
CodeRabbit is now in the Claude Marketplace!Read the Claude Marketplace announcement

Amitosh Swain
July 16, 2025
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
The difference between a mediocre and exceptional AI agent comes down to one thing: context.
Context engineering has recently become a buzzword. In late June, Shopify CEO Tobi Lutke tweeted about it and Andrej Karpathy chimed in to point out that good context engineering is what sets AI apps apart.

CodeRabbit is a great example of the difference context makes. Every day, we perform tens of thousands of code reviews — either on our users’ pull requests or in their IDEs. Each review comment that CodeRabbit makes is the result of a carefully engineered non-linear review pipeline that pulls in contextual data, related to code being reviewed, from dozens of sources and then runs verification agents to check again that every suggestion we share makes sense within the context of both the PR we’re reviewing and the greater codebase.
Context engineering is the difference between an AI code review tool that merely pattern-matches against generic coding standards and one that deeply understands your project's specific architecture, patterns, and goals – and can actually add value to your code review.

We break down the context in which CodeRabbit operates into three distinct parts:
Intent: What the developer or team aims to achieve with the code changes, including the purpose of a pull request, the problems they are trying to solve, and the intended outcomes.
Environment: The current technical state of the system, including file relationships, code dependencies, project structure, and existing patterns.
Conversation: The rest of the regular stuff that goes into a multi-turn LLM call, i.e., your chat messages, tool call responses, etc.
When these elements are appropriately balanced and presented to an AI system, the result is an intelligent code reviewer that catches not just syntactic issues but also architectural inconsistencies, potential performance bottlenecks and opportunities for higher-level design improvements.

Creating the proper context for AI-powered code review involves navigating several challenges. Here are three challenges that make context engineering particularly difficult.
Too little context leads to "hallucinations"—where the AI makes assumptions about missing information, often incorrectly.
Too much irrelevant context dilutes the signal, causing the AI to focus on unimportant aspects or become overwhelmed with information.
Just the proper context provides precisely what the AI Agent needs for accurate insights without noise.
Unlike humans, who can quickly scan a document and mentally prioritise important sections, AI models process information token-by-token, giving equal weight to each piece of text. If we put all the code changes from a PR in the prompt, the AI may latch on to something insignificant and skip major issues. Curating the context is important. You need to prioritise important changes and discard the unimportant ones.
Even the most advanced AI models have finite context windows, the maximum amount of text they can process at once. This limitation makes strategic context selection critical, especially for large codebases or complex pull requests.
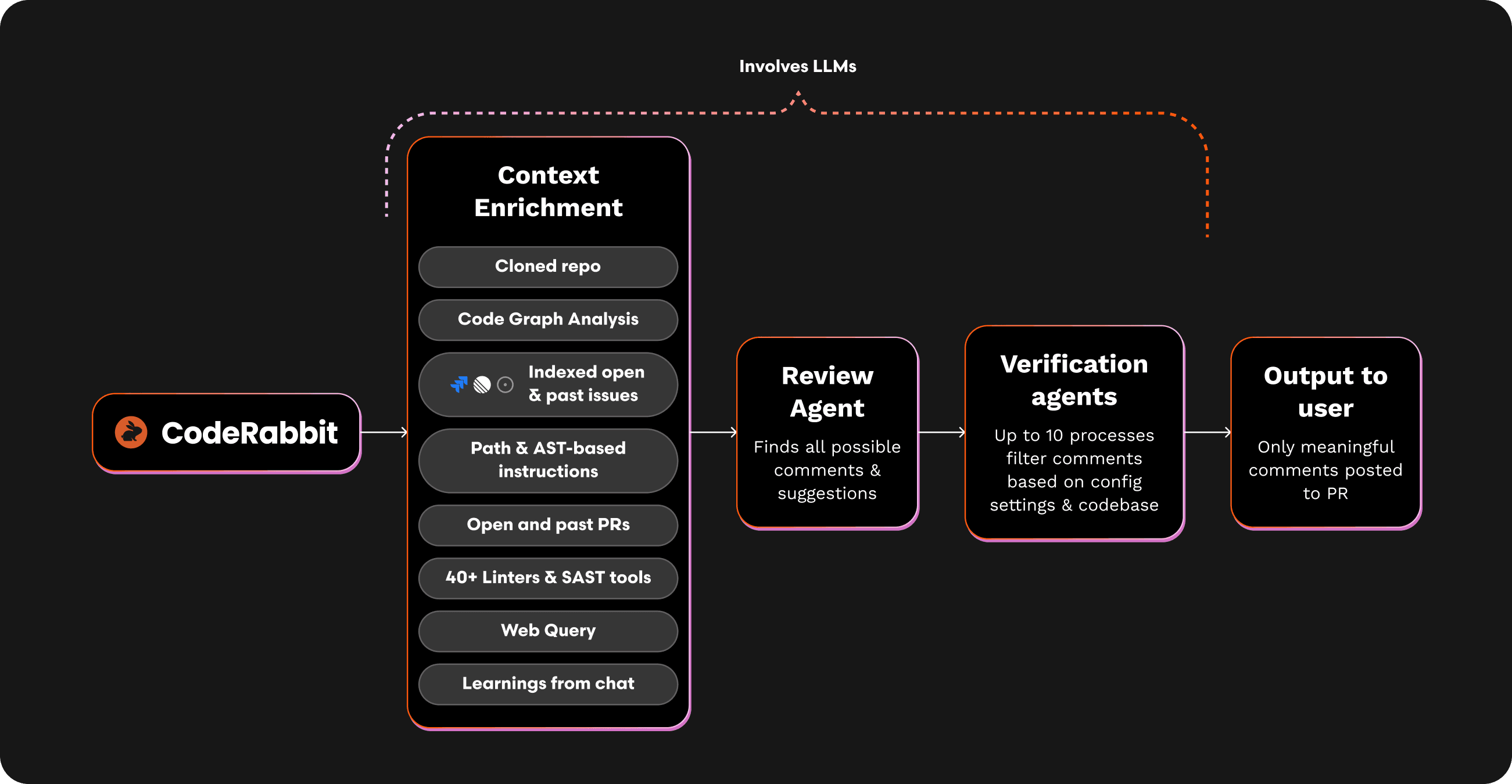
At CodeRabbit, we've developed a multi-layered approach to context preparation that addresses these challenges and delivers consistently high-quality code reviews. Our system employs a sophisticated, non-linear pipeline designed to gather, filter, and structure context in ways that maximise AI comprehension. The diagram above lists just some of the dozens of sources of context we draw on in our context preparation process.

Our context preparation begins with extracting the most relevant information about the pull request itself:
Metadata: We collect essential data like PR title, description, and affected commit range to determine the "why" behind code changes.
Differential analysis: For incremental reviews, we calculate exact changes since the last review, ensuring the agent focuses only on what's new or modified.
Path filtering: Our system distinguishes between meaningful code changes and ancillary files (like generated assets or dependencies), focusing the AI's attention on what truly matters.
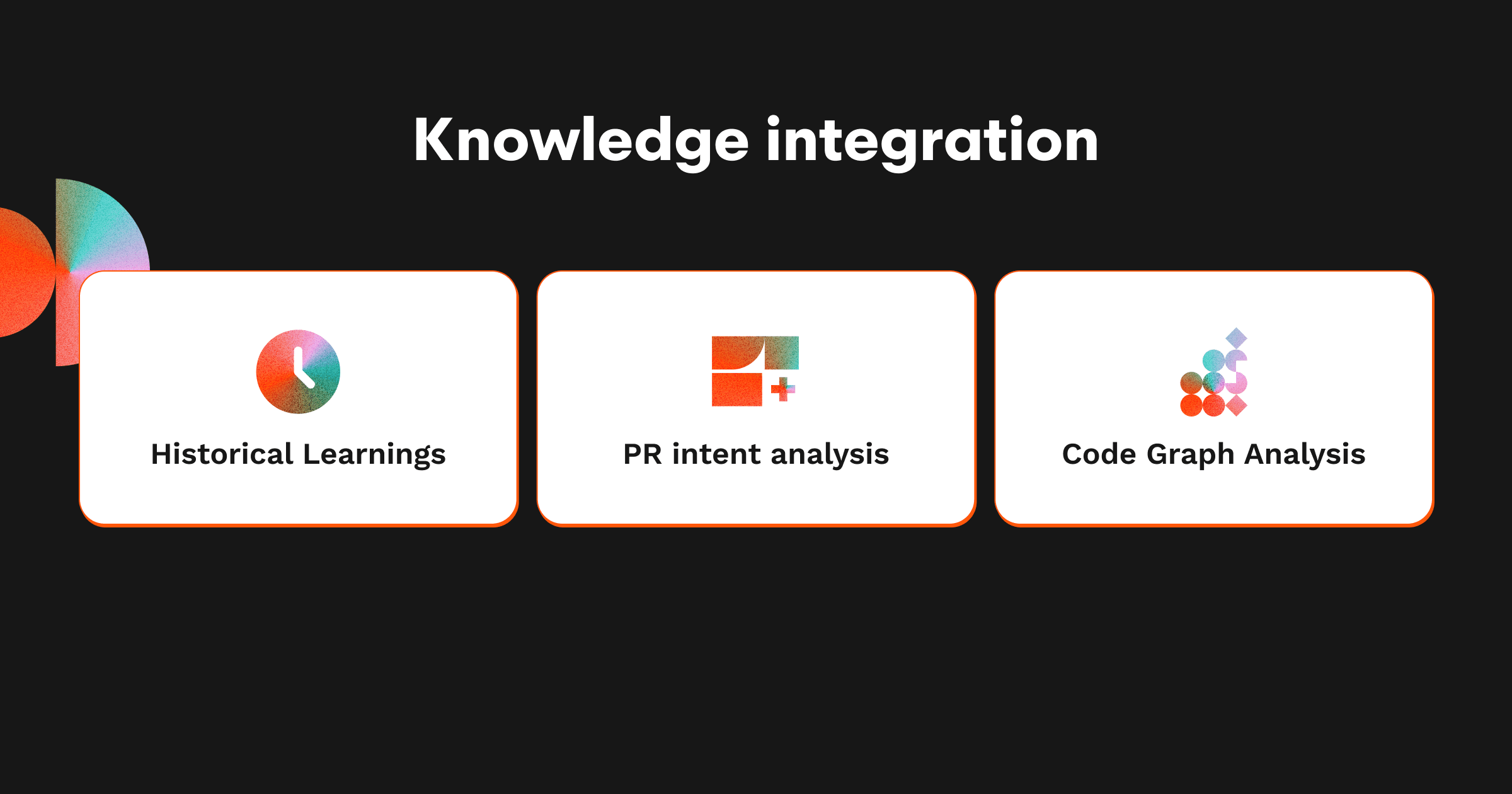
A great code review requires more than examining the current changes in isolation. Next, we work on understanding the broader technical and business context:
Historical learnings: We employ a vector database to store our agent’s learnings from past reviews, allowing the system to recall relevant feedback patterns and user preferences so it can structure review comments with these in mind.
PR intent analysis: We analyse PR descriptions and related issues to extract the underlying objectives of changes, ensuring CodeRabbit's review aligns with developer goals.
Code Graph Analysis: We then construct a graph representation of code dependencies to help the AI understand how files interrelate, enabling reviews that consider architectural impact.
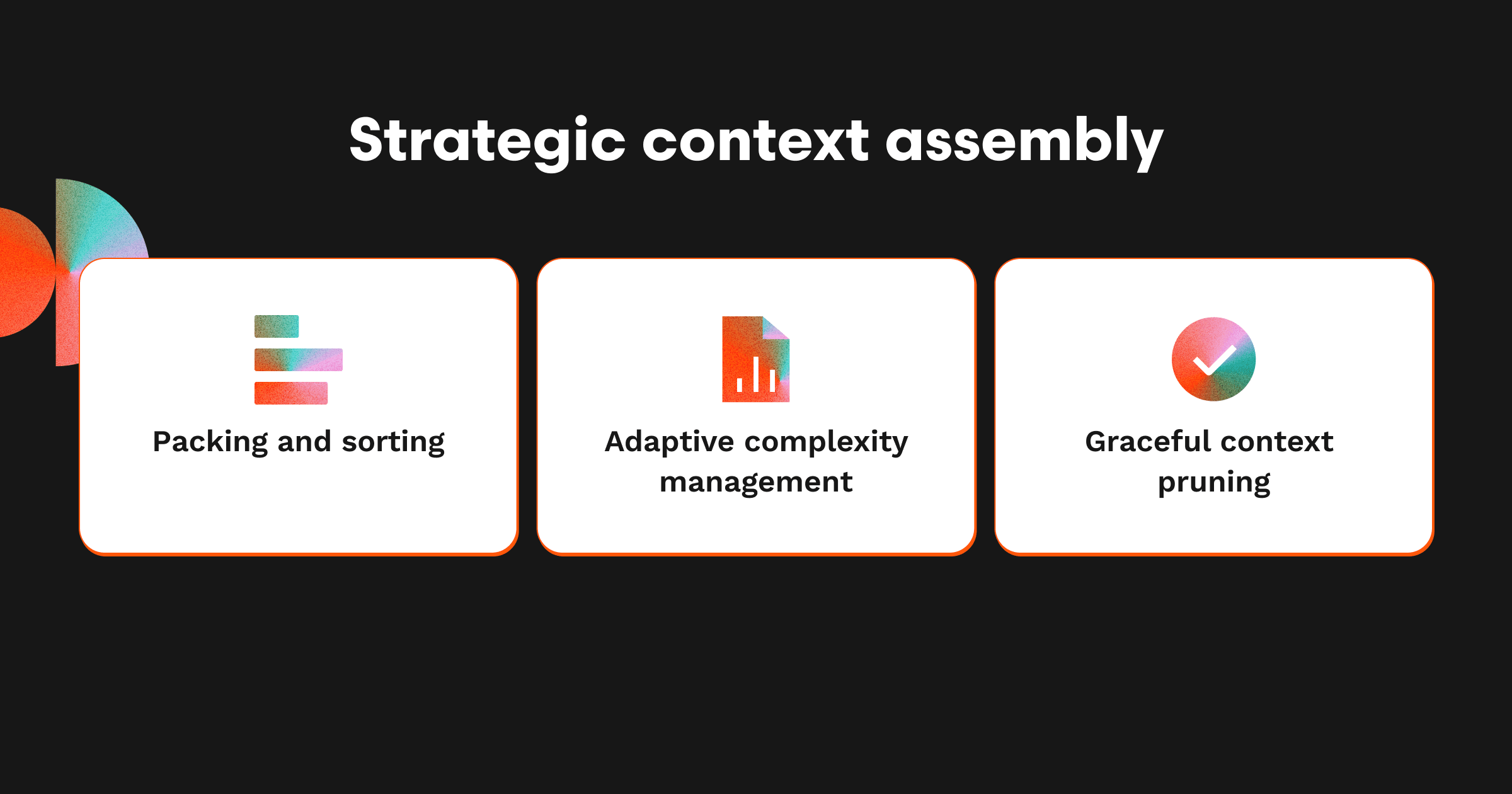
Once we have gathered all the raw information required for reviewing, we optimize how the prompt is packaged for the AI agent.
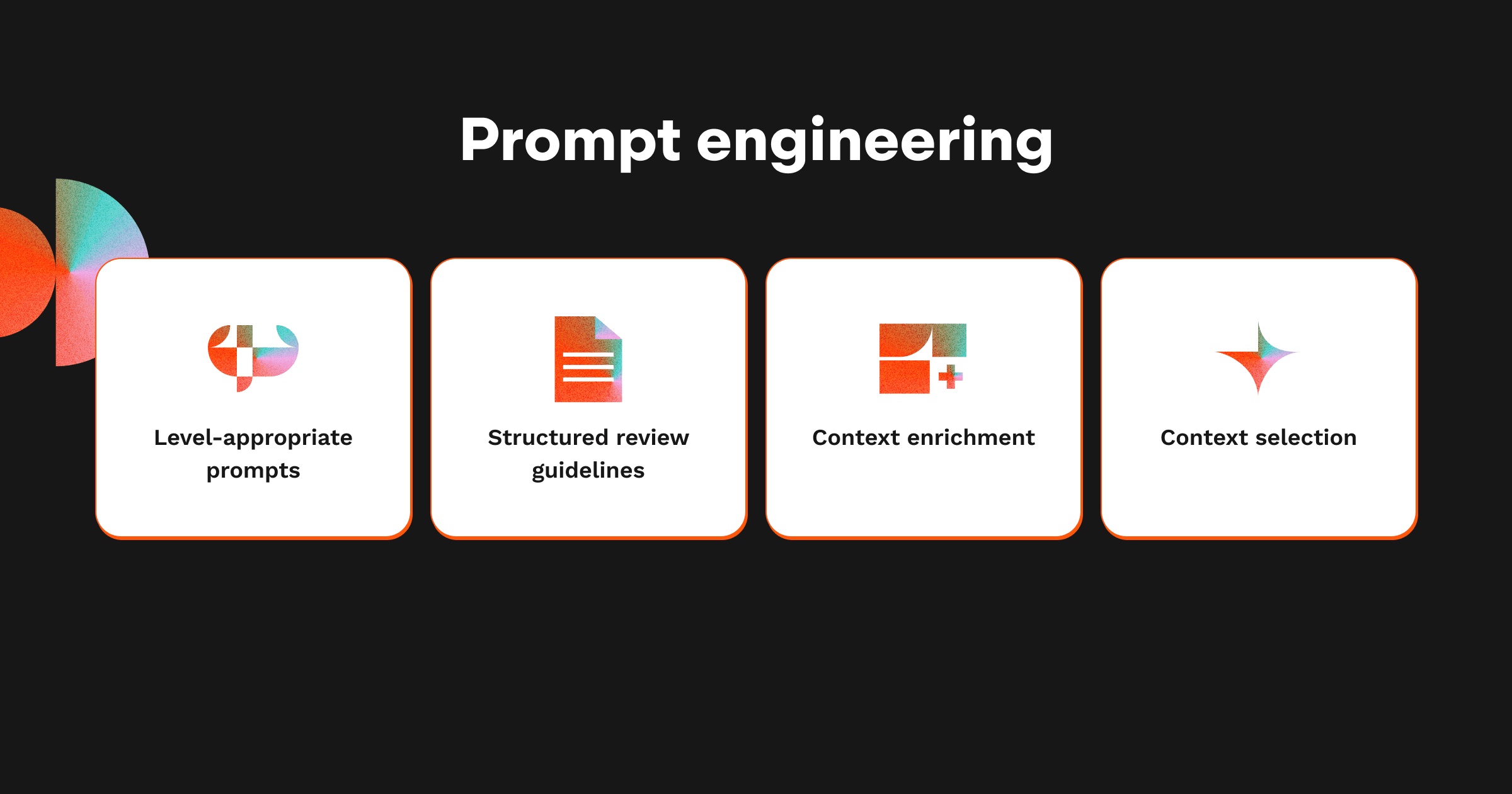
The next stage of our review pipeline involves crafting the perfect instructions for the AI. We average a 1:1 ratio of code to context in our prompts which shows how important context is:
Level-appropriate prompts: We adjust the review depth based on file complexity and importance, ranging from basic checks to in-depth architectural analysis. For different complexity levels, we use different prompts and models.
Structured review guidelines: Clear instructions help the AI Agent focus on the most valuable types of feedback for each specific situation based on our own historical data on helpful review comments
Context Enrichment: The prompts include relevant project coding standards, patterns, and historical insights that guide the AI toward company-specific best practices.
Context Selection: We perform a final pass of the context with results of the previous agents, which did the context preparation to cut noise.
The final target of our review process is our verification system which is an AI-powered quality assurance layer that automatically validates and improves review comments. It’s activated when the AI reviewer needs to double-check its findings.

The sophistication of our context engineering preparation pipeline directly translates to tangible benefits in review quality, including:
By providing the AI with the proper context, we dramatically reduce irrelevant or incorrect suggestions that waste developer time like, for example, changes to function calls that don’t align with the team’s coding standards. The system understands project-specific conventions and avoids flagging intentional patterns as issues.
With more knowledge of code relationships and project structure, CodeRabbit can identify architectural issues that simple linting tools or pattern matching will miss. For example, many of our customers recount how CodeRabbit is able to flag when changes in a PR will affect other dependencies in their codebase.
By incorporating historical learnings and team-specific knowledge, we consistently apply coding standards and best practices across all reviews. We continue to make it easier for teams to share their coding guidelines – including recently enabling the ability to import coding guidelines from your favorite coding agent.
Our approach enables the system to improve with each review, building a growing knowledge base of project-specific insights that make future reviews even more valuable.
Context is not merely a technical requirement for LLMs, but a requirement for effective AI Agents. By thoughtfully gathering, filtering, structuring, and presenting the context, CodeRabbit doesn't just review code. Instead, it understands code in its full complexity so that it can provide insights that make developers more productive, code more robust, and teams more effective. This is increasingly important as AI coding agents currently tend to generate a significant amount of AI slop.
This is only the beginning of context engineering for AI code reviews – we are always refining our approach to improve review quality. With model capabilities constantly expanding, in the future, we’ll be able to do much more.
Interested in seeing how context makes a difference in our code reviews? Start your 14-day trial!.



