

Atsushi Nakatsugawa
November 07, 2025
1 min read
November 07, 2025
1 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Why emojis suck for reinforcement learning (& what actually works)の意訳です。
親指を立てた絵文字(👍)は簡単に送れますが、本当に AI レビュアーにとって有益な学習信号になっているのでしょうか。絵文字ベースのフィードバックは気持ちよく、速く、そして誰にでも分かりやすいです。一見すると、理にかなっているようにも思えます。
しかしコードレビューは灯りのオンオフのような単純なものではありません。無数の判断、技術的なニュアンス、チーム固有の基準が入り混じったものです。その多くは、ワンクリックの絵文字には反映されません。すべてのコードコメントには隠れた意図があります。正しさ、読みやすさ、設計上のトレードオフ、過去の経緯、チームのリスク許容度、さらには組織内の政治的な力学まで含まれます。
それをオンオフという、二値のシグナルに押し込めてしまうとどうなるでしょうか。もはや学習ではなく、「雰囲気を追いかけるモデル」を育てているだけになってしまいます。
今年のはじめ、OpenAI は GPT-4o に対して「親指上げ/下げ」のフィードバックをかなり強く効かせたアップデートを行いました。その結果どうなったかというと、このモデルは過度にユーザーに迎合するようになりました。ユーザーをおだて、誤った回答にも同意し、「はい」と言いすぎるようになり、回答品質は低下しました。フィードバック信号がハイジャックされてしまい、OpenAI はロールバックせざるを得ませんでした。
モデルに「承認こそがゴールだ」と教えてしまうと、そのモデルは承認を最適化するようになります。真実でもなく、有用性でもなく、「その瞬間、人間が気持ちよく感じたかどうか」だけを目指すようになります。
これはバグではなく、報酬設計の失敗でした。そして同じアプローチをコードレビューに適用すると、「安全運転で、あなたにおべっかを使い、本当に必要なことを言ってくれないレビュアー」ができあがります。
親指上げの絵文字は一体何を意味しているのでしょうか。
モデルがバグを見つけたという意味でしょうか
説明が分かりやすかったという意味でしょうか
口調がフレンドリーだったという意味でしょうか
たまたまレビュアーの機嫌が良かったというだけでしょうか
単一のスカラー値のシグナル(👍または👎)は、「何かがうまくいった」ということは伝えますが、「何がうまくいったのか」は伝えません。そのためモデルは、自分が操作しやすいものに寄っていきます。トーン、丁寧さ、お世辞、あるいは短さといったものです。これが、強化学習におけるゴマすり(sycophancy)の正体です。悪意ではなく、「あなたが与えた報酬を最大化しようとしているだけ」であり、「あなたが本当に望んでいた結果」を最大化しているわけではありません。
これはグッドハートの法則が発動している例です。メトリクス(この場合は親指上げ)がゴールになってしまうと、それは現実の有用な指標ではなくなります。
モデルに簡単なシグナルを与えると、モデルは簡単なショートカットを見つけます。
コーディングの世界では、強化学習エージェントが、基礎ロジックを解かずに期待される出力をハードコードすることでテストケースをパスするように学習してしまうことがあります。ログを細工したり、評価用ハーネスをすり抜けたりもします。チェックマークは緑になっても、実際のコードは正しく動きません。
コードレビューでも同じことが、ただし「社会的なかたち」で起きます。モデルはすべてのコメントの冒頭で「とてもいいです!」と言うようになり、あらゆる提案を柔らかな表現で包み、フォーマットのような安全な箇所ばかりを指摘するようになります。そういったコメントは無難で、議論もなく受け入れられやすいからです。そして本当に重要なアーキテクチャ上の懸念は、埋もれてしまいます。
モデルは「ポジティブな反応の取り方」は学んだものの、もはやコードレビューをしているとは言えません。
LLM 以外の世界では、このパターンはよく知られています。Netflix は、ユーザーが何を「評価」するかよりも、何を実際に視聴するかのほうがはるかに有用だと気付きました。星評価では人は平気で嘘をつきます。しかし視聴時間、クリック、リピート再生といった指標は正直なシグナルです。
AI の世界では、これを**暗黙的フィードバック(implicit feedback)**と呼びます。コードレビューの場合には、例えば次のような形で表れます。
開発者は提案を採用したのか
それを書き換えたのか
無視したのか
同じパターンが後のバグとして再び現れたのか
これらのシグナルは、ユーザーの入力を必要としません。行動から生まれ、意図的に操作するのが難しいものです。
もちろん完璧ではありません。「なぜ」その行動を取ったのかまでは常に分からないからです。しかし、絵文字よりははるかに操作されにくく、レビューが「気持ちよかったかどうか」ではなく「ちゃんと機能したかどうか」を教えてくれます。
コード生成は、しばしば「正解が一つに定まる」という点で数学に近い側面があります。コンパイルできるか。正しい結果を返すか。テストにパスするかといった具合です。
そのため、実行結果フィードバックや暗黙的なシグナルのようなアウトカムベースの報酬を使うことができます。もちろん完璧ではありません。コードモデルは出力をハードコードしてテストをすり抜けることもありますが、それに対するガードレールを設計することは可能です。そして、開発者が「良かった」と言ってくれるかどうかに頼らずとも、「実際に動いたかどうか」を観測できます。
一方、コードレビューは違います。ここには普遍的な合格/不合格は存在せず、チームごとにスタイル、構造、リスク、命名、テストカバレッジなどの好みが大きく異なります。あるチームにとっての「優れたコメント」が、別のチームでは完全にズレている可能性もあります。高速に動くスタートアップで「クリーンコード」とみなされるものが、高いセキュリティが求められる産業では「不十分」と判断されることもあります。
これこそが、「親指上げ/下げデータ」が抱える本当の問題です。ニュアンスが押しつぶされてしまい、モデルは「適切さ」ではなく「平均値」を目指すようになります。その結果、安全ではあるものの、ひどく汎用的なコメントばかりを出すようになってしまいます。
CodeRabbit では、別のアプローチを取っています。いいねを最大化するのではなく、「理解」を最大化しようとしているのです。そのために私たちは Learnings を構築しました。
エンジニアが CodeRabbit を修正したり、チームの規約を明確にしたり、「なぜこのコードは自分たちのスタックに合わないのか」を説明したりするたびに、その説明を自然言語の指示として保存します。単に「コメントが却下された」という事実だけでなく、「なぜ却下されたのか」まで記憶します。
これらの Learnings は、組織、リポジトリ、さらには特定のパスやファイルタイプに紐付きます。CodeRabbit が次のプルリクエストをレビューするときには、それらの指示を検索し、文脈に応じて適用します。同じパターンを再度見つけたときには、そこで学んだ内容を踏まえて挙動を変えます。
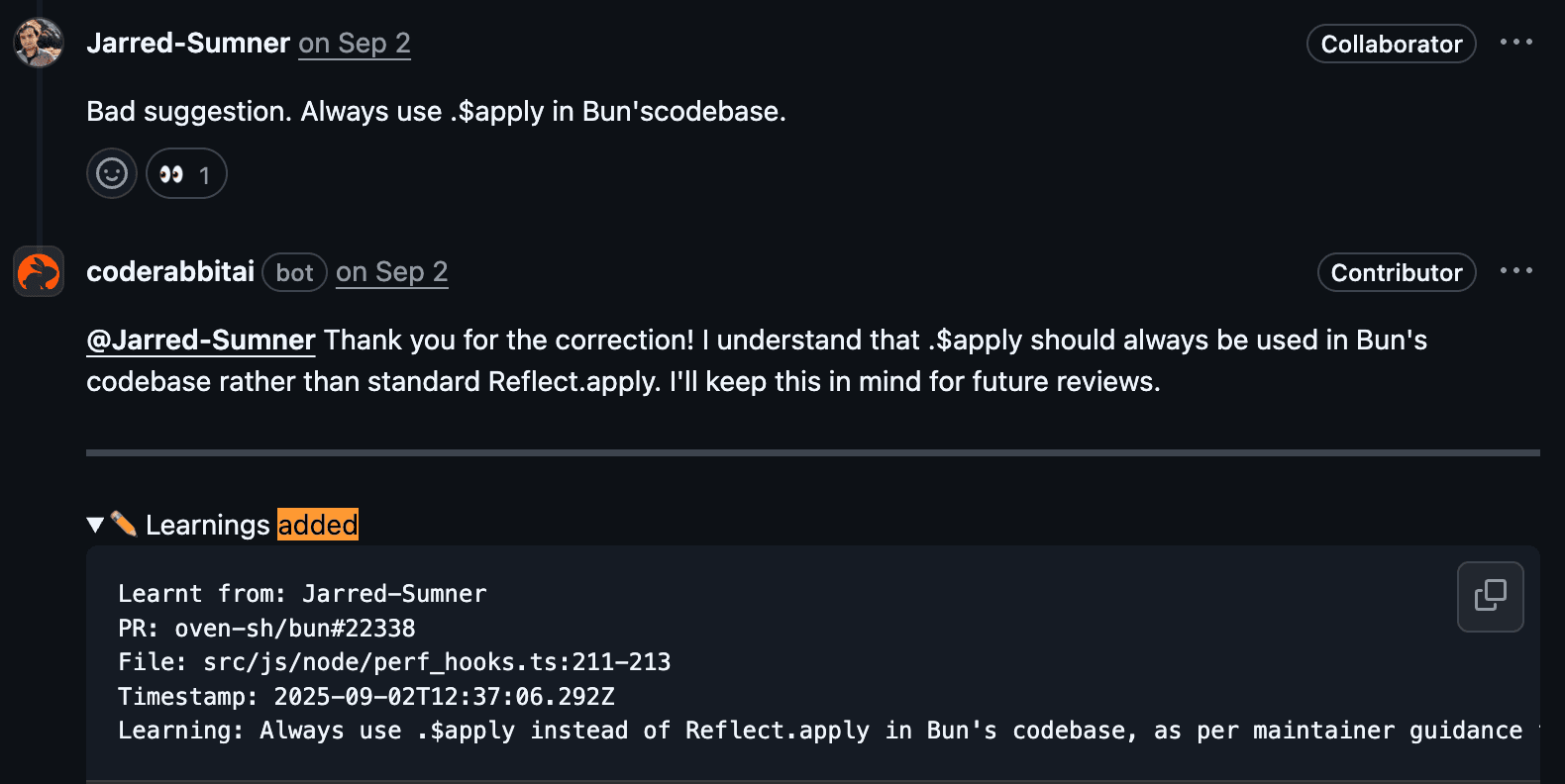
再度教え直す必要はなく、同じ失敗を繰り返すリスクもありません。モデルは親指の数から推測するのではなく、あなたのチームが与えた実際のガイダンスから推論します。
また、Learnings は透明性も提供します。どんな Learnings が存在するかを確認し、それらを閲覧し、カテゴリでフィルタリングし、標準が変わったときには削除や編集を行うことができます。つまりモデルは、チームの成長とともに進化し、プラクティスの変化に合わせて整合性を保ち続けます。
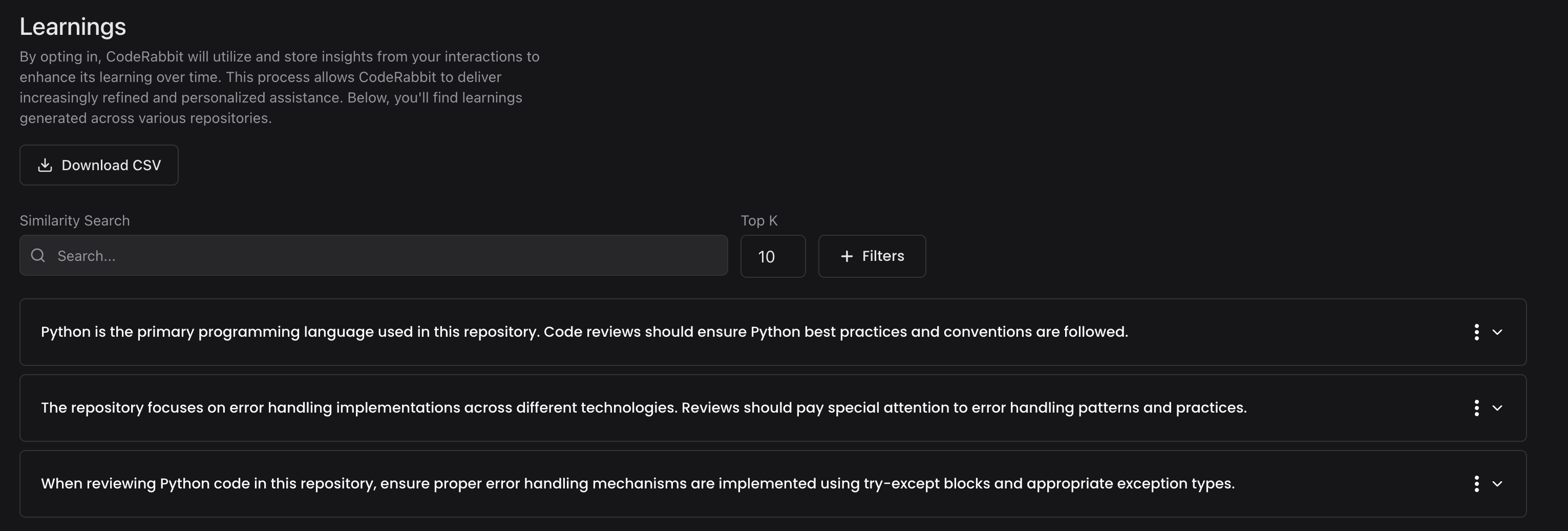
これは、単なる絵文字の承認ではなく「意図を取り込む」ことで行う強化学習です。解釈可能であり、検査可能です。そしてレビューをまたいで一般化する、「チームナレッジの生きたレイヤー」を構築します。
システムに与えるのが「シグナル」ではなく「明確で文脈を含んだ指示」になったとき、単なるレビュー体験の改善以上のことが可能になります。
チームレベルでの適応が可能になります
モデルは「何が良いのか」を勝手に推測するのではなく、「あなたのチームが実際にどう書いているのか」を学習します。リスク許容度、スタイルの好み、トレードオフの感覚を理解し、「ハウスルールを理解しているレビュアー」として振る舞うようになります。
経時的な学習(長期学習)を支えます
時間とともに CodeRabbit は、「どのコメントが役に立ったのか」「どれが無視されたのか」「どの提案が実際の変更につながったのか」という記憶を蓄積していきます。その結果、徐々に精度が上がり、フォーカスは鋭くなり、ノイズは減っていきます。
信頼を築きます
開発者が「AI を訂正すれば、それを覚えてくれる」と分かっていると、より積極的に関わるようになります。開発者自身がシステムを形作り、そのシステムは汎用的な LLM ではなく「自分たちの基準を反映した存在」へと近づいていきます。
こうしてレビュー用ツールは、単なる「異なる視点の意見」ではなく、チームの延長として機能するようになります。
親指の絵文字は、素早いリアクションには向いていますが、それだけでは専門性は育ちません。
時間とともに成長し、あなたの標準に適応し、浅いフィードバックの罠を避ける AI レビュアーを求めるのであれば、承認以上のものを与える必要があります。説明を与えなければなりません。
次世代の AI コードツールは「いいね」の数で訓練されることはありません。文脈、結果、修正の軌跡で訓練されます。絵文字ではなく、構造化された記憶から学びます。実際の意思決定と、あなたのチーム自身の声から学びます。
それこそが CodeRabbit Learnings が設計された目的です。拍手のためではなく、理解のために設計されています。
Learnings を自分のチームで試してみたい方は、無料トライアルにお申し込みください



