する独立したLLMジャッジによるコメントごとの合格/不合格の判定。
CodeRabbitを試してみませんか? 14日間の無料トライアルをご利用ください!


