
CodeRabbitがClaude Marketplaceに登場!Learn more

Atsushi Nakatsugawa
May 28, 2026
1 min read
Opus 4.8 benchmark results for AI code review and code generationの意訳です。
AnthropicはOpus 4.8をリリースしました。リリース前に、私たちは主にコードレビュータスクでこのモデルを評価しています。標準の評価ハーネスで検証し、実際のプルリクエスト上での挙動を観察し、どこで安定し、どこで負荷がかかるのかを確認しました。あわせて、エージェントが完了前に破綻しがちな、長時間にわたるコーディング作業にも使用しています。
レビューでは、調整済みの本番環境向けアンサンブルの一部と同等の水準に達しています。意外だったのは、コード生成と長期的なエージェント型セッションで大きく先行した点です。
実際に導入されたのは3点で、それ以外はすべてそこから派生したものです。
{"role": "system", ...}を追加しても、プロンプトキャッシュが無効化されなくなりました。モデルはそれらを上書き指示というより、文脈として扱うと最も安定して従います。また、以前のOpusよりも計画を説明し、自分の判断を見直し、追加の許可を求める傾向があります。いずれも有用な挙動ですが、予算管理と能動的な誘導が必要です。コードレビューでは、実用的な指摘のパス率が61%対62%、フルシステムでは72%対68%と、精度を維持したまま同等水準に達しました。ただし、コメントの内訳は変化し、致命的な指摘(critical)は35件から29件に減少しました。この点は懸念材料です。以下の「結果」セクションでは、その理由と取り戻せる見込みがあるかについて掘り下げます。
CodeRabbitは、このモデルの強みが活きる箇所に限定して統合しています。一方で、品質やパス率を犠牲にせずコスト面で優れる他のモデルも引き続きルーティングしています。
私たちはOpus 4.8を、すべてのモデルリリースで使用している同じハーネスに通しました。対象は、軽微・小規模・大規模の複雑度階層からサンプリングした100件のオープンソースプルリクエストです。2つの思考設定を比較しました。1つは階層に応じてmedium/high/x-highへ段階的に上げるデフォルト設定、もう1つはlow/medium/highで動作する、思考レベルを抑えた構成です。これらを、同じPR群に対して現在の本番モデル構成を走らせたベースラインと比較しました。
分析では2つの指標を重視しました。パス率は、シニアエンジニアレベルのレビュアー(人)が指摘する内容と同等のものをモデルが見つけられたPRの割合です。精度は、ノイズではなく実用的だったコメントの割合です。「実用的」かどうかは上級レビュアーが判定しました。
デフォルトのOpus 4.8設定は、フルシステムのパス率でベースラインをわずかに上回りました(+4ポイント、72%対68%)。実用的な指摘のパス率では誤差範囲内です(61%対62%)。精度は実用的なコメントで33.8%を維持し、フルシステムでは1ポイント上昇しました。
コードレビュー向けに特別最適化されたわけではないモデルが、調整済みアンサンブルと正面から比較されてこの結果を出したことは、素晴らしい結果だといえます。特に上級レベルのPRでは、ファイル横断の推論能力が明確に表れました。
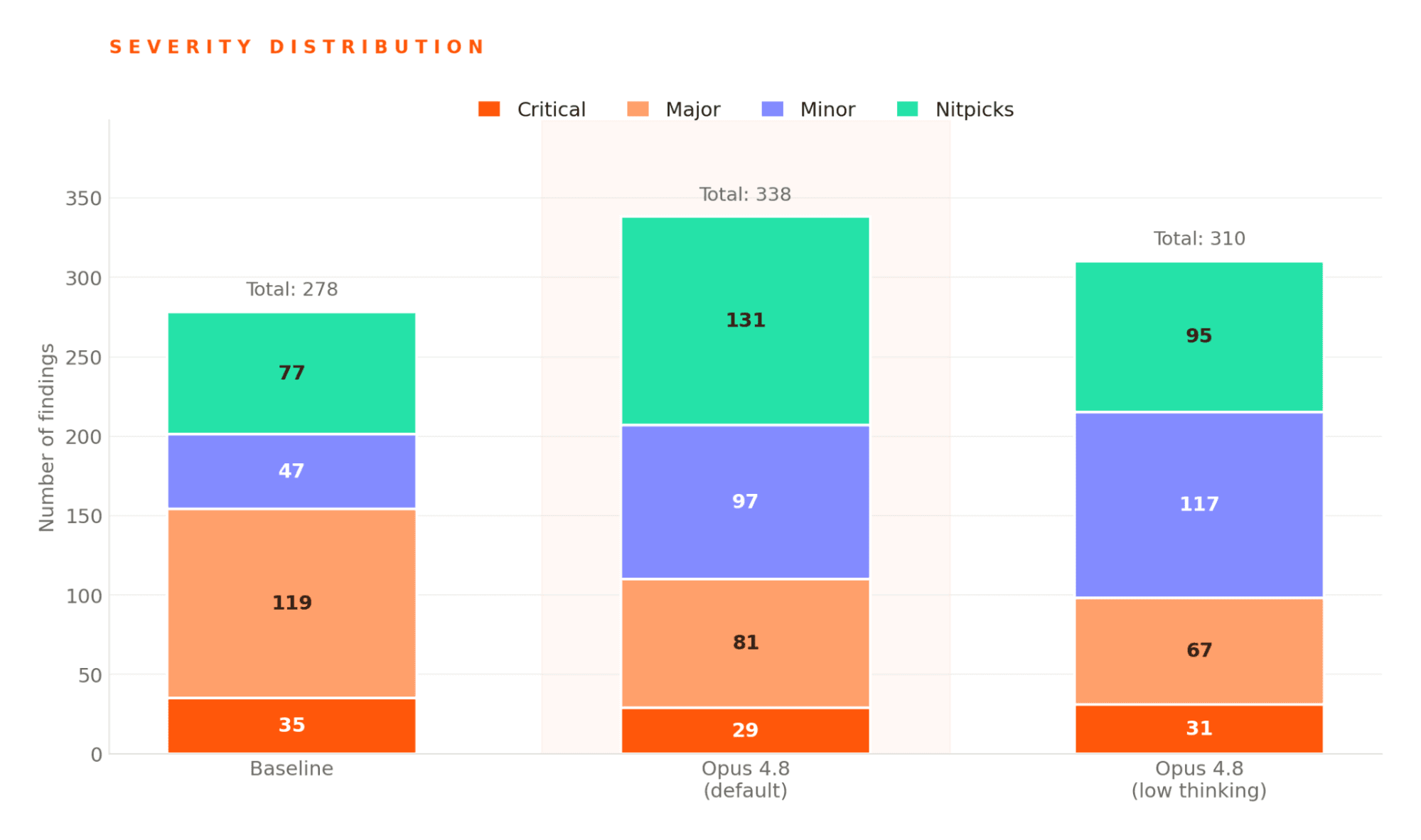

ただし、コメントの内訳はベースラインよりノイズが多くなっています。重要度「高」の指摘(major)は119件から81件に減少し、一方で軽微な指摘(minor)と些細な指摘(nitpick)はいずれもほぼ倍増しました。モデルは重大度レンジの中間から下位へ、出力量を移しているように見えます。
懸念している結果は、致命的な指摘(critical)が35件から29件に減少した点です。コードレビューツールにおいて、致命的な指摘の見逃しは、他のどのカテゴリの見逃しよりも重要です。私たちの作業仮説では、Opus 4.8はレビュー指示を文字どおりに従う傾向があります。そのため、「重大度の高い問題だけを報告する」といった保守的なプロンプトは、以前のモデルよりも再現率を強く抑制します。一方で、モデルに幅広く報告させ、下流でフィルタリングする形にすれば、重大度の高いバグを検出する能力自体は十分に発揮されると考えています。
思考レベルを抑えた構成からも、有用な補足が得られました。推論負荷を下げると、精度は4ポイント、実用的な指摘のパス率は5ポイント低下しました。思考レベルは、最重要級の設定項目だといえます。
また、デフォルト設定はコストが高いことも分かりました。1回あたり$0.20〜0.28で、Opus 4.5の約$0.13、Sonnet 4.5の$0.04〜0.12と比較して高くなります。コードレビュー単体ではモデルは同等水準であり、このプレミアムはレビュー専用用途では正当化しにくいものです。価値を発揮するのは、後述する長期的なエージェント型作業とコード生成です。コストと適用領域のトレードオフがあるため、私たちは全体に適用するのではなく、選択的にルーティングしています。
コンテキストが200kトークンを超えると、性能は目に見えて低下します。モデルは遅くなり、より小さいコンテキストウィンドウであればきれいに拾えていた参照やエッジケースを見逃し始めます。これは実利用での観察結果であり、制御された測定ではありません。CodeRabbitのコンテキストエンジンはこの問題を回避しますが、Opus 4.8を直接使うチームは、モノレポや大規模コードベースで壁にぶつかるはずです。
私たちはOpus 4.8を選択的に統合しています。このモデルの強みであるファイル横断の推論、長期的なエージェント型タスクの品質、単一の事前仕様に基づく計画能力は、上級レベルの変更で最もよく表れます。そのため、そのような場面で利用されます。軽微なPRやジュニアレベルのPRでは、それぞれの階層でコストとパス率に優れるモデルへのルーティングを継続します。エージェント型機能については、Opus 4.8がこれまで統合した中で最も強力な基盤になると見込んでいます。
Opus 4.8を直接使う場合、既存のOpus向けプロンプトの多くは変更なしで動作します。ただし、私たちの検証では、いくつかの調整で測定可能な差が出ました。まず、"x-high"ではなく"high"の思考設定から始め、階層ごとにテストしてください。長期的な作業では、タスク全体の文脈を最初に渡してください。調査要素が強い作業で踏み込んだ深掘りを引き出したい場合は、「まず検索する」「サブエージェントに任せる」といった指示をはっきり与えてください。レビュー用プロンプトから保守的な表現を外し、代わりに下流でフィルタリングしてください。モデルが自律的に判断してよい小さな決定を明示してください。
モデルとハーネスが変化する中で、私たちは今後も評価を行います。状況に変化があれば、更新された数値を公開します。


