

The more AI writes the code, the more review needs independenceの意訳です。
2026年6月16日、SpaceXはAIコーディングスタートアップのCursorを600億ドルの全株式取引で買収することに合意しました。Cursorは開発者がコードを書くのを支援し、Bugbotを通じてコードレビューも行います。これを、すでにインフラ、モデル、生成機能を所有しているより広い企業スタックの中に置くと、エンジニアリングチームにとって避けられない問いが生まれます。
コードを書いた同じAIスタックを、そのコードのレビューにも信頼してよいのでしょうか。
学校では、それを自分の宿題を自分で採点することと呼びます。ソフトウェアでは、そのリスクはさらに大きくなります。コードはコンパイルできるかもしれません。エージェントは説明できるかもしれません。レビュアーは自信ありげに見えるかもしれません。しかし、自信は検証とは異なります。
チームがリリースするコードのうちAIが書く割合が増えるほど、独立したレビュアーは、品質を犠牲にせずチームが高速に進むための安全装置になります。また、AI開発に職務分離をもたらし、コード作成を支援するシステムが、そのコードをリリースして安全かどうかを判断する同じシステムにならないようにします。エンタープライズチームにとって、これはAI生成ソフトウェアをめぐって形成されつつあるガバナンスや規制上の期待に先回りする方法でもあります。
モデルは自分の成果物を判断するのが苦手です
この市場の統合は急速に進んでおり、AIコーディングプラットフォームは独自のレビュー機能を追加しています。CursorのBugBotは、コードレビューにおいて、コード生成にも使われる同じモデルファミリーであるComposer 2.5をデフォルトで使用します。利便性は確かにあります。しかし、同じスタックがコードを書き、そのコードをレビューする場合、両方の工程に同じ前提を持ち込みます。そのため、見落としを発見するよりも、同じ見落としを繰り返す可能性が高くなります。
ある研究では、Self-Correction Blind Spotを示す大規模言語モデルは、自分自身が生成したエラーの修正を求められたとき、平均64.5%の失敗率になることがわかりました。別の分析では、生成されたコードは、独立したモデルでテストされた場合よりも、同じファミリーのモデルでテストされた場合に9〜17ポイント高い割合で合格しました。
同じような学習を共有するモデルは、死角も共有しがちで、Homogenization Trapに陥ることも多いため、自分の出力をチェックするモデルは、それを承認しやすくなります。
AI生成コードの量を考えると、この問題は無視しにくくなります。業界データでは、AIコーディングに起因する2026年のGitHubコミット数は前年比14倍になったとされ、プルリクエストで見つかる重大な問題は40%増加しています。さらに、コードに漏えいしたシークレットは81%増加しており、AIが人間のコード理解を5〜7倍の速度で追い越しているという説明可能性のギャップもあります。
コードレビューは本番環境に反映する前の最後のチェックポイントとして機能します。そのチェックポイントは、同じモデルがコードを生成し、それを承認する場合には信頼できません。
コンプライアンスフレームワークもこの方向へ進んでいます
変更の作成者とレビュアーを分離することは、新しい考え方ではありません。これは、金融が何十年も信頼を扱ってきた方法から借りた、確立されたガバナンスの実践です。
財務記録の作成者とレビュアーが同じインセンティブを共有していたエンロンやワールドコムの不祥事の後、サーベンス・オクスリー法(SOX法)は、外部監査人と会計担当者を分離することを企業に求めました。この分離が機能したのは、問題の周辺を監査するのではなく、利益相反を根本から取り除いたからです。
今日は良い実践に見えるものが、要件に近づき始めています。多くのエンタープライズバイヤーがベンダーに求めるAICPAのフレームワークであるSOC 2も、この問題を扱っています。Control CC8.1は変更管理を規定し、職務権限分離(SoD: Segregation of Duties)を求めています。その原則は、変更を作成した当事者が、独立したレビューなしにその変更を承認し、本番環境へ反映してはならないというものです。
今日、作成とレビューを切り離すエンジニアリングリーダーは、義務化を待たずにAIパイプラインのリスクを先回りして下げ、将来のコンプライアンス上の義務を現在の優位性へ変えています。これはすでに、エンタープライズの購買会話にも現れています。
品質エンジニアリングプラットフォームのあるエンジニアリングディレクターは、自社のセキュリティチームが「コーディングとPRレビューに同じツールを使うのは良い考えだとは感じていない」と率直に述べました。あるセキュリティ企業のエンジニアリングリーダーは、さらに明確にこう言いました。「AIコーディングアシスタントのベンダーが、そのままPRレビューベンダーにもなることを、必ずしも望んでいません」。
CodeRabbitが最高のROIで、独立した説明可能なAIコードレビューを提供する方法
独立してレビューするために作られている
CodeRabbitは本質的に、書き手とレビュアーを分離します。プラットフォームに依存せず、コーディングエージェントから独立して動作します。Cursor、Codex、Claude Code、Copilotのようなツールと同じ生成スタックに組み込まれるのではなく、それらと並行して動きます。
内部では、CodeRabbitはレビュー全体を単一モデルに依存させるのではなく、複数モデルのアンサンブルを使います。コンパクトなモデルはコンテキストの蒸留を担当し、より大きな多段階推論モデルは複雑なタスクのために確保されます。複数のモデルが連携し、それぞれが最も適したタスクに集中します。
この設計はレジリエンスも高めます。あるモデルプロバイダーが劣化したり利用できなくなったりしても、他のモデルを通じてレビューを継続できるため、単一のモデルプロバイダーへの依存を減らせます。
コスト効率も、マルチモデルアプローチの利点です。エンジニアリングチームは、コードレビューで最高のROIを得られます。チームは高性能なレビュー、予測可能なシートベースの料金、高スループットなエージェントループ向けの柔軟な従量課金アドオンを利用できます。
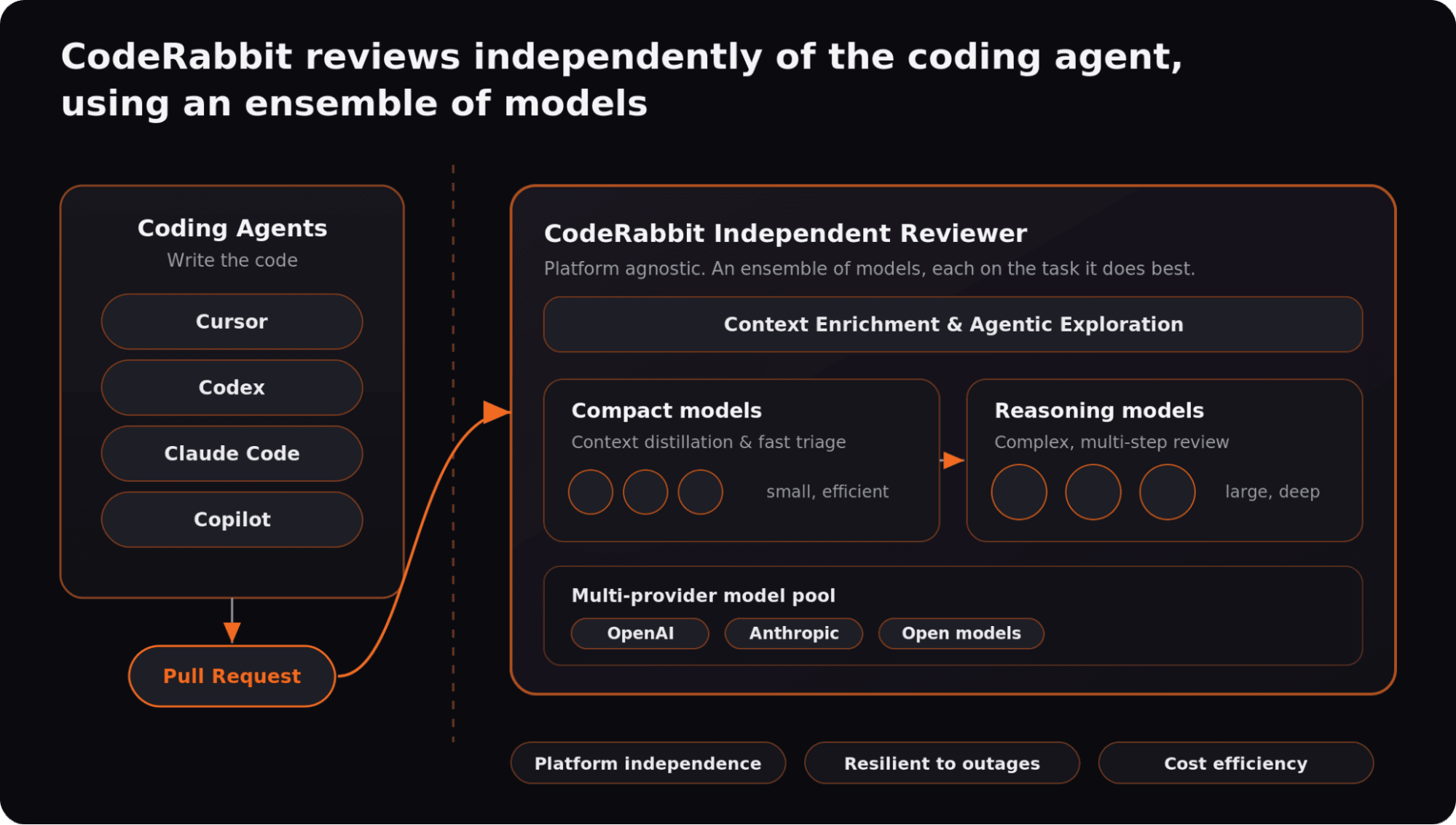
チームが信頼できる、目的特化で説明可能なレビューレイヤー
AIによって生成されるコードが増えるにつれて、説明可能性はコードレビューで欠けているレイヤーになりつつあります。CodeRabbitは以前から、すべてのプルリクエストに対して構造化された要約とウォークスルーコメントを提供してきました。最近リリースされたChange Stack機能は、差分をガイド付きの階層的なウォークスルーに変えることで、説明可能性をさらに進めます。
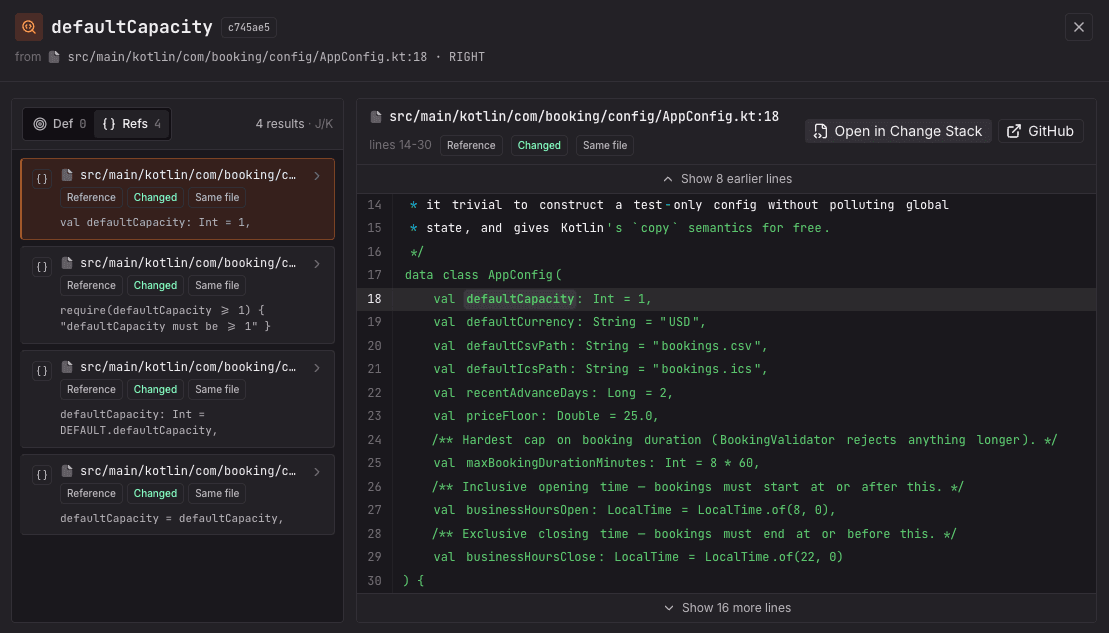
これは変更間の意味的な関係を特定し、関連するコードブロックを論理的なまとまりにグループ化し、そのまとまりを依存関係の順に並べます。PRをファイルごとにレビューするのではなく、人間のレビュアーは、システムがどのようにつながっているかに沿った順序で変更を追えます。シニアエンジニアがPRを案内してくれるようなものです。
Cursor買収がエンジニアリングリーダーに意味すること
Cursorの取引は、信頼の問題を明確にしました。ソフトウェア開発ライフサイクルのより多くの部分が、コードを書くところからレビューするところまで、同じベンダースタックに取り込まれつつあります。それは便利かもしれませんが、すべてのエンジニアリングチームが問うべき問題を生みます。コード作成を支援した同じシステムが、そのコードをリリースして安全かどうかまで判断してよいのでしょうか。
独立したレビューが存在するのには理由があります。モデルは自分自身の間違いを見逃すことがあり、同じファミリーのモデルは同じ死角を共有しがちです。エンジニアリングリーダーはすでにそのリスクを認識しており、確立された変更管理の実践も、変更の作成者とレビュアーを分離する価値を認めています。
CodeRabbitは、独立したレビューレイヤーと、説明可能なコードレビューのための専門的で機能豊富なプラットフォームをチームに提供します。チームはAI生成コードと人間が書いたコードを検証し、なぜ問題として指摘されたのかを理解し、本番環境の前に欠陥を見つけ、自信を持ってより速くリリースできます。
独立した説明可能なコードレビューで、AI開発パイプラインのリスクを先回りして下げましょう。CodeRabbitには豊富な機能セット、エンタープライズ向けの制御、組み込みのガバナンスがあり、15,000以上のエンジニアリングチームで実証されています。詳しくは営業チームにお問い合わせください。


