

David Loker
December 05, 2025
7 min read
December 05, 2025
7 min read
共有
When we published our earlier article on why users shouldn't choose their own models, we argued that model selection isn't a matter of preference, it's a systems problem. This post explains exactly why.
Bringing a new model online at CodeRabbit isn't a matter of flipping a switch; it's a multi-phase, high-effort operation that demands precision, experimentation, and constant vigilance.
Every few months, a new large-language model drops with headlines promising “next-level reasoning,” “longer context,” or “faster throughput.” For most developers, the temptation is simple: plug it in, flip the switch, and ride the wave of progress.
We know that impulse. But for us, adopting a new model isn’t an act of curiosity, it’s a multi-week engineering campaign.
Our customers don’t see that campaign, and ideally, they never should. The reason CodeRabbit feels seamless is precisely because we do the hard work behind the scenes evaluating, tuning, and validating every model before it touches a single production review. This is what it really looks like.
Every new model starts with a hypothesis. We begin by digging into what it claims to do differently: is it a reasoning model, a coding model, or something in between? What’s its architectural bias, its supposed improvements, and how might those capabilities map to our existing review system?
We compare those traits against the many model types that power different layers of our context-engineering and review pipeline. The question we ask isn’t, “is this new model better?” but, “where might it fit?” Sometimes it’s a candidate for high-reasoning diff analysis; other times, for summarization or explanation work. Each of those domains has its own expectations for quality, consistency, and tone.
From there, we start generating experiments. Not one or two, but dozens of evaluation configurations across parameters like temperature, context packing, and instruction phrasing. Each experiment feeds into our evaluation harness, which measures both quantitative and qualitative dimensions of review quality.
This phase takes time. We run models across our internal evaluation set, collecting hard metrics that span coverage, precision, signal-to-noise, and latency. These are the same metrics that underpin the benchmarks we’ve discussed in earlier posts like Benchmarking GPT-5, Claude Sonnet 4.5: Better Performance, but a Paradox, GPT-5.1: Higher signal at lower volume, and Opus 4.5: Performs like the systems architect.
But numbers only tell part of the story. We also review the generated comments themselves by looking at reasoning traces, accuracy, and stylistic consistency against our current best-in-class reviewers. We use multiple LLM-judge recipes to analyze tone, clarity, and helpfulness, giving us an extra lens on subtle shifts that raw metrics can’t capture.
If you’ve read our earlier blogs, you already know why this is necessary: models aren’t interchangeable. A prompt that performs beautifully on GPT-5 may completely derail on Sonnet 4.5. Each has its own “prompt physics.” Our job is to learn it quickly and then shape it to behave predictably inside our system.
Once we understand where a model shines and where it struggles, we begin tuning. Sometimes that means straightforward prompt adjustments such as fixing formatting drift or recalibrating verbosity. Other times, the work is more nuanced: identifying how the model’s internal voice has changed and nudging it back toward the concise, pragmatic tone our users expect.
We don’t do this by guesswork. We’ll often use LLMs themselves to critique their own outputs. For example: “This comment came out too apologetic. Given the original prompt and reasoning trace, what would you change to achieve a more direct result?” This meta-loop helps us generate candidate prompt tweaks far faster than trial and error alone.
During this period, we’re also in constant contact with model providers, sharing detailed feedback about edge-case behavior, bugs, or inconsistencies we uncover. Sometimes those conversations lead to model-level adjustments; other times they inform how we adapt our prompts around a model’s quirks.
When a model starts to perform reliably in offline tests, we move into phased rollout.
First, we test internally. Our own teams see the comments in live environments and provide qualitative feedback. Then, we open an early-access phase with a small cohort of external users. Finally, we expand gradually using a randomized gating mechanism so that traffic is distributed evenly across organization types, repo sizes, and PR complexity.
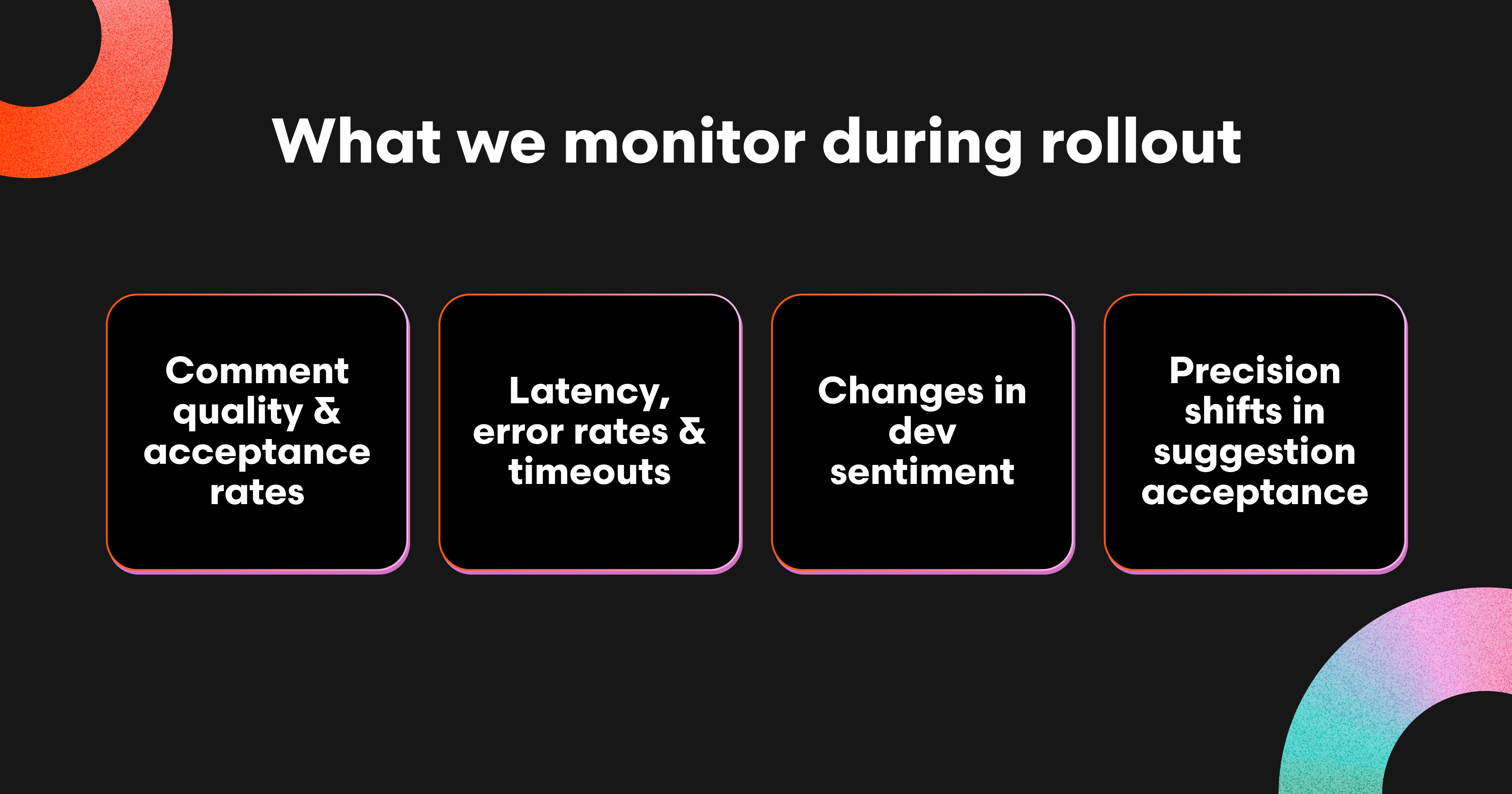
Throughout this process, we monitor everything:
Comment quality and acceptance rates
Latency, error rates, and timeouts
Changes in developer sentiment or negative reactions to CodeRabbit comments
Precision shifts in suggestion acceptance
If we see degradation in any of these signals, we roll back immediately or limit exposure while we triage. Sometimes it’s a small prompt-level regression; other times, it’s a subtle style drift that affects readability. Either way, we treat rollout as a living experiment, not a switch-flip.
Once a model is stable, the work doesn’t stop. We monitor it constantly through automated alerts and daily evaluation runs that detect regressions long before users do. We also listen, both to our own experience (we use CodeRabbit internally) and to customer feedback.
That feedback loop keeps us grounded. If users report confusion, verbosity, or tonal mismatch, we investigate immediately. Every day, we manually review random comment samples from public repots that use us to ensure that quality hasn’t quietly slipped as the model evolves or traffic scales.

Each new model we test forces us to rediscover what “good” means under new constraints. Every one comes with its own learning curve, its own failure modes, its own surprises. That’s the reality behind the promise of progress.
Could an engineering team replicate this process themselves? Technically, yes. But it would mean building a full evaluation harness, collecting diverse PR datasets, writing and maintaining LLM-judge systems, defining a style rubric, tuning prompts, managing rollouts, and maintaining continuous regression checks. All of this before your first production review!
That’s weeks of work just to reach baseline reliability. And you’d need to do it again every time a new model launches.
We do this work so you don’t have to. Our goal isn’t to let you pick a model; it’s to make sure you never have to think about it. When you use CodeRabbit, you’re already getting the best available model for each task, tuned, tested, and proven under production conditions.
Because “choosing your own model” sounds empowering until you realize it means inheriting all this complexity yourself.
Model adoption at CodeRabbit isn’t glamorous. It’s slow, meticulous, and deeply technical. But it’s also what makes our reviews consistent, trustworthy, and quietly invisible. Every diff you open, every comment you read, is backed by this machinery. Weeks of evaluation, thousands of metrics, and countless prompt refinements all in service of one thing:
Delivering the best possible review, every time, without you needing to think about which model is behind it.
Try out CodeRabbit today. Get a free 14-day trial!


