
Sahil Mohan Bansal
March 03, 2026
8 min read
AI code review benchmarks have mostly been published by other code review vendors (whose tools always seem to come out on top in their benchmarks). We've written before about why we don’t think vendor generated benchmarks provide the credibility developers actually need when choosing an AI tool.
So, we’re glad to see that someone has finally built the first independent benchmark covering nearly 300,000+ real-world PRs reviewed by CodeRabbit.
Martian's Code Review Bench is the first independent public benchmark to evaluate AI code review tools using real developer behavior and CodeRabbit comes out on top. Their leaderboard shows CodeRabbit has the highest recall of any tool, almost 15% more than the next closest tool. In plain terms: CodeRabbit finds more real bugs than anyone else.
CodeRabbit also tops the overall chart with the highest F1 score (balance of precision/recall), with a 51.2% score, more than any other code review tool.
Precision refers to the accuracy of a tool.
Recall refers to the comprehensiveness of a tool
CodeRabbit balances both and delivers the most accurate AI code reviews.
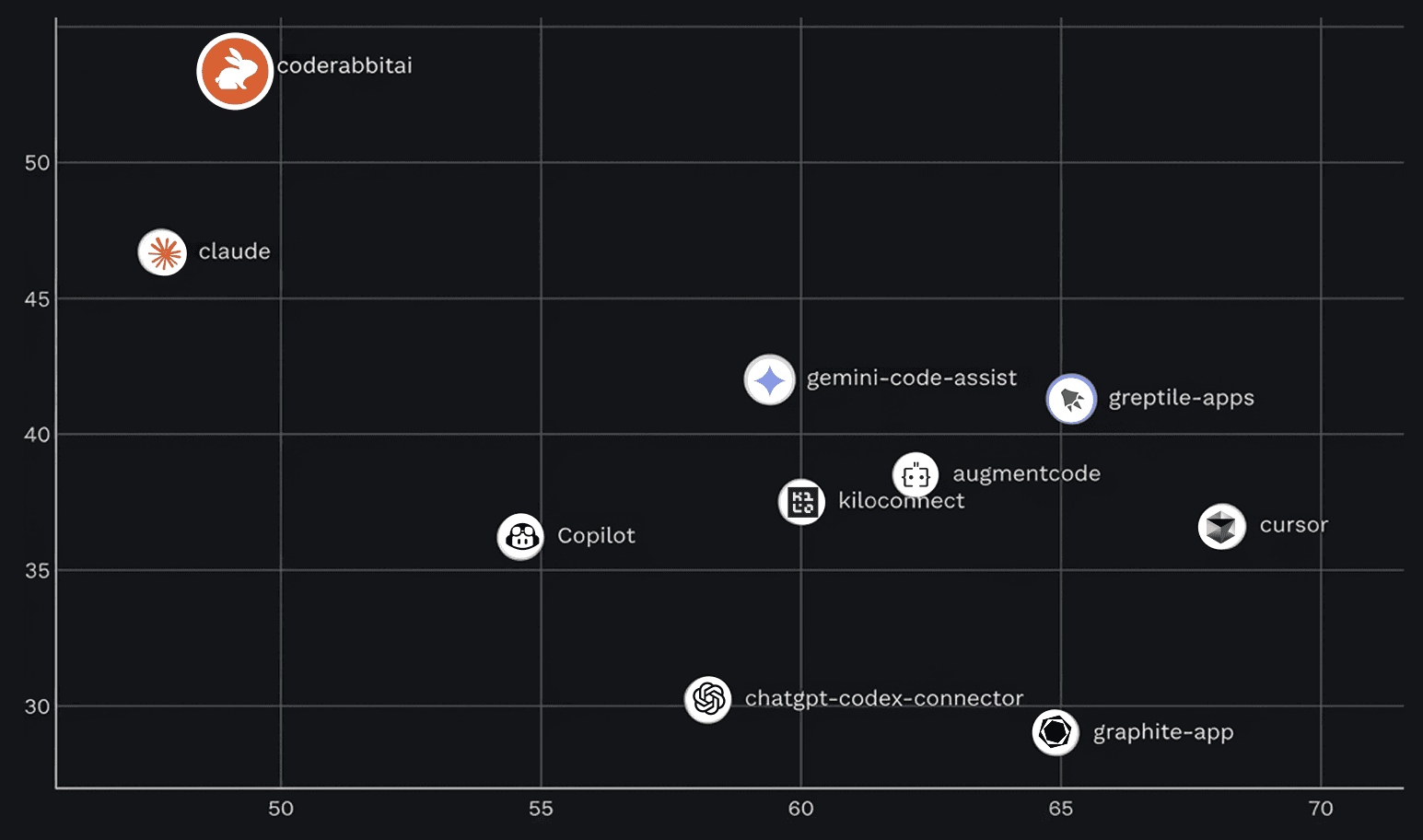
Code Review Bench results: y-axis shows the recall rate, x-axis shows the precision
Code Review Bench is a new benchmark published by Martian, a research lab with team members from DeepMind, Anthropic, and Meta. They evaluated 10 tools across approximately hundreds of thousands of PRs. Their methodology and code are fully open source.
What makes Code Review Bench different from previously published code review benchmarks is their two-pronged approach involving real-world data from developers and a base gold set of known bugs to look for.
Online benchmark: analyzes code review comments that developers actually accept or reject across open source repos. When a developer fixes an issue found by a code review tool, that's a signal that the review comment was useful. When they ignore it, that's valuable data, too.
Offline benchmark: runs every code review tool on the same 50 PRs and analyzes them against a curated set of previously identified bugs called the “gold set.” This is a controlled but influenced comparison where human annotation is required to classify a review comment as a real bug or a false positive.
In the online benchmark that’s grounded in real developer behavior, and the one Code Review Bench itself calls the headline metric, CodeRabbit ranks #1 in F1 score (harmonic mean of precision and recall) among all 10 tools included.
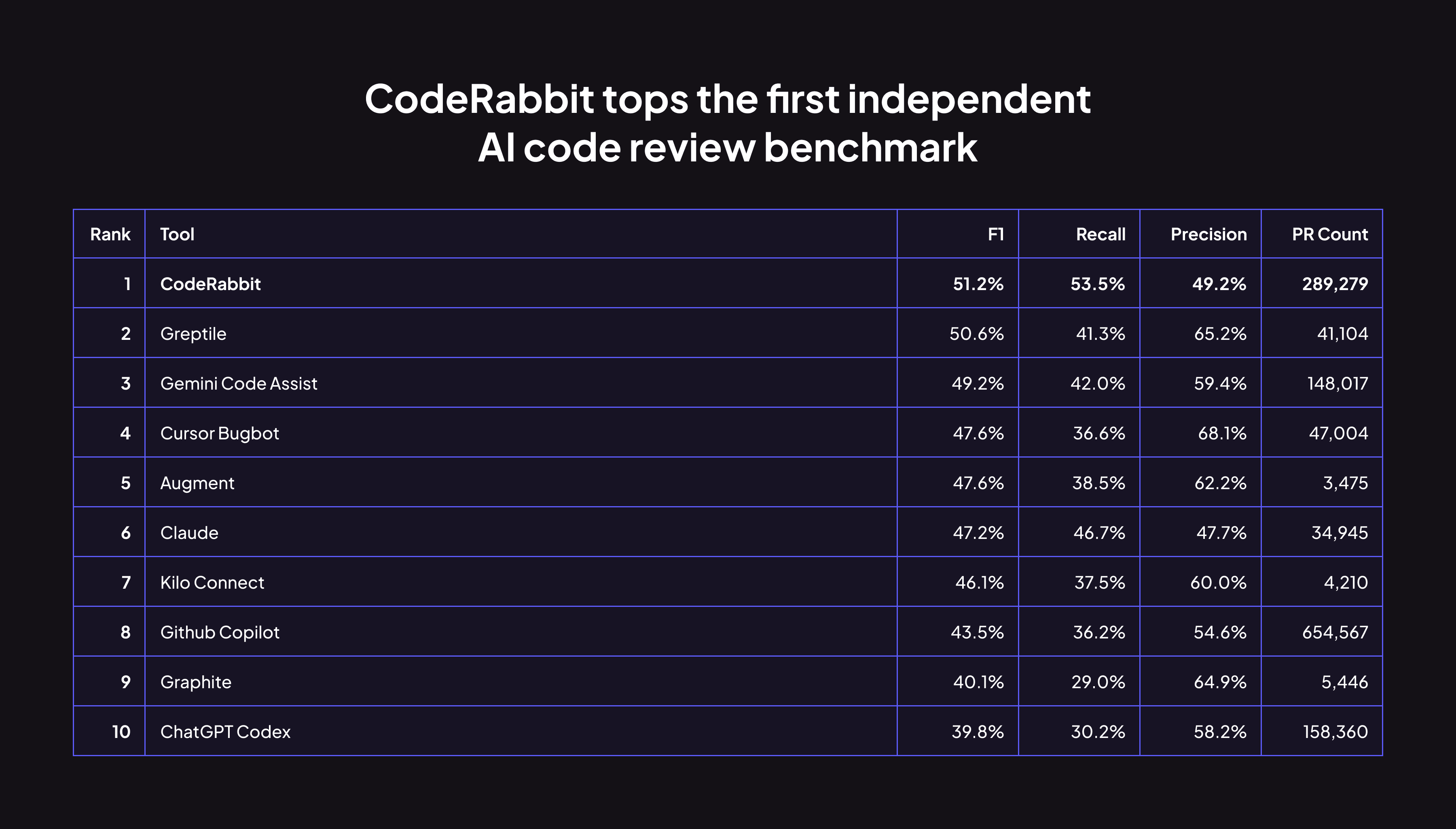
Code Review Bench results analyzed from Jan-Feb 2026
Martian measured CodeRabbit's reviews across nearly 300,000 pull requests over a 2 month period, one of the largest sample in the dataset. That represents tens of thousands of developers, on real projects, deciding whether to act on what we flagged.
Developers act on CodeRabbit's suggestions at a meaningful rate. Its 49.2% precision means roughly one in two comments leads to a code change. This, combined with a higher recall rate than any other tool, leads to the highest F1 score among all tools.
But what really are Precision and Recall when it comes to code reviews? Put simply:
Precision is a measure of the % of true positives out of all review comments from a tool. Mathematically, this is a measure of the true positives in a tool's comments. If a tool returned 100 comments and it had 80 true positives, and 20 false positives (wrongly identified as a bug) then its precision rate is 80%.

Recall is a measure of the % of total true positives found by that tool out of all bugs that exist. Mathematically, this is a measure of the comprehensiveness in a tool's comments. If a tool returned 50 comments but there were actually 100 real bugs in the PR then its recall rate is 50%.

There's a common assumption when comparing code review tools that the best code review tool is the one with highest precision. Fewer comments, higher precision, sounds intuitive right?
However, CodeRabbit has always taken a slightly different approach. CodeRabbit is specifically engineered to have a good balance between precision and recall. We would rather flag a real bug you choose to dismiss than miss a real bug you needed to see.
This comes from optimizing not just for high accuracy (precision) but for both high accuracy and surfacing more bugs (recall). Optimizing for both precision and recall leads to catching the highest number of real bugs.

High precision, high recall, leads to more true positives being found.
The reason why the online benchmark approach is important is that the offline approach often will flag a false positive when a code review tool finds a real issue that the benchmark's gold set doesn't include. High-volume tools like CodeRabbit simply surface more issues that the gold set didn't anticipate leading to bias against tools with higher recall.
By not relying on a curated set of "correct” answers, the online benchmark sidesteps this oversight. It counts what developers actually did in their PRs. They found that devs acted on CodeRabbit's comments at roughly the same rate as tools that comment half as often. By surfacing more comments CodeRabbit ultimately catches more critical bugs.

In the 50-PR offline comparison mentioned in Code Review Bench, CodeRabbit showed a lower F1 score than the online analysis that included comments accepted by devs in real PRs.
They are transparent that the offline benchmark has "significant divergence" from the online data that needs to be improved. They describe two specific problems that affect high-volume tools disproportionately:
The gold set is incomplete. The offline comparison started with a dataset of known bugs curated by two other code review vendors but they found some comments that were scored as "false positives" were actually real issues the gold set didn't include.
Offline and online benchmarks are designed to disagree. Code Review Bench built both specifically so they could identify these kinds of gaps in the gold set. As they expand the gold set and calibrates against real-world behavior, they expect the offline rankings to shift.
We are glad to see this independent confirmation that our approach works in the real-world by catching more bugs that other review tools miss. We've always believed that the job of a code review tool is to catch as many critical bugs as possible and trust developers to decide which ones matter.

We also allow for configurability to tune the kinds of bugs caught based on each team’s needs and improve reviews over time. CodeRabbit is built to be thorough by default while also being configurable for your team’s noise tolerance with controls like Chill vs Assertive review profiles (fewer vs. more comments), path-based instructions, and Learnings to customize your reviews to the issues you want surfaced.

Martian's Code Review Bench, grounded in real developer behavior, shows that our approach works and is the better choice for teams who want to ship fast (but not break things). We’ll continue to watch how the Code Review Bench results improve over time.
In summary: nearly 300,000, PRs, 53.5% recall rate, and #1 in F1 metrics. Not on a curated lab test using a static list of known bugs but based on real-world developer signals.
That's what CodeRabbit is built for.
Explore the full results and methodology:
Interested in trying CodeRabbit? Start your 14-day free trial today.