

David Kravets
May 07, 2026
9 min read
May 07, 2026
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Most teams want a capable teammate in Slack, one that takes real work off their plate, operates in the flow of conversation, and helps people move from question to action without forcing everyone to swivel between tools all day.
That is the real opportunity with CodeRabbit Agent for Slack. Used with intention, it becomes a shared operational layer for your engineering organization. It's part coding assistant, part research partner, part triage operator, part execution engine and, at its core, it brings the same intelligence that powers CodeRabbit's code review engine to every stage of the software development lifecycle. That means engineers get help debugging and shipping, managers get visibility into what changed and why, support teams can investigate escalations without waiting on someone to context-switch, and product managers can understand implementation implications before they file a ticket. In short, the full range of what it can do across agentic SDLC workflows goes well beyond any single role or use case.
The teams that get the most value are the ones that connect it to the right systems, establish clear norms, and build habits that compound over time.
The biggest shift is this. CodeRabbit Agent for Slack is built for the full arc of software delivery, well beyond writing code:
Some of the highest-leverage workflows have nothing to do with direct implementation at all. The agent can run daily end-to-end smoke tests and post pass/fail results to Slack every morning, automatically open pull requests for weekly dependency updates grouped by patch, minor, and major versions, and query your observability stack each morning to deliver a severity-rated health digest before standup.
But the agent is equally powerful in the moment. A product manager mid-meeting wants to know how a freshly launched feature is performing. She opens a Slack thread, asks the agent to pull a specific dashboard, and within seconds has a count of users who have adopted the feature since launch. The answer arrives in the thread where the conversation is already happening, instantly accessible to everyone in the room, with zero interruption to the people building the product.
The common thread is this. The agent handles repeatable operational work and live knowledge requests alike, so the team can focus on decisions that actually require human judgment. The value compounds across every stage of building and operating software with more shared context, less friction, and faster decisions.
The agent earns its keep through the breadth of context it can reach. CodeRabbit Agent for Slack pulls from an unusually wide surface. This includes code repositories and open pull requests, issue trackers like Jira, Linear, and GitHub Issues, documentation in Notion or Confluence, monitoring data from Datadog, Sentry, and PostHog, cloud infrastructure context from AWS and GCP, and Slack itself. And the connections ecosystem grows pretty much everyday. And when it comes to Slack, the agent pulls in Slack conversations, decisions, escalations, and handoffs that represent your team's actual working memory. Teams can extend it further through MCP servers and direct API connections.
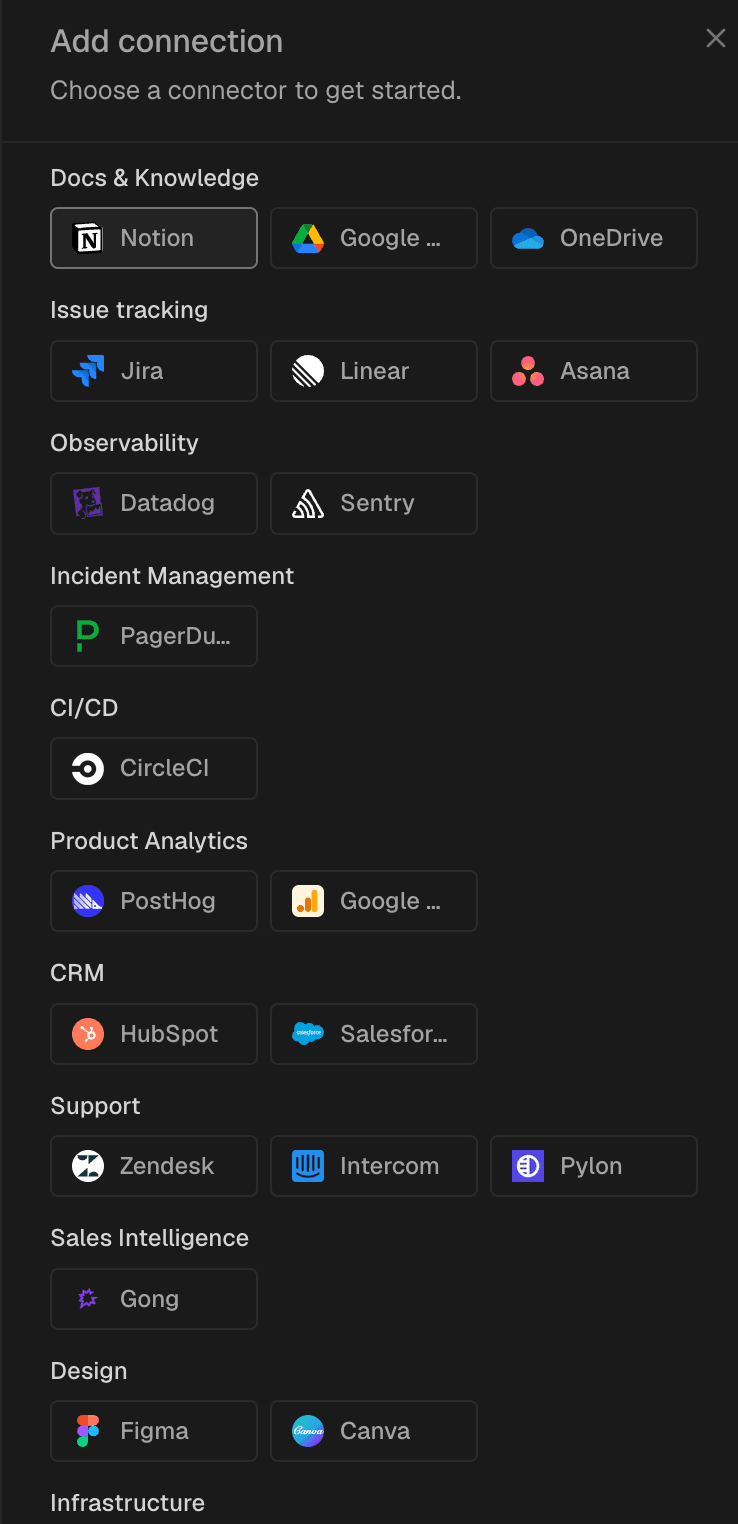
That breadth matters because a support question is rarely just a support question. It often touches product behavior, recent releases, internal docs, feature flags, and ownership boundaries. The more of that graph the agent can traverse safely, the more it can help people resolve real work instead of offering generic suggestions.
The smartest rollout starts focused, with code repositories, documentation, ticketing, and read-only observability or incident data first. Expand from there once the team sees where the agent is already proving valuable.
Good adoption starts with trust, and trust starts with clear boundaries.
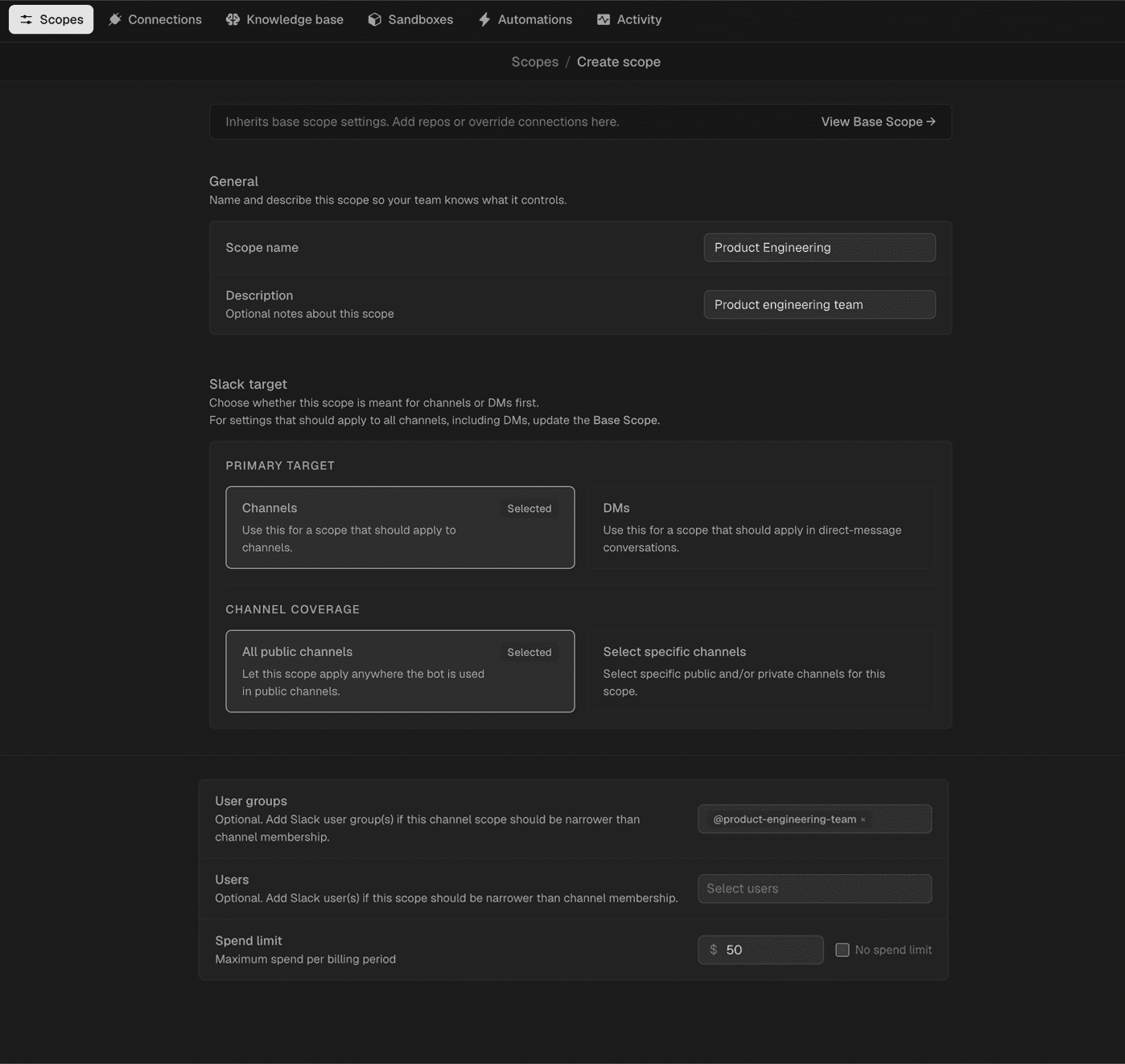
Begin with the narrowest access model that still produces useful outcomes. Read-only access alone unlocks substantial value such as code understanding, issue triage, incident context, change summaries, documentation lookups, and planning help. Write capabilities come next, introduced deliberately as the team grows comfortable with how the agent behaves. CodeRabbit's governance runs through scopes. They are bundles that define which repositories the agent can reach, which integrations it can use, which users can invoke it, and what spending limits apply. Every workspace starts with a base scope, with full attribution and auditability for every agent run.
A phased rollout works best. Start with a small pilot group, connect a focused set of tools, observe how people naturally use it, then expand based on real usage patterns. This gives the team time to establish norms, identify high-value workflows, and sharpen any review or approval expectations before the agent becomes part of daily operating rhythm.
One of the most powerful properties of a Slack-native agent is that Slack is inherently multiplayer. Questions are asked in public. Context accumulates. Decisions need to be visible. Handoffs happen across functions.
The most effective teams use CodeRabbit Agent for Slack in shared channels and threads whenever the work benefits from collective visibility. Bug triage, incident response, release readiness, spec clarification, customer issue investigation, and architectural Q\&A all get sharper when the agent's reasoning is visible to everyone involved. That visibility reduces duplicate work, makes decisions easier to audit, and means the agent's output becomes reusable. That means new team members can read an incident summary later, other functions can reference a technical explanation without asking the same questions again, and engineers stop reconstructing the same context from scratch.
Structure turns a powerful agent into a predictable one. Decide early where different classes of requests belong.
Engineering channels are a natural home for code understanding, PR context, and release questions. Support channels work well for customer issue triage because the agent can pull context from your CRM, support tickets, issue trackers, documentation, and past conversations into a single thread. Incident channels are where the agent earns some of its highest leverage by assembling timelines, summarizing logs, identifying recent changes, and proposing next debugging steps from the same thread where the alert fired. Product and planning channels can use it for issue scoping, roadmap decomposition, or turning a messy conversation into a clean technical plan the team can review before anyone starts coding.
Thread discipline matters equally. Keep each request scoped to a thread so that relevant context stays together, the conversation remains easy to follow, and future readers can understand what was asked, what evidence was gathered, and what decision was made.
The highest-leverage usage spans the entire lifecycle of building and operating software. The teams that discover this early pull ahead quickly.
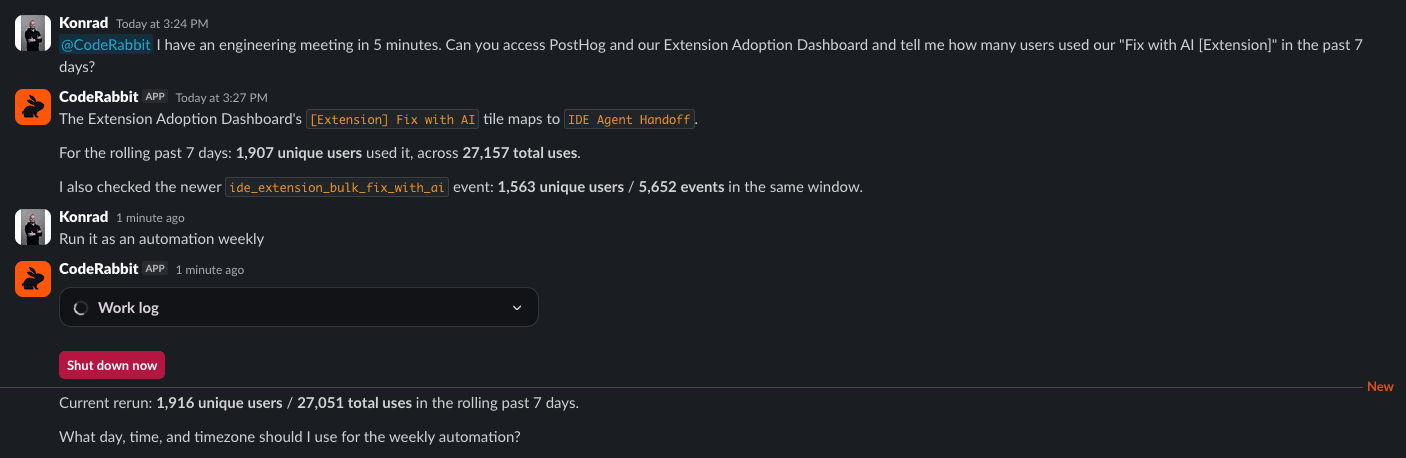
Before work starts, the agent clarifies requirements, breaks down ambiguous requests, inspects the codebase for likely touchpoints, and surfaces risks that would otherwise emerge much later. During implementation, it helps developers navigate unfamiliar modules, compare approaches, and reproduce customer bugs from tickets. For example, paste an issue into Slack, the agent reproduces it in a browser, and returns a screen recording with filed repro steps. During review and release, it summarizes what changed, identifies likely regressions, and generates changelogs grouped by features, fixes, and improvements. After release, it supports incident response, root-cause exploration, and keeps documentation in sync with what was actually shipped.
The place to establish where human judgment stays in the loop is before the agent starts opening pull requests, drafting operational recommendations, and interacting with production systems.
Anything that mutates production systems, changes critical code, or creates external-facing commitments warrants human approval before it moves forward. This is how mature teams hold velocity and control at the same time. The healthiest model is calibrated trust. Let the agent gather context quickly, compress large amounts of information, propose concrete next steps, and execute across the tools the team already uses. All the while, humans own the judgment calls, prioritization, and final approval where it counts.
Teams adopt tools because the tool solved a problem they felt this week, and the best rollouts lean into that scenario.
Introduce CodeRabbit Agent for Slack through a handful of concrete workflows that matter immediately. This may include production issue investigation, support escalation triage, codebase questions, PR understanding, release summaries, or technical onboarding. Pick the ones that are common, expensive, and easy to recognize. Once people see the agent reduce time-to-answer or take real work off a teammate's plate, adoption takes care of itself.
And bring the whole organization along. Product managers use it to understand implementation implications before filing work. Support teams use it to gather technical context before escalating. Engineering managers use it to summarize changes and understand blockers. Incident managers use it to speed up context assembly during active response. The agent becomes most valuable when the entire delivery organization operates more coherently around the same systems and the same work.
That is where the real leverage lives. Ask it for one-off answers and you capture a fraction of CodeRabbit Agent for Slack value. Instead, weave it into the collaborative fabric of how work gets understood, advanced, reviewed, and completed. That’s how the whole organization moves faster.



