The art and science of context engineeringの意訳です。
平凡なAIエージェントと卓越したAIエージェントの違いは、ひとえに「コンテキスト」にあります。
最近「コンテキストエンジニアリング」という言葉が話題になっています。2024年6月末、Shopify CEOのTobi Lutkeがこの話題に触れ、Andrej Karpathyも、優れたコンテキストエンジニアリングがAIアプリの差別化要因だと指摘しました。

CodeRabbitは、コンテキストの重要性を示す好例です。私たちは毎日、ユーザーのプルリクエストやIDE上で数万件のコードレビューを行っています。CodeRabbitの各レビューコメントは、レビュー対象のコードに関連する多様な情報源からコンテキストデータを収集し、さらに検証エージェントがその提案がPRやコードベース全体の文脈に合致しているかを再確認する、非線形なレビュー・パイプラインによって生み出されています。
コンテキストエンジニアリングは、単に一般的なコーディング規約にパターンマッチするだけのAIコードレビューツールと、プロジェクト固有のアーキテクチャやパターン、目標を深く理解し、実際に価値あるレビューを提供できるツールとの差を生みます。
コードレビューにおけるコンテキストエンジニアリングの本質

CodeRabbitが扱うコンテキストは、次の3つに大別できます。
意図:開発者やチームがコード変更で達成しようとしている目的。プルリクエストの目的、解決したい課題、期待する成果などが含まれます。
環境:システムの現状。ファイルの関係性、コード依存関係、プロジェクト構造、既存のパターンなど技術的な背景です。
会話:通常のLLMのマルチターン会話でやりとりされるチャットメッセージやツールの応答など、その他の情報です。
これらの要素が適切にバランスされAIに提示されることで、単なる構文エラーだけでなく、アーキテクチャの不整合やパフォーマンスのボトルネック、設計上の改善点まで指摘できるインテリジェントなコードレビュアーが実現します。
コンテキストエンジニアリングの最適解を探る

AIによるコードレビューのために適切なコンテキストを用意するには、いくつかの課題を乗り越える必要があります。ここでは、特に難しい3つの課題を紹介します。
1. AIエージェントの「ゴルディロックス問題」
コンテキストが少なすぎると、AIは不足した情報を推測し「ハルシネーション(幻覚)」を起こしやすくなります。
不要なコンテキストが多すぎると、重要な情報が埋もれ、AIが本質から外れた部分に注目したり、情報過多で混乱します。
ちょうど良いコンテキストは、AIエージェントが正確なインサイトを得るのに必要な情報だけをノイズなく提供します。
2. トークン単位での処理
人間はドキュメント全体をざっと見て重要な部分を直感的に把握できますが、AIモデルはトークン単位で情報を処理し、すべてのテキストに同じ重みを与えます。PRの全コード変更をそのままプロンプトに入れると、AIが些細な点に注目し、重大な問題を見逃すこともあります。重要な変更を優先し、不要な部分は除外する工夫が必要です。
3. コンテキストウィンドウの制約
最先端のAIモデルでも、一度に処理できるテキスト量(コンテキストウィンドウ)には限界があります。特に大規模なコードベースや複雑なPRでは、戦略的なコンテキスト選択が不可欠です。
CodeRabbitのコンテキストエンジニアリング手法
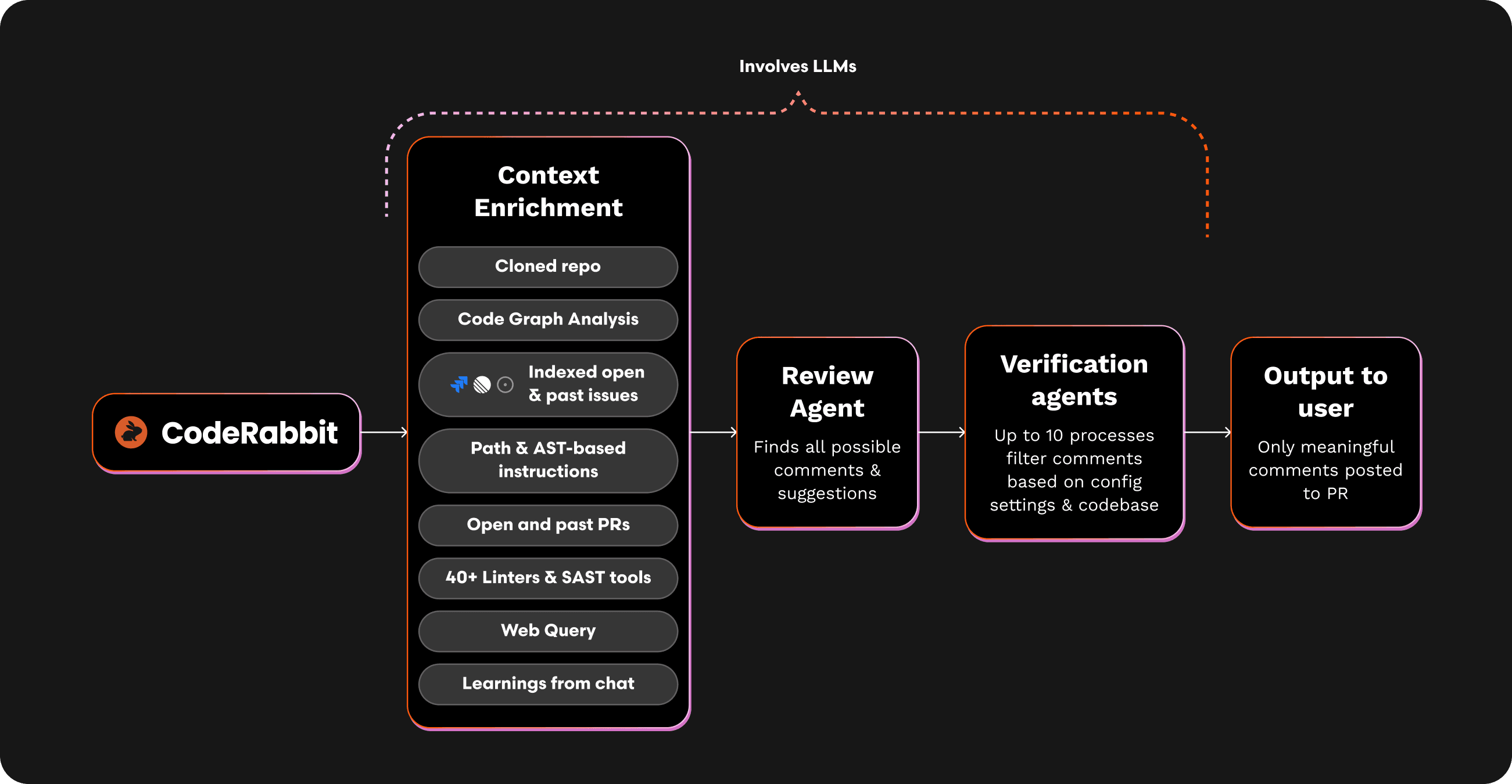
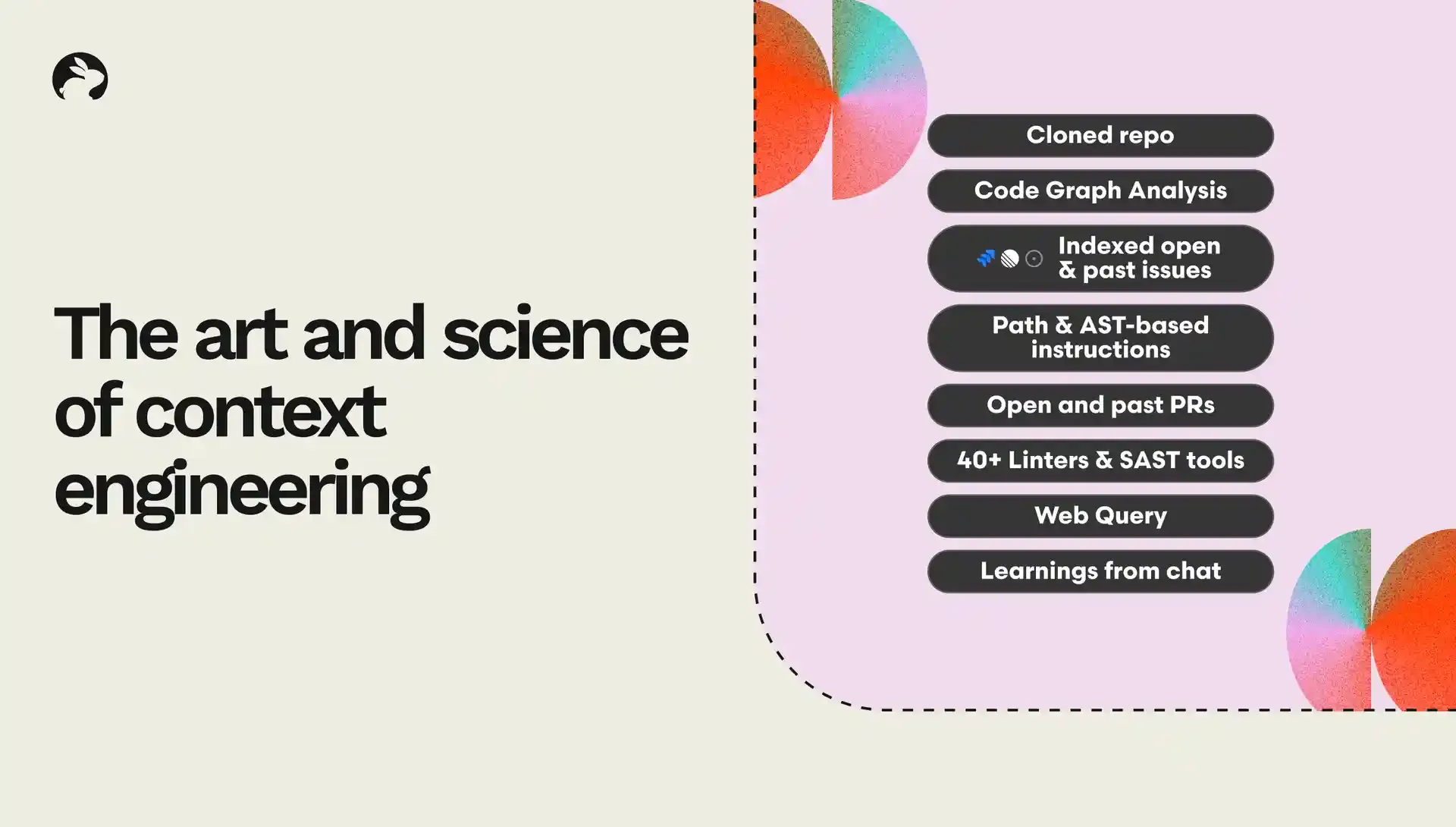
CodeRabbitでは、これらの課題を解決し、常に高品質なコードレビューを実現するために、多層的なコンテキスト準備手法を開発しています。私たちのシステムは、AIの理解力を最大化するために、情報を収集・フィルタリング・構造化する高度な非線形パイプラインを採用しています。上記の図は、私たちがコンテキスト準備で活用している多様な情報源の一部です。
リポジトリ・PR情報のインテリジェントな収集

まず、プルリクエスト自体に関する最も重要な情報を抽出します。
メタデータ:PRタイトル、説明、影響範囲のコミットなど、変更の「なぜ」を特定するための基本情報を収集します。
差分分析:インクリメンタルレビューでは、前回レビューからの正確な変更点を算出し、AIが新規・修正部分だけに集中できるようにします。
パスフィルタリング:生成ファイルや依存ファイルなど補助的なファイルを除外し、本当に重要なコード変更にAIの注意を向けます。
複数ソースからの知識統合
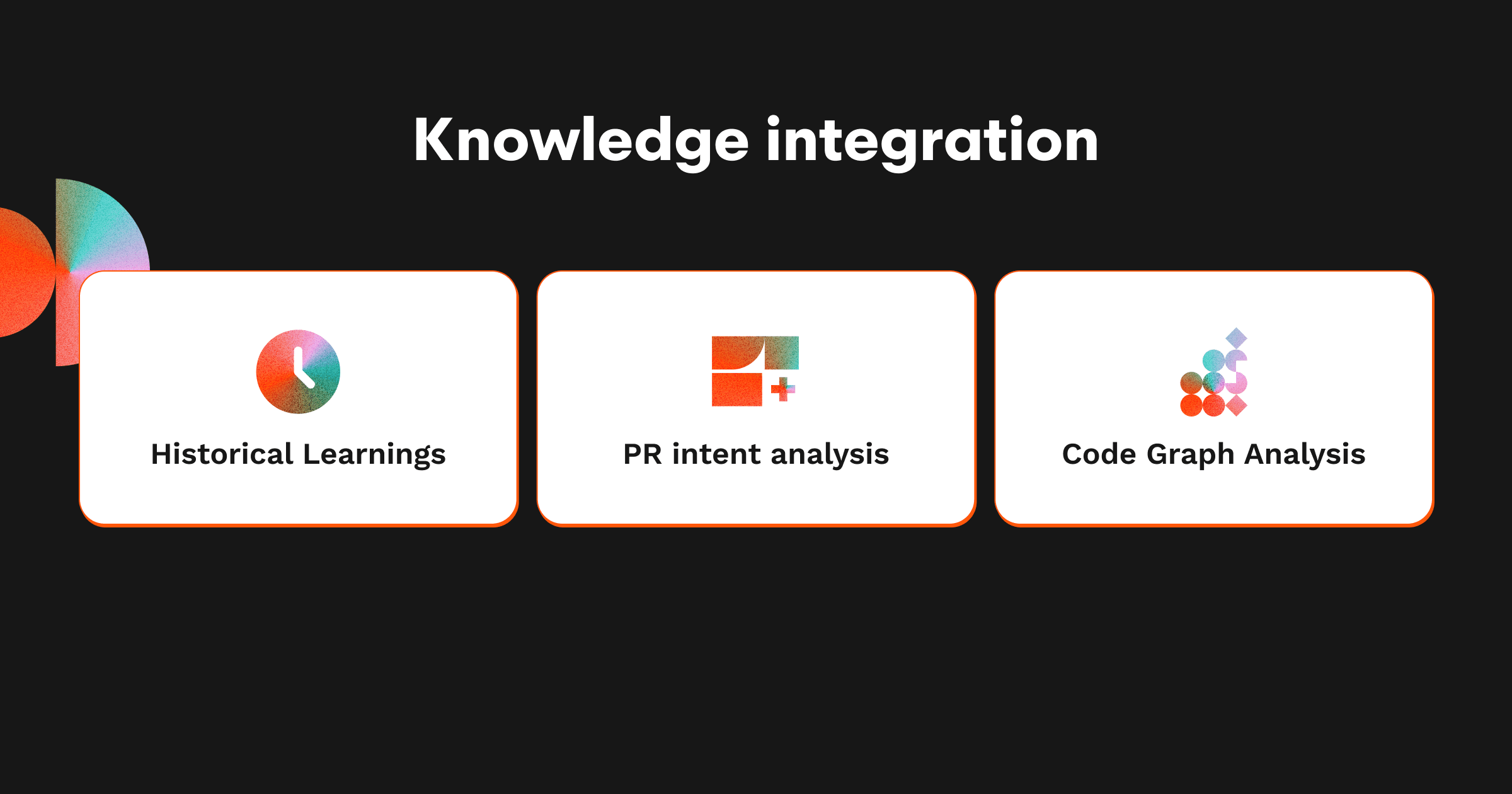
優れたコードレビューには、現在の変更だけでなく、より広い技術的・ビジネス的な背景理解が不可欠です。
過去の学び:エージェントが過去のレビューから得た知見をベクトルデータベースに蓄積し、関連するフィードバックやユーザーの好みを再利用して、コメントの構成に反映します。
PR意図分析:PRの説明や関連Issueを解析し、変更の根本的な目的を抽出。CodeRabbitのレビューが開発者の目標と一致するようにします。
コードグラフ分析:コード依存関係をグラフ構造で表現し、ファイル間の関係性をAIが理解できるようにします。これにより、アーキテクチャ全体への影響も考慮したレビューが可能です。
戦略的なコンテキスト組み立て
必要な情報を収集した後は、AIエージェントが理解しやすい形でプロンプトを最適化します。
パッキングとソート:ファイルを複数のグループに整理し、基盤となる変更から依存先へと論理的な順序でレビューできるようにします。
適応的な複雑度管理:ファイルごとに異なるAIエージェントを割り当て、複雑さや重要度に応じてレビューの深さを調整し、効率とコストを最適化します。
スマートなコンテキスト削減:コンテキストがサイズ制限を超える場合は、要約や分割によって最も重要な情報を残しつつ、範囲を縮小します。
プロンプトエンジニアリング
次の段階では、AIに最適な指示を与えるプロンプトを作成します。私たちのプロンプトは、コードとコンテキストの比率が1:1になるよう設計しており、コンテキストの重要性を物語っています。
レベルに応じたプロンプト:ファイルの複雑さや重要度に応じて、基本的なチェックからアーキテクチャ分析まで、異なる深さのレビューを行います。複雑度ごとに異なるプロンプトやモデルを使い分けます。
構造化されたレビューガイドライン:明確な指示により、AIエージェントが状況ごとに最も価値あるフィードバックに集中できるようにします。過去の有用なレビューコメントのデータも活用します。
コンテキスト強化:プロンプトには、プロジェクトのコーディング規約やパターン、過去の知見も含め、AIがチーム固有のベストプラクティスに沿った提案を行えるようにします。
コンテキスト選択:前段階のエージェントによるコンテキスト準備の結果をもとに、最終的なノイズカットを行います。
検証エージェント
レビュー工程の最終段階では、AIによる品質保証の役割を担う「検証システム」が自動的にレビューコメントの妥当性をチェック・改善します。AIレビュアーが自信を持てない場合に発動します。
発動条件:メインレビュアーがコメントを生成した際、確信が持てない場合は特別な検証リクエストをコメントに含めて検証を依頼します。
証拠収集:検証システムは探偵のように、
実際にシェルコマンドを実行して主張を検証
ウェブ検索で追加情報を収集
システムの知識データベースから関連情報を取得
反復的な分析:一度だけでなく、複数回の調査を重ねて分析を深めます。各ラウンドが前回の結果を踏まえて進行し、徹底的な検証が行われます。
意思決定:証拠をもとに、
元のコメントが正しいと判断し解決
人間による確認が必要(結論保留)
問題が確定し修正が必要
元のコメントが誤りと判断し撤回 のいずれかを決定します。
コンテキストエンジニアリングがレビュー品質に与える影響

私たちのコンテキストエンジニアリングパイプラインの高度化は、レビュー品質の向上に直結しています。
誤検知の削減
適切なコンテキストをAIに与えることで、開発者の時間を浪費するような的外れな提案や誤った指摘を大幅に減らせます。プロジェクト固有の慣習を理解し、意図的なパターンを問題として誤検知しません。
より深いアーキテクチャ洞察
コードの関係性やプロジェクト構造を把握することで、単なるリントやパターンマッチでは見抜けないアーキテクチャ上の問題も指摘できます。実際、多くのユーザーが「CodeRabbitがPRの変更による他の依存箇所への影響まで指摘してくれた」と評価しています。
ベストプラクティスの一貫適用
過去の知見やチーム固有の知識を取り入れることで、すべてのレビューでコーディング規約やベストプラクティスを一貫して適用できます。最近では、お気に入りのコーディングエージェントからコーディングガイドラインをインポートする機能も追加され、チームでの共有がより簡単になりました。
継続的な学習と進化
この手法により、レビューのたびにプロジェクト固有の知見が蓄積され、将来のレビューがさらに価値あるものへと進化します。
良いコンテキストエンジニアリングの重要性
コンテキストは、LLMの技術的要件にとどまらず、効果的なAIエージェントに不可欠な要素です。情報を丁寧に収集・フィルタリング・構造化・提示することで、CodeRabbitは単なるコードレビューにとどまらず、コードの全体像を深く理解し、開発者の生産性向上や堅牢なコード、チームの効率化に貢献します。現在のAIコーディングエージェントは「AIスロップ(粗雑なAIアウトプット)」を多く生み出しがちですが、こうしたアプローチがますます重要になっています。
AIコードレビューにおけるコンテキストエンジニアリングは、まだ始まったばかりです。私たちは今後も品質向上のために手法を磨き続けます。モデルの進化とともに、さらに多くのことが実現できるようになるでしょう。
コンテキストがレビューにどれほど影響するか、ぜひ14日間の無料トライアルで体験してください