
Atsushi Nakatsugawa
March 03, 2026
3 min read
March 03, 2026
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
CodeRabbit tops independent AI code review benchmark の意訳です。
AIコードレビューのベンチマークは、これまで主にコードレビューツールのベンダー自身によって公開されてきました(そして、自分たちのツールは、常に自社ベンチマークでトップになっています)。私たちは以前、なぜベンダー作成のベンチマークが、開発者がAIツールを選択する際に実際に必要とする信頼性を提供しないと考えるかについて記事を書きました。
そうした中、ついに外部の方がCodeRabbitがレビューした300,000件以上の実際のPRを対象とした、初の独立系ベンチマークを構築したことを嬉しく思います。
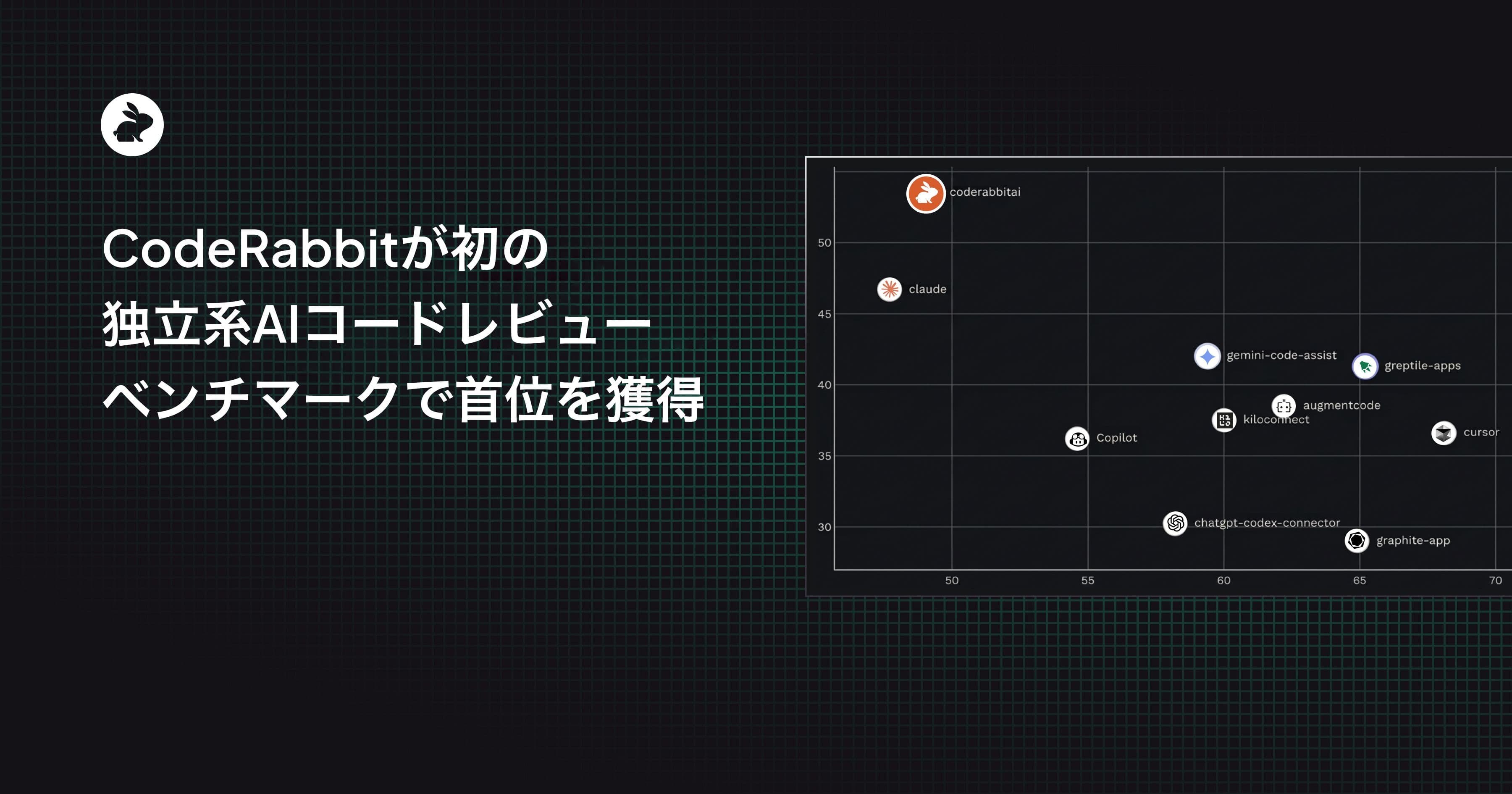
MartianのCode Review Benchは、実際の開発者の行動に基づいてAIコードレビューツールを評価する初の独立系公開ベンチマークであり、CodeRabbitが首位に立っています。彼らのリーダーボードによると、CodeRabbitは全ツール中で最も高いrecall(再現率)を持ち、次点のツールよりもほぼ15%高い値を示しています。平たく言えば、CodeRabbitは他のどのツールよりも多くの実際のバグを発見します。
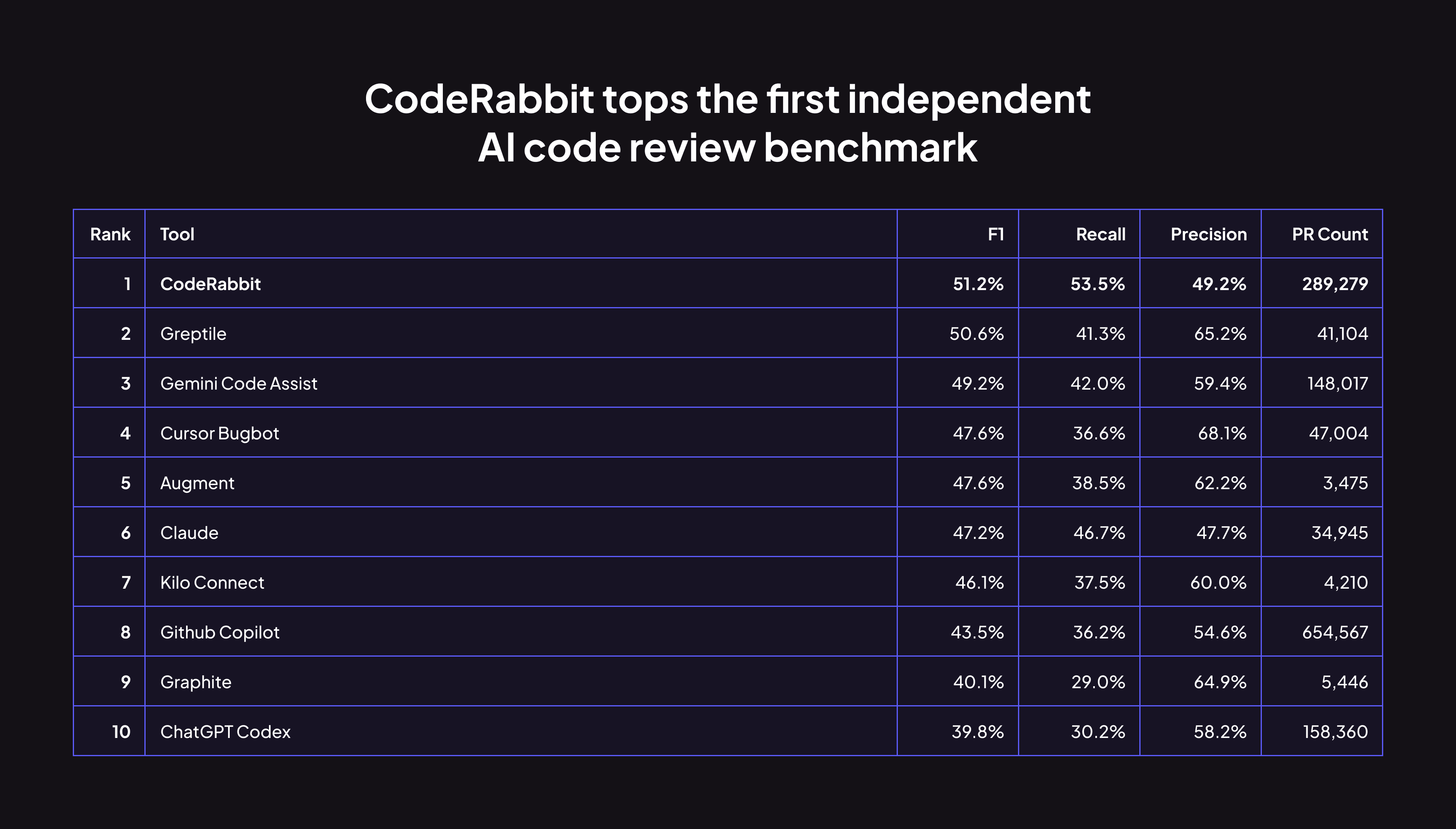
CodeRabbitはまた、最高のF1スコア(精度と再現率のバランス)を持ち、51.2%のスコアで総合チャートのトップに立っており、他のどのコードレビューツールよりも優れています。
Precision(精度)とはツールの正確性を指します。 Recall(再現率)とはツールの網羅性を指します。
CodeRabbitは両方のバランスを取り、最も正確なAIコードレビューを提供します。
Code Review Benchの結果: y軸はrecall率、x軸はprecisionを示します
Code Review Benchは、DeepMind、Anthropic、Metaのメンバーで構成される研究ラボMartianが公開した新しいベンチマークです。彼らは約数十万件のPRにわたって10個のツールを評価しました。彼らの手法とコードは完全にオープンソースです。
Code Review Benchが以前に公開されたコードレビューベンチマークと異なる点は、開発者からの実際の行動データと、探すべき既知のバグの基準ゴールドセット(後述)を含む二つのアプローチを採用していることです。
オンラインベンチマーク: オープンソースリポジトリ全体で開発者が実際に受け入れたり拒否したりするコードレビューコメントを分析します。開発者がコードレビューツールによって発見された問題を修正した場合、それはレビューコメントが有用であったというシグナルです。それを無視した場合も、それは貴重なデータとなります。
オフラインベンチマーク: すべてのコードレビューツールを同じ50個のPRに対して実行し、「ゴールドセット」と呼ばれる事前に特定されたバグのキュレーションされたセットと照らし合わせて分析します。これは制御された比較ですが、レビューコメントを実際のバグまたは偽陽性として分類するために人間のアノテーションが必要となります。
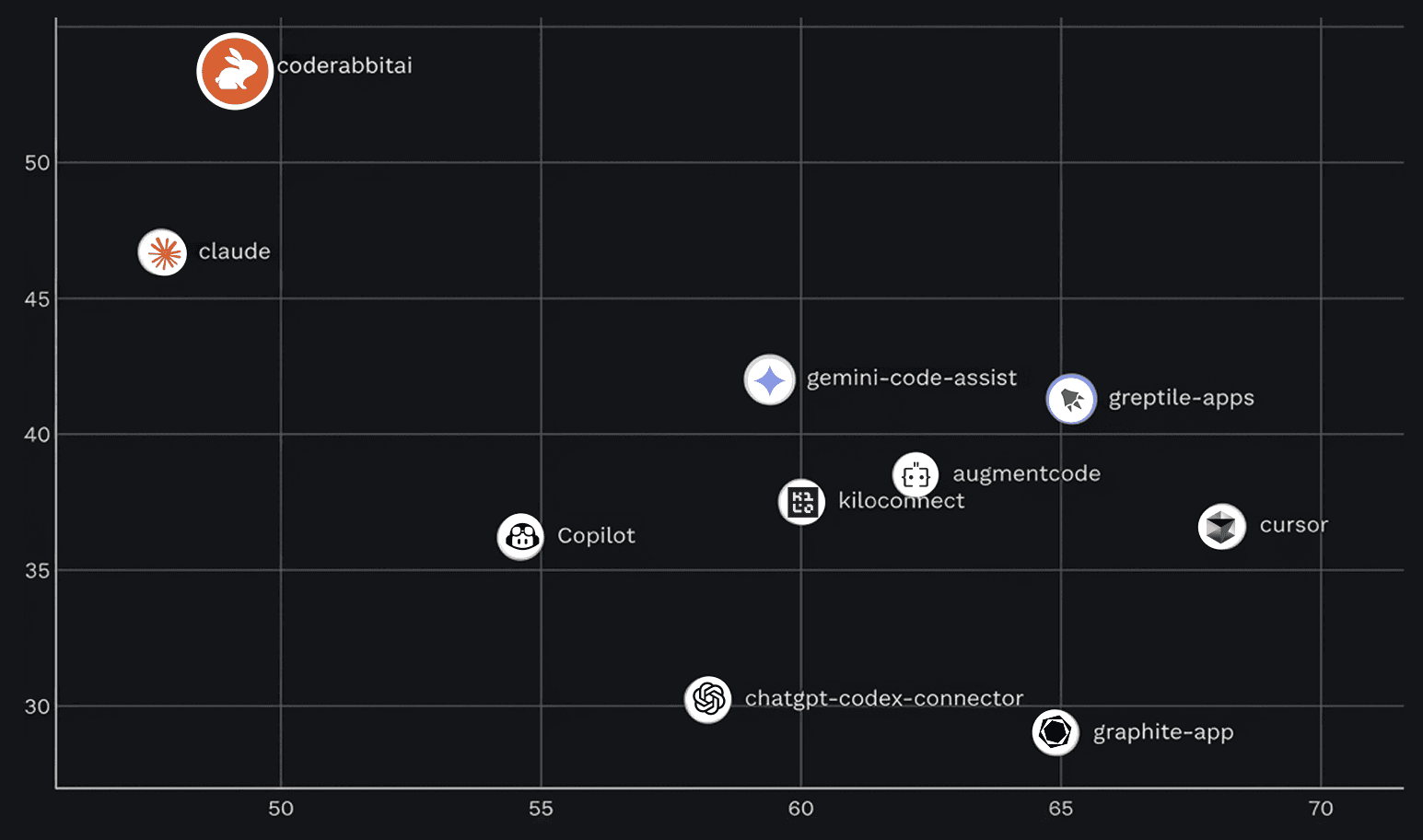
実際の開発者の行動に基づいたオンラインベンチマーク、そしてCode Review Bench自身が見出しメトリックと呼ぶものにおいて、CodeRabbitは含まれる全10ツールの中でF1スコア(精度と再現率の調和平均)で第1位にランクされています。
2026年1月〜2月に分析されたCode Review Benchの結果
Martianは、2ヶ月間にわたって約300,000件のプルリクエストでCodeRabbitのレビューを測定しました。これはデータセット内で最大規模のサンプルの一つです。これは実際のプロジェクトにおける数万人の開発者が、私たちがフラグを立てた内容に対してアクションを起こすかどうかを決定したことを表しています。
開発者はCodeRabbitの提案に対して有意な割合でアクションを起こします。49.2%の精度は、約2つのコメントに1つがコード変更につながることを意味します。これは、他のどのツールよりも高い再現率と組み合わさることで、全ツール中で最高のF1スコアにつながっています。
しかし、コードレビューにおけるPrecision(精度)とRecall(再現率)とは実際には何を意味するのでしょうか? 簡単に言えば、Precisionはツールから出された全レビューコメントのうち、真陽性の割合を測定したものです。数学的には、ツールのコメントにおける真陽性の測定値になります。ツールが100件のコメントを返し、そのうち80件が真陽性で、20件が偽陽性(誤ってバグと識別された)だった場合、その精度率は80%です。

Recallは、存在する全バグのうち、そのツールによって発見された真陽性の割合を測定したものです。数学的には、ツールのコメントにおける網羅性の測定値になります。ツールが50件のコメントを返したが、PRには実際には100件の実際のバグが存在した場合、その再現率は50%です。

コードレビューツールを比較する際、最高のコードレビューツールは最も高い精度を持つものであるという一般的な仮定があります。コメント数が少なくて精度が高い、それは直感的に良いものだと感じますよね?
しかし、CodeRabbitはこれまで、わずかに異なるアプローチを取ってきました。CodeRabbitは精度と再現率の良好なバランスを持つように特別に設計されています。私たちは、あなたが見る必要のある実際のバグを見逃すよりも、あなたが却下することを選択する実際のバグをフラグ付けすることを選びます。
これは、高い正確性(精度)だけでなく、高い正確性とより多くのバグの発見(再現率)の両方を最適化することから来ています。精度と再現率の両方を最適化することで、最も多くの実際のバグを捕捉することにつながります。
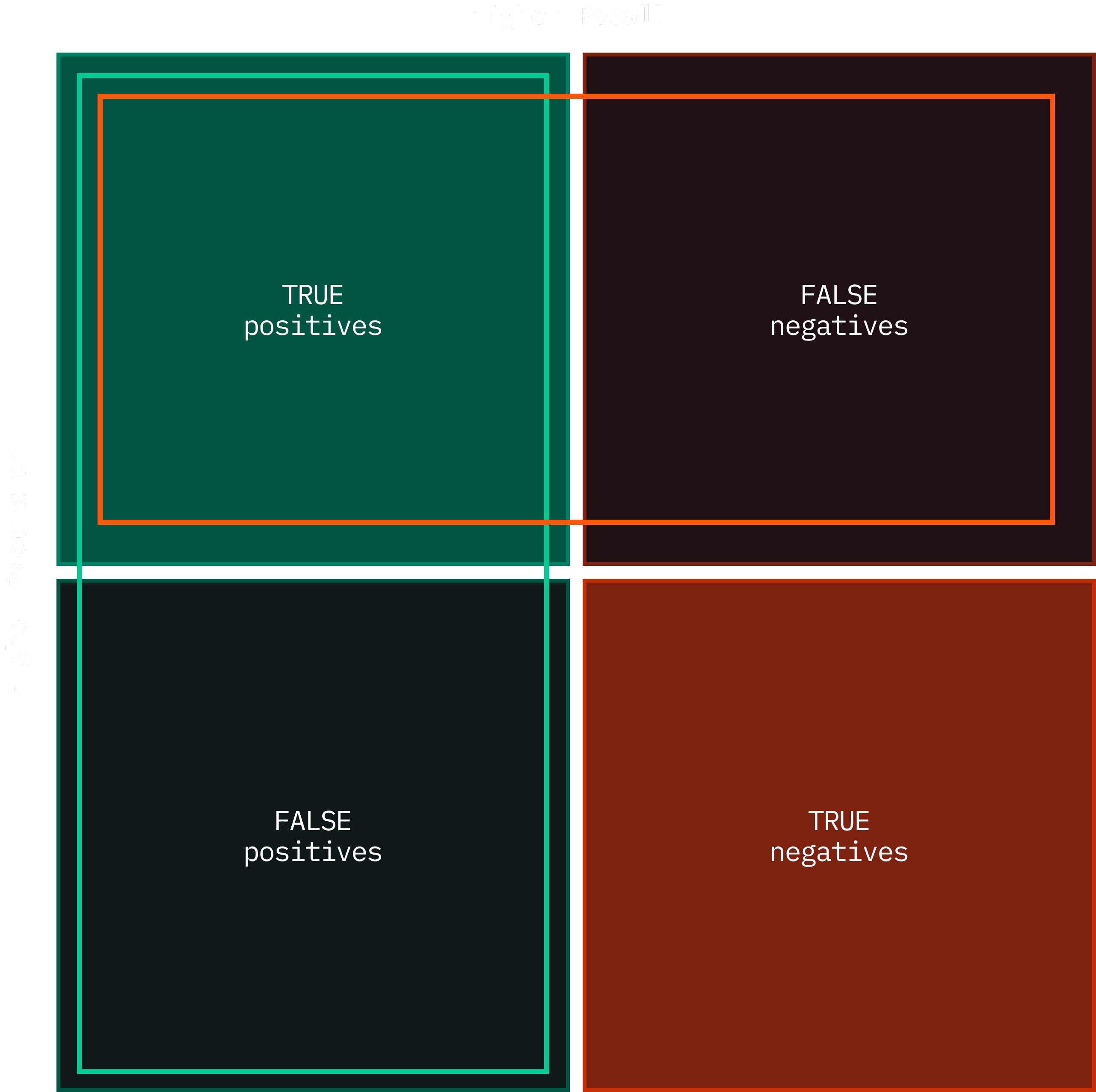
高精度、高再現率は、より多くの真陽性が発見されることにつながります。
オンラインベンチマークアプローチが重要である理由は、オフラインアプローチではコードレビューツールがベンチマークのゴールドセットに含まれていない実際の問題を発見した場合、しばしば偽陽性としてフラグが立てられるためです。CodeRabbitのような大量コメント型ツールは、ゴールドセットが予期していなかったより多くの問題を表面化させるため、再現率の高いツールに対してバイアスが生じます。
キュレーションされた「正解」のセットに依存しないことで、オンラインベンチマークはこの見落としを回避します。開発者が実際にPRで何をしたかをカウントします。彼らは、開発者がCodeRabbitのコメントに対してアクションを起こす割合が、半分の頻度でコメントするツールとほぼ同じであることを発見しました。より多くのコメントを表面化させることで、CodeRabbitは最終的により多くの重大なバグを捕捉します。

ノイズが多いツールでも、見た目以上に優れている場合があります。CodeRabbitはオンラインデータにおいて最も高い再現率(recall)を持ち、レビューされたPR数も最多です。開発者はそのコメントに高い割合で対応しており、その結果、より多くのバグが発見されています。
— Martian Labs
Code Review Benchで言及されている50個のPRのオフライン比較において、CodeRabbitは実際のPRで開発者に受け入れられたコメントを含むオンライン分析よりも低いF1スコアを示しました。
彼らは、オフラインベンチマークがオンラインデータから「大きな乖離」があり、改善が必要であることについて透明性を持っています。そして、大量コメント型ツールに不均衡に影響を与える2つの具体的な問題を説明しています。
ゴールドセットが不完全である。 オフライン比較は、他の2つのコードレビューベンダーによってキュレーションされた既知のバグのデータセットから始まりましたが、「偽陽性」としてスコア付けされたコメントの一部が、実際にはゴールドセットに含まれていなかった実際の問題であることを発見しました。
オフラインとオンラインのベンチマークは意図的に不一致になるように設計されている。 Code Review Benchは、ゴールドセットのこのような種類のギャップを特定できるように、両方を特別に構築しました。ゴールドセットを拡張し、実世界の行動と照らし合わせて較正することで、オフラインランキングがシフトすることを期待しています。
私たちは、私たちのアプローチが他のレビューツールが見逃すより多くのバグを捕捉することで実世界で機能することについて、この独立した確認を見ることができて嬉しく思います。私たちは常に、コードレビューツールの仕事は可能な限り多くの重大なバグを捕捉し、開発者にどれが重要かを決定を下せるようにすることだと信じてきました。

また、各チームのニーズに基づいて捕捉されるバグの種類を調整し、時間の経過とともにレビューを改善するための設定可能性も提供しています。CodeRabbitは、デフォルトで徹底的であるように構築されていますが、ChillとAssertiveのレビュープロファイル(少ないコメント対多いコメント)、パスベースの指示、レビューをカスタマイズするためのLearningsなどのコントロールにより、チームのノイズ耐性に合わせて設定可能です。

実際の開発者の行動に基づいたMartianのCode Review Benchは、私たちのアプローチが機能し、速くデリバリーしたい(しかし物を壊したくない)チームにとってより良い選択であることを示しています。私たちは、Code Review Benchの結果が時間の経過とともにどのように改善されるかを引き続き注視していきます。
要約: 約300,000件のPR、53.5%の再現率、そしてF1メトリックで第1位。静的な既知のバグのリストを使用したキュレーションされたラボテストではなく、実世界の開発者のシグナルに基づいています。
これがCodeRabbitが提供する価値です。
完全な結果と手法については、以下を参照してください。
CodeRabbitを試してみたいですか? 今すぐ14日間の無料トライアルを開始してください。



