
CodeRabbit is now in the Claude Marketplace!Learn more

David Loker
November 24, 2025
9 min read
November 24, 2025
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Every new model arrives with the same promise: smarter reasoning, cleaner code, and better answers. But Opus 4.5 from Anthropic doesn’t just reason; it audits. It reads code as if returning to a system it helped design, identifying weak points and refining architecture. Where other models narrate their logic or prescribe surgical fixes, Opus 4.5 performs structured, systematic reviews that feel more like technical documentation than conversation.
We integrated Opus 4.5 into CodeRabbit’s benchmark harness to understand what makes this model distinct. The result was not higher raw intelligence or flashier prose, but discipline. This model doesn’t just find bugs; it builds context around them. It treats review as an engineering process, rather than a guessing game.


At CodeRabbit, we evaluate new LLMs using a controlled benchmark of 25 complex pull requests seeded with known error patterns (EPs) across C++, Java, Python, and TypeScript. Each comment generated by a model is scored by an LLM judge for three key factors:
Precision: Whether it correctly identifies the EP.
Important-share: The percentage of comments that are genuinely critical or major (real bugs, not style issues).
Signal-to-noise ratio (SNR): The ratio of important to unimportant comments.
Our evaluation framework, refined over multiple generations of models, combines automated LLM judging with hand validation to ensure accuracy. We also use multiple judges and repeated trials to measure consistency and understand variance. Each iteration improves the process through better prompts, refined labeling, and expanded coverage, resulting in more reliable outcomes.
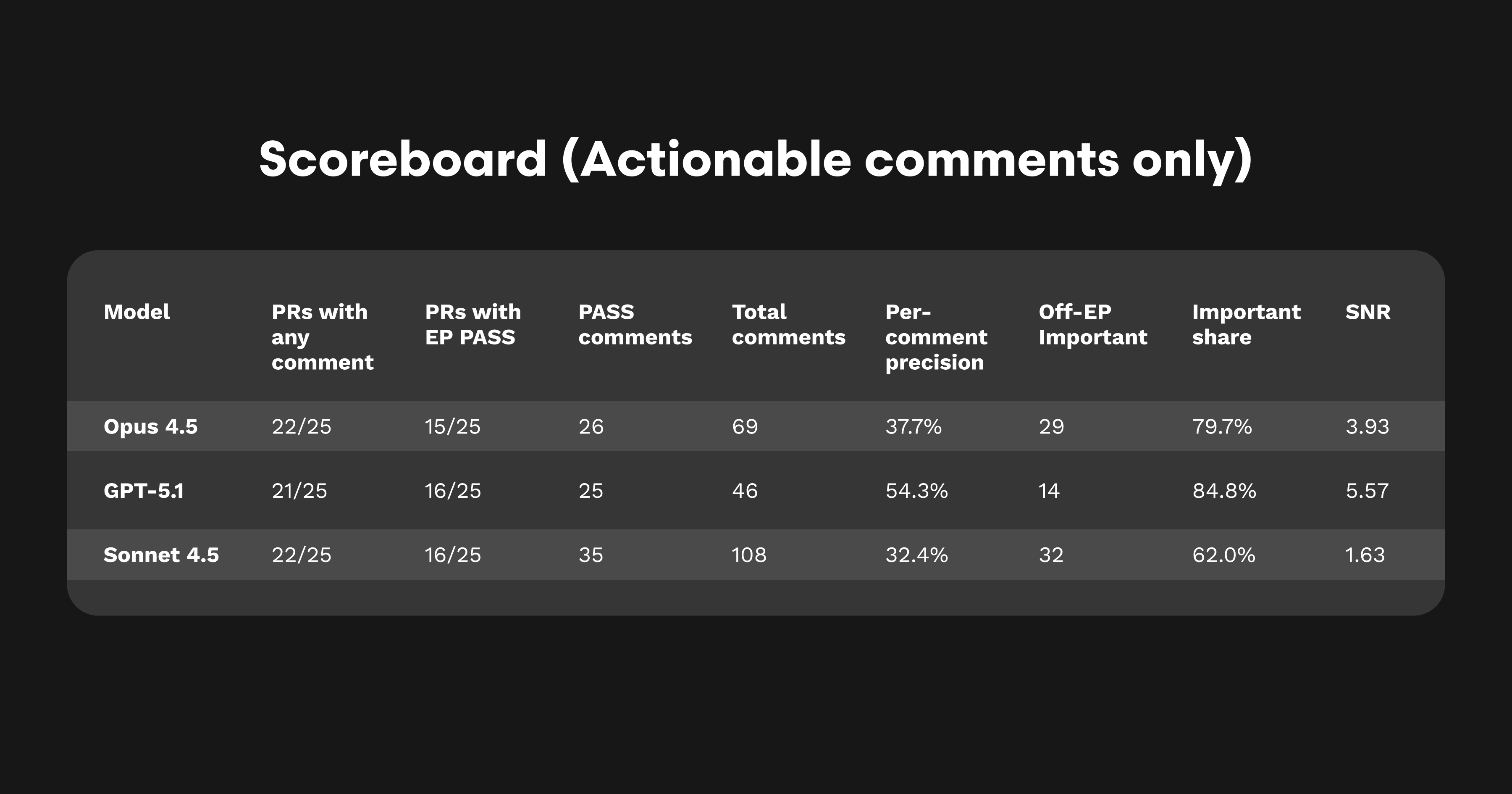
What this means: Opus 4.5 sits between Sonnet 4.5’s high-volume, verbose style and GPT-5.1’s lean, surgical precision. It delivers higher per-comment precision and a greater share of meaningful findings than Sonnet 4.5. While it recorded one fewer EP pass (15 vs. 16), that difference falls within normal variance. In several runs, Opus 4.5 matched or even surpassed both GPT-5.1 and Sonnet 4.5. The takeaway is a model that balances signal, structure, and coverage with consistent reliability.
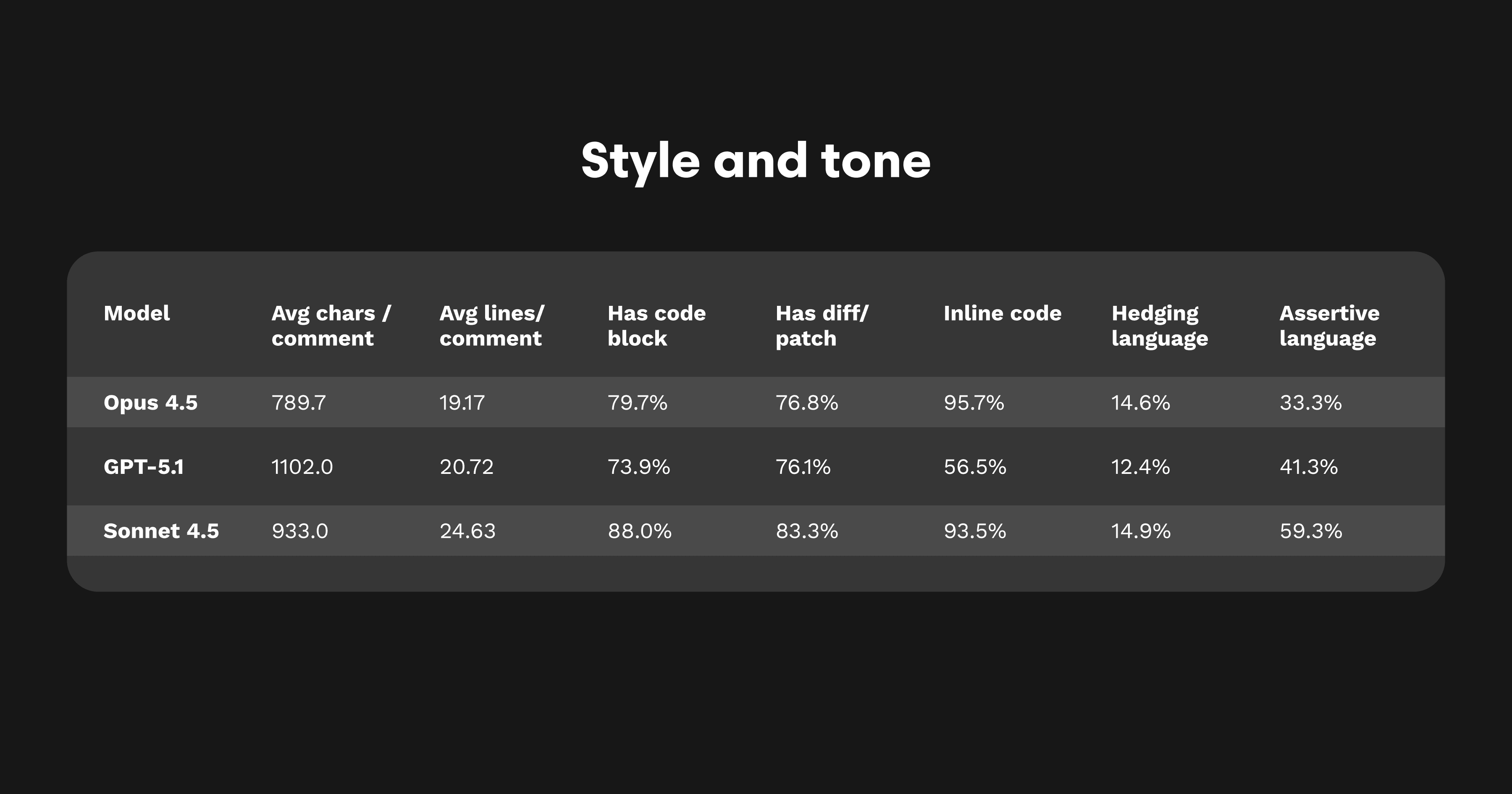
Opus 4.5’s reviews are structured, concise, and focused. With assertiveness around 33% and hedging near 15%, its tone reads as measured and professional. The balance of tone and density gives it an analytical voice that feels practical and confident. The high use of code blocks and diff patches underscores its bias toward action; it talks less and edits more.

Opus 4.5’s comments follow an architectural rhythm of headline, rationale, and diff. Nearly 80% include code blocks, and most conclude with a concise patch. Each resembles a clear bug report that specifies cause, effect, and resolution.
This structure holds across languages. Whether reviewing C++, Java, Python, or TypeScript, the cadence remains consistent, averaging 19 lines and 790 characters per comment. This uniformity simplifies automation and enhances readability. It also makes Opus 4.5 feel like a single engineer’s consistent voice across an entire codebase.
C++ (WorkerThreadPool): Detects a lost wakeup race with a three-step interleaving and a one-line diff fix.
Java (OrderService): Flags a missing volatile on a double-checked lock and provides the corrected pattern.
Python (Batch client): Replaces a synchronous HTTP client with an asynchronous equivalent to prevent blocking calls.
TypeScript (Cache manager): Identifies that Number.MAX_SAFE_INTEGER disables eviction and suggests realistic defaults.
These are concise, code-native insights, each actionable and grounded in sound reasoning.
Opus 4.5’s tone is balanced but occasionally reveals a subtle inversion: when it is wrong, it can sound slightly more certain. Although the model is generally measured, this behavioral quirk means tone alone is not always a reliable indicator of correctness. To account for this, we pair tone data with correctness metrics in evaluation summaries to maintain consistent calibration.
Opus 4.5 rarely speculates; it simply explains, even when it’s wrong.
While most models target the immediate defect, Opus 4.5 focuses on the surrounding system. Its recommendations frequently adjust lifecycles, add safety checks, or refine defaults.
Examples:
TypeScript Cache: Rewrites eviction logic, adds TTL enforcement, and updates defaults to prevent silent OOM.
Java OrderService: Replaces HashMap with ConcurrentHashMap and identifies missing ExecutorService shutdown.
Python Client Lifecycle: Adds explicit shutdown hooks for long-lived async clients.
C++ FileAccessEncrypted: Resolves a validation bug that blocked all encrypted files and improves upstream error handling.
These are not single-line fixes but systemic corrections. The model treats code as an interconnected ecosystem rather than a collection of isolated issues.
Anthropic’s Effort parameter provides direct control over how deeply the model reasons. In high-effort mode, Opus 4.5 explores every dependency path. In medium-effort mode, it trims reasoning depth to save tokens. Even with high-effort reasoning, its reviews averaged about 25% fewer output tokens than Sonnet 4.5, balancing higher per-token costs ($25 per million output tokens) with greater efficiency.
This disciplined structure pays for itself by producing fewer digressions and maintaining consistent clarity.

If Sonnet 4.5 feels like a teacher and GPT-5.1 like a decisive teammate, Opus 4.5 is the architect reviewing your PR. Its tone is calm and deliberate, never commanding. It assumes you understand the domain and aims to confirm the details. The result is feedback that reads like peer review from a systems engineer: consistent, structured, and quietly authoritative.
Opus 4.5’s voice is measured and analytical. It rarely uses dramatic language or unnecessary severity. Instead, it conveys certainty through order, concise summaries, specific evidence, and focused corrections. The tone builds trust, delivering feedback that feels like it comes from a mentor familiar with your system.
Its comments are compact yet informative. When an issue warrants detailed explanation, Opus 4.5 delivers it without excess. For simpler problems, it resolves them with brief, precise advice. This balance of detail and brevity keeps reviews readable and comprehensive.
The model’s structural rhythm of context, cause, and correction allows developers to scan quickly while retaining meaning. Developers often describe its comments as “structured snapshots” that tell a short, self-contained story: what happened, why it matters, and how to fix it.
Because Opus 4.5 avoids inflated confidence and theatrical phrasing, developers trust it more readily. It comes across as confident yet professional, firm but not forceful. When it errs, it sounds like a reasoned hypothesis instead of an overreach. That restraint, more than precision alone, makes its reviews feel professionally human.
Each comment reads like a design note. It states the invariant that failed, proposes a patch, and explains the rationale inline. The clarity is high enough that many of its comments could be pasted directly into changelogs or issue trackers without revision.
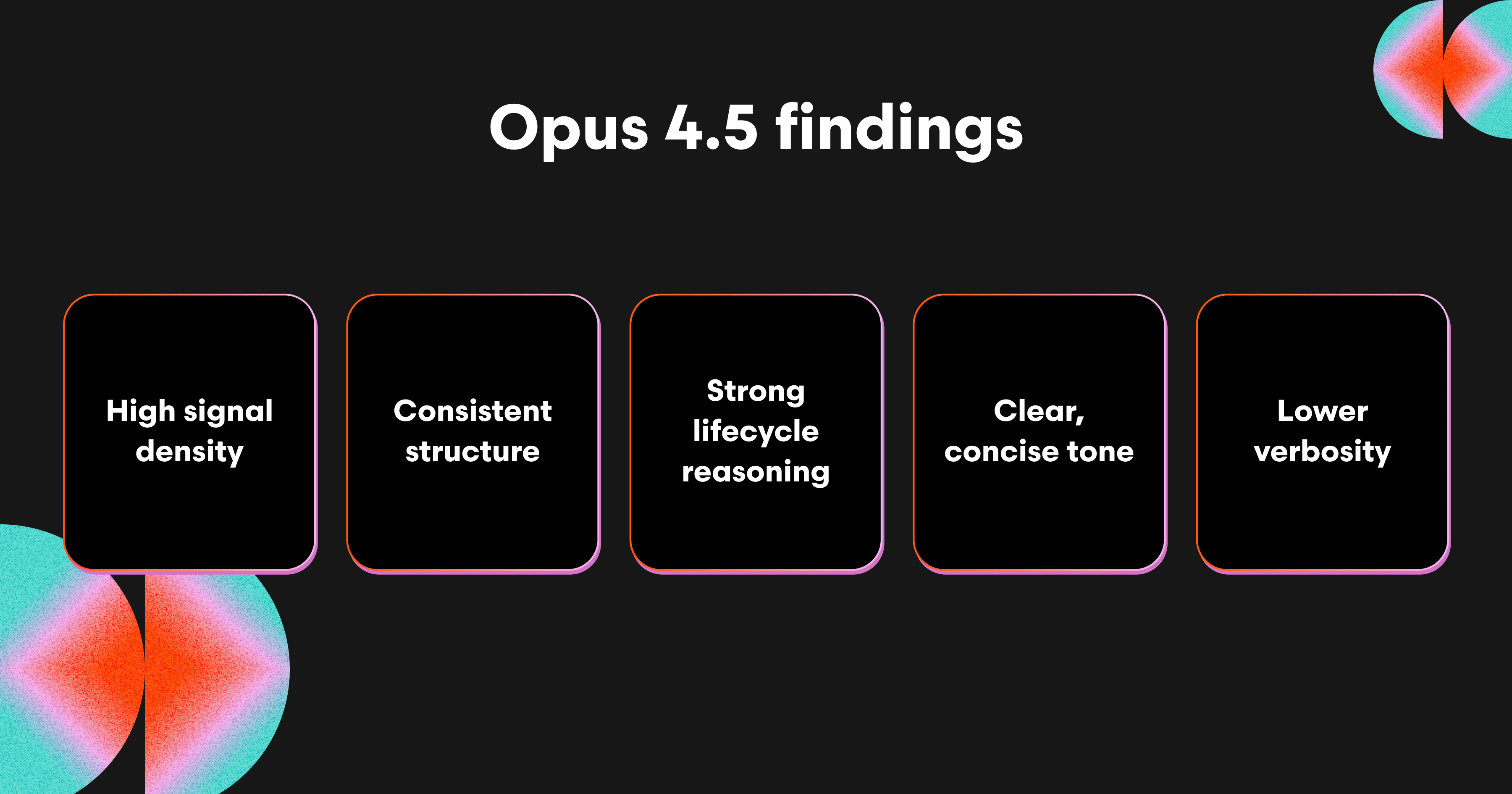
Strengths:
High signal density (≈80% important comments).
Consistent structure across languages.
Strong concurrency and lifecycle reasoning.
Clear, concise, and professional tone.
Lower verbosity than Sonnet 4.5 with more context than GPT-5.1.
Weaknesses:
Moderate precision (≈38%).
Subtle confidence inversion when incorrect.
Frequent critical or major labeling may overwhelm busy PRs.
Slight verbosity on simpler issues.
Bottom line: Opus 4.5 is the most systemic reviewer we’ve tested. Calm, structured, and exacting, it excels when reasoning breadth and architectural understanding matter more than pinpoint precision.
| Scenario | Best model | Why |
| Cross-language or high-context reviews | Opus 4.5 | Structured, consistent, strong at systemic issues |
| Tight precision or small diffs | GPT-5.1 | Higher EP precision, decisive tone, fewer false positives |
| Bulk scans, cost-sensitive workloads | Sonnet 4.5 | High coverage, lower cost per review |
Opus 4.5 no longer feels experimental; it feels engineered. Earlier models often guessed, while Opus 4.5 measures, structures, and documents. Reading its reviews feels like working with a model that truly understands how developers read.
In code review, tone defines trust. Opus 4.5’s style, measured, structured, and mechanically precise, demonstrates the maturity of reasoning: precision without pressure and confidence without ego.
Takeaway: If Sonnet 4.5 was a teacher and GPT-5.1 a teammate, Opus 4.5 is the architect returning for a design review.
Interested in trying CodeRabbit? Get a 14-day free trial.



