
CodeRabbitがClaude Marketplaceに登場!Learn more

Atsushi Nakatsugawa
June 24, 2026
1 min read
June 24, 2026
1 min read
共有
AI pair programming in the agentic SDLC: When review becomes the bottleneckの意訳です。
コーディングエージェントとのペアは、かつてのエクストリームプログラミング(XP)の実践に、より速いパートナーが加わったもののように見えます。しかしこの類似は誤解を招きます。役割は反転し、次のステップにリスクが潜んでいるのです。
エージェント時代のソフトウェア開発ライフサイクル(SDLC)では、AIコーディングエージェントが実装タスクを引き受けて人間は舵取りをし、レビューし、何をリリースするかを決めます。従来のペアプログラミングでは、一方がドライバーとなり、もう一方がナビゲーターを務めます。ペアの相手がエージェントになると、あなたはドライバーをやめます。エージェントがキーボードを握り、あなたは常にナビゲーターになるのです。
ReplitのCEOであるAmjad Masad氏は、ナビゲーターモデルでその境界線を引いています。旧来のアシスタント型のツールは、あなたをドライバーのままにしておきますが、エージェントはそれをひっくり返します。Masadはこの新しい関係を明快に言い表しています。
「速いのはAIの仕事だが、優れているのはあなたの仕事だ」
このスローガンは、エージェントのスループットにおいて「優れているのはあなたの仕事」が何を意味するのかを計算してみるまでは、まっとうに聞こえます。エージェントがコードの大半を書くようになると、レビューがマージゲートになります。あなたはざっと目を通すようになり、欠陥がすり抜け、ベロシティはかつてないほど良く見える一方で、安定性は損なわれていきます。1人のエンジニアが複数のエージェントとペアを組むと、ナビゲーターの役割はいっそう難しくなります。そして、コードを書いたエージェントが、それを判断する唯一の存在であってはならないのです。
この反転は4つの動きとして展開し、そのいずれもが同じ人物、すなわちレビュアーに降りかかります。
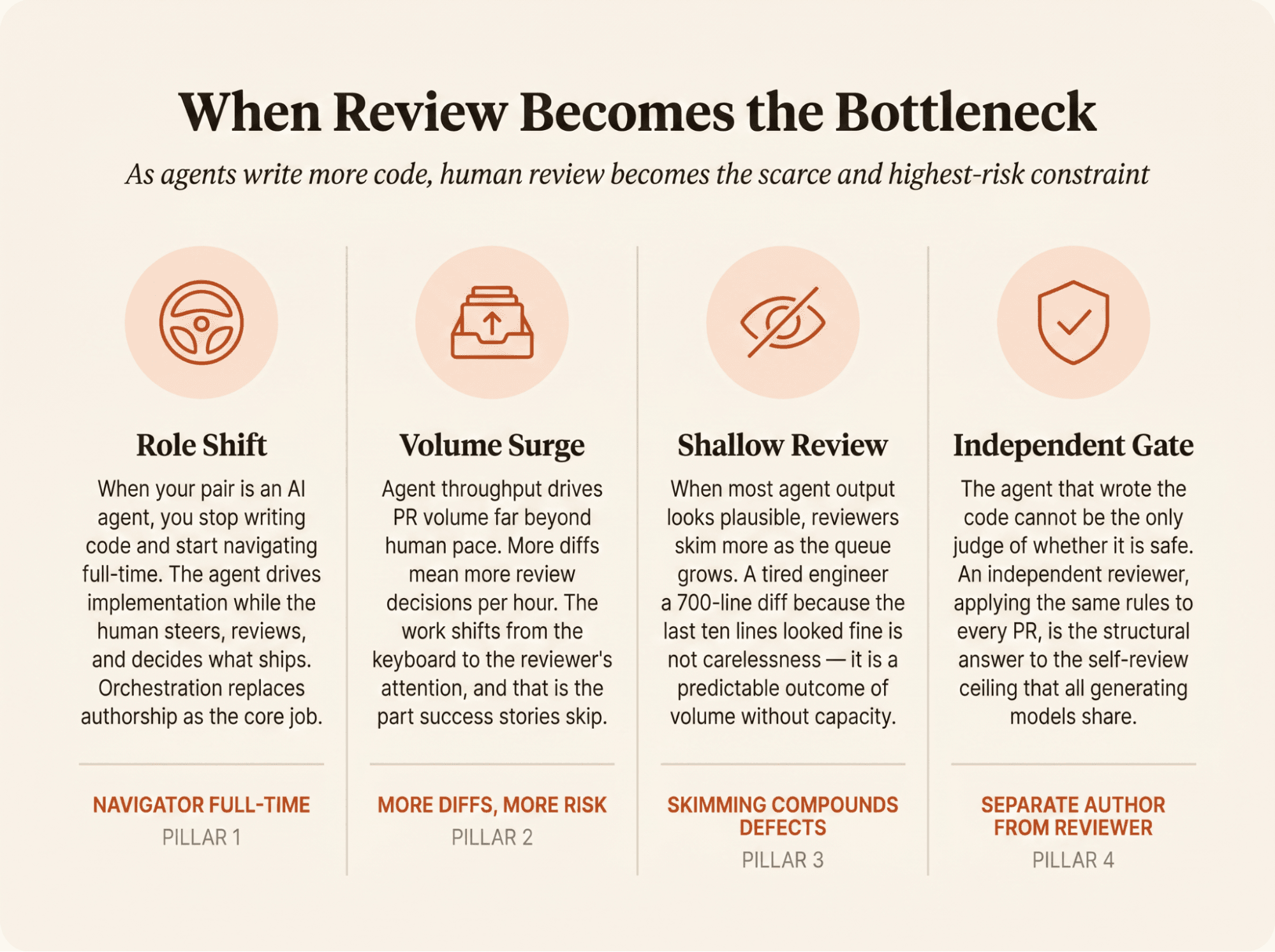
仕組みはシンプルですが、結果はそうではありません。あなたはタイピングをやめ、指示を出すようになります。タスクを委任すると、エージェントがコードを書き、あなたはその結果がマージするに足るほど良いかどうかを判断します。オーケストレーションが著述に代わってあなたの主な仕事になり、タイピングに代わって監督があなたの中心的な役割になります。良い指示書を書き、エージェントの出力を読み、それが見逃したエッジケースを捉えること、いまやそこにあなたの時間が費やされます。
月ごとにマージされるPRは増え続けており、3,500万件から4,320万件へと伸び、2025年にはコミット数が9億8,600万件を超え、前年比25%増となりました。開発者の役割はオーケストレーションと検証へと移りつつあり、そこでは直接書くコードは減り、生成された成果物をリリースできるだけ信頼できるものにすることに、より多くの時間を費やすようになります。
コードが増えれば、差分も増え、レビューの判断も増えます。仕事はキーボードからレビュアーの注意力へと移りました。そしてそここそが、成功事例が語り飛ばす部分なのです。
疲れたシニアエンジニアが、最後の10行が問題なさそうだからという理由で700行のエージェントの差分を承認するとき、レビューは気づかないうちに破綻します。
もっともらしい出力こそが罠です。エージェントが生み出すものの大半が正しそうに見えると、良い体験がレビュアーの警戒心を薄れさせます。品質が落ちるのに、レビュアーが不注意になる必要すらありません。キューが伸びるにつれて、より頻繁にざっと目を通すようになるだけで十分なのです。

キューは、エージェントが登場する前からすでに制約でした。Taskrabbitは、コーディングエージェントを導入する前に、マージまでの時間を25%削減し、平均のPRサイクルを10日から7日に短縮しました。これは、人間の作業量であってもレビューがサイクルタイムのゲートになりうることを示しています。エージェントの作業量は、そのゲートを支配的な制約にします。そして負荷のかかった支配的な制約こそが、ざっと目を通すことが始まる場所なのです。
CodeRabbitの470件のPRのレビューでは、AIが共同執筆したPRあたり10.83件の問題が見つかったのに対し、人間だけのPRでは6.45件で、PRあたりの指摘は1.7倍でした。PRあたりの指摘が増えるということは、各パスで捉えるべきものが増えるということです。しかもそれは、各パスがちょうど浅くなっていくときに起こります。大きな変更は小さな変更よりも正直にレビューするのが難しく、差分が機械的に反復的であるときはなおさらです。エージェントは大きくて似たような見た目の変更を生み出すのが得意で、チームがバッチサイズを制約しレビュアーの注意力を守らないかぎり、浅いパスを招いてしまいます。
DevOps Research and Assessment(DORA)は、AIの導入がより弱いデリバリーの成果と関連していることを明らかにしました。その2024年のレポートは、AI導入の25%増を、デリバリースループットの推定1.5%減とデリバリー安定性の7.2%減に結びつけました。DORAはまた、バッチサイズが大きいとレビューが遅くなり、システムの不安定さを生みやすいことも明らかにしました。AIによって開発者がはるかに速くコードを生成できるようになるからです。
2025年、DORAの追跡レポートは、スループットは回復しているものの、安定性は依然として悪い方向に動いていることを示しました。
開発者はすでに信頼の問題を感じています。およそ5万人の回答者のうち、46%はAI出力の正確さを積極的に信頼していません。これは2024年の31%から上昇しています。最も多くレビューをしている人々が出力を最も信頼していないため、レビュー中心のワークフローは、キューがスピードを報いる中でも懐疑心を保ち続けなければなりません。
1体のエージェントとペアを組むなら、リアルタイムでナビゲートできます。6体を動かすなら、リアルタイムのナビゲーションは失われます。では、監督はどこへ行くのでしょうか。
並行するエージェントの作業は、監督のパターンを変えます。あなたの義務はそっけないままです。動くコードを届ける責任は、依然としてあなたにあります。しかしフィードバックループは、もはや1つの連続したペアリングセッションではありません。それはタスクの引き継ぎ、差分、コメント、そしてマージの判断の連なりになります。
ペアリングの比喩は、多数のエージェントを扱う規模では成り立たなくなります。1体のエージェントなら、その作業を見守り、継続的に舵取りできます。複数になると、セッションは孤立し、各エージェントが残した成果物から意図を再構築しなければなりません。いまやライブのペアリングよりも、非同期の引き継ぎのほうが重要です。各エージェントは次のステップのために十分に構造化されたコンテキストを必要とし、各差分はレビュアーが本当の判断を下せるだけの十分な説明を必要とします。
多数のエージェントを扱う規模では、差分こそが監督の行われる場所になります。あなたはもはや、エージェントがタイプするのを見ながらすべての誤った方向転換を捉えることはできません。90パーセンタイルの指摘は、そのリスクを具体的に示します。AIが共同執筆したPRでは26件の問題があったのに対し、人間だけのPRでは12.3件で、2.11倍の差があります。それらの問題を差分だけから捉えられるかどうかは、差分がそれ単体では持っていないもの、すなわちその変更が何をするはずだったのかをレビュアーに伝えるコンテキストにかかっています。
ドリフト(逸脱)は、忘却の代償です。チームの働き方についての、共有されコミットされた記録がなければ、すべてのエージェントセッションはゼロから始まり、試行錯誤によってあなたの規約を再発見することになります。
共有されたコンテキストがなければ、エージェントはプロジェクトの規約から逸脱し、古い間違いを繰り返し、同じ基準をあなたに何度も説明し直させます。CodeRabbitのAIコードの研究では、可読性の問題がAIの共同執筆したPRで3.15倍多く見られました。これは、リポジトリ全体で積み重なっていく類の規約の逸脱です。
コンテキストエンジニアリングとは、エージェントとレビュアーが共有する指示やレビューのガイダンスを、永続的でバージョン管理された成果物として保つことを意味します。Stack Overflowのエージェント向けのコーディングガイドラインは、それを率直に述べています。
「これらのルールをすべて明示的にagents.mdに書き、標準的なリポジトリにチェックインしなさい」
それをチームの規律として扱いましょう。ルールは所有され、バージョン管理され、1人の開発者の個人的な設定に留まるのではなく、リポジトリを通じて配布されます。
レビュアーへのガイダンスとエージェントへの指示は、同じ場所を必要とします。チームがAIとともにコードを書く方法を定める基準が、あらゆるPRがレビューされる方法もまた定めるなら、自分自身を説明し直すことはなくなります。エージェントの出力は、最初からより正しいものとして届くようになります。CodeRabbitは.cursorrulesやそれに相当する指示ファイルを取り込み、CodeRabbit LearningsはPRコメントでのフィードバックを今後のレビューのガイダンスへと変えるため、今後のレビューはゼロからやり直すのではなく、過去のフィードバックを受け継ぎます。
生成したモデル自身によるセルフレビューには、構造的な限界があります。変更の作者が、その変更の唯一のレビュアーであってはなりません。
モデルは外部からのフィードバック、実行結果、あるいは別個の批評を得たときには、結果を改善できることがよくあります。それは、助けなしに自分自身の間違いを確実に見つけることとは異なります。差分を生み出したのと同じエージェントに、その差分が安全かどうかを判断させてはいけません。
セキュリティも同じ分離の要件を生みます。AIが生成したコードは、チームが適切なレビューなしに取り込むと、リスクを持ち込みかねません。チームが生成されたコードをあまりに早く受け入れると、安全でないパターン、抜け落ちたチェック、誤った前提が、人間が何が変わったのかを理解する前に下流へと流れていきます。CodeRabbitのAIによるPRの分析では、セキュリティ関連の指摘がAIのPRで1.57倍多く見られました。

Abnormal AIは、AIが生成したコードと手作業で書かれたコードの両方にわたって検証をスケールさせ、重大度が最も高いコメントで65%超の受け入れ率を達成しました。チームには独立したレビュアーが必要です。すなわち、その差分を書いておらず、あらゆるPRに同じルールを適用するレビュアーです。
CodeRabbitは独立した検証レイヤーとして機能し、生成側に自分の成果を採点させることなく、コードベース全体のコンテキストを踏まえて差分をレビューします。
コードを生成するコストがゼロに近づくと、生成された成果物の数を数えても、システムの健全性についてはほとんど何も分かりません。コード行数は、明快さよりも冗長さを報いかねませんし、PRの量は、デリバリーが遅くなっている間にも増えていくことがあります。
開発者の生産性は、単一の指標では捉えられません。測定の仕組みはスピード、品質、協働、そして成果をまとめて考慮しなければなりません。
DORAの2024年の更新では、5つ目の指標としてデプロイの手戻り率、すなわち計画外のバグ修正作業を伴うデプロイの割合が加えられました。DORAはまた、コーディング速度の向上がテスト、セキュリティレビュー、デプロイにおける下流のボトルネックに飲み込まれてしまうと警告しています。
コミットログでは示せない4つの指標を使いましょう。
これら4つを合わせて見ると、スピードがあなたにデリバリーをもたらしているのか、それとも単なる動きにすぎないのかが分かります。これらは、この記事が繰り返し立ち返る制約、すなわちレビューについての、正直なスコアボードです。
エージェントとのペアプログラミングは、レビューを希少な資源にします。ドライバーとナビゲーターが席を入れ替えるのです。多数のエージェントのスループットによって、ナビゲーター(疲れた1人の人間)がもはやさばききれないレビューキューになります。
永続的な共有コンテキストは、エージェントの足並みをそろえ続けます。より良い指標は、品質が保たれているかどうかについてあなたを正直に保ちます。コードを書いたモデルとは切り離された独立したレビュアーは、作者が自分自身の差分の唯一の判定者になることを防ぎます。
エージェント中心のレビューのために、CodeRabbitはPR、IDE、CLIにわたって、コードベースのコンテキストとチームの規約を踏まえてレビューし、すべての行がマージに値することを保証します。


