

Atsushi Nakatsugawa
June 19, 2026
1 min read
The real bottleneck in code review isn't reviewing code, it is understanding itの意訳です。
少しだけ自分に正直になってみてください。直近の四半期で、自分のものではないPRを最後に完全に理解したのはいつですか?
本当のところ、ロジックを追い、チケットを確認し、エッジケースを精査し、本番環境で何が起こるかまで考え抜きましたか? それとも、ざっと目を通し、要点を掴み、明らかな危険信号を探し、作成者を信頼していて「緊急」のレビューに追われていたから承認しましたか?
それが、ほとんどのチームにおけるコードレビューの本当の姿です。エンジニアがコード品質を気にかけなくなったわけではありません。問題は、コードの量が、人間がそれに割ける注意と時間を上回ってしまったことです。大きなPRは何日も放置され、アーキテクチャに関するフィードバックはまれになり、差分が一人の頭に現実的に収まる量を超えると、丁寧なレビューはパターンマッチングに変わってしまいます。
オープンソースのメンテナーは、いまやこれと日々向き合っています。プロジェクトへの貢献は手軽になりましたが、コードのレビューはその道をたどりませんでした。依然として人間がすべてのPRを読み、何が変わったのかを読み解き、なぜそのように作られたのかを理解し、コードベースのほかの部分の動きと衝突しないかを判断しています。
それが、新しいソフトウェア開発ライフサイクル(SDLC)の現実です。エージェントが生成したコードのレビューがチームの速度を落とし、コーディングエージェントから得られるROIをさらに先送りにしているのです。
チームは、人間が書いたコードのために使ってきた従来のレビューモデルを、エージェントが書いたコードのレビューにそのまま当てはめています。人間のレビュアーが一度に頭の中に保持できるコード、コンテキスト、意図には限りがあり、それを超えるとレビューはパターンマッチングに変わってしまいます。
私たちは開発者に対して、どんな変化が起きようとしているのか、なぜその変更が重要なのか、リスクは何か、そして本当に何がリリースされようとしているのかを完全に理解できるよう、エージェント時代のSDLCに向けてコードレビューのインターフェイスを作り直しました。
この10年間コードをレビューしてきたなら、コードレビューのプロセスは、AIを方程式に持ち込む前から、ずっと少し壊れていたという静かな真実をご存じでしょう。
コードレビューは常に、別人の頭の中から意図を再構築するレビュアーに頼ってきました。作成者は、なぜその変更が存在し、どんな挙動を持ち込もうとしたのかを分かっています。一方レビュアーは差分を受け取り、変更が正しいかどうかを評価し始める前に、そのロジックを自分の頭の中でリバースエンジニアリングしなければなりません。
AIは、エンジニアリングチーム全体でコードレビューのボトルネックを増幅させます。いまやチームは、人間が書いたコードのために設計された同じインターフェイスを通して、より大きく理解しにくい差分として、はるかに多くのコードを押し込んでいます。しかも、PRを開いた作成者でさえ、その変更の影響を完全には理解していないことが多いのです。ここでチームは、人間が書いたコードのレビューとAIが生成したコードのレビューが別の仕事であることに気づきます。
AIが生成したコードは、しばしばパターン補完を反映しており、コードベースの慣習、制約、アーキテクチャ上のロジックを見落とすことがあります。AIが生成したコードの失敗モードは、微妙なものではありません。私たち自身の調査では、ロジックと正しさに関する問題が、AIのPRでは人間のものより75%多いことが分かりました。セキュリティの問題は最大で2.74倍、可読性の問題は3倍以上にもなります。

これらは、差分を何となく眺めて見つけられるような欠陥ではありません。深いコンテキスト、慎重な推論、そしてほとんどのレビュアーがもはや持ち合わせていない時間を必要とする問題です。シニアエンジニアの役割は、意図を検証し、リスクを徹底的に検証し、そもそもその変更が存在すべきかどうかを判断することへと移ってきたからです。
しかし、こうしたプレッシャーは人間による貢献に限った話ではありません。これらは普遍的な現実を浮き彫りにします。人間が書いたコードとAIが生成したコードは、異なる経路を通ってやってきますが、同じ場所で失敗するのです。
コードレビューの表層からは、依然として意図が抜け落ちています。コードレビューの本当のボトルネックは、コードが人間によるものであれAIによるものであれ、その変更が何をするはずだったのか、どの制約が重要だったのか、何が壊れうるのか、そして最終的な挙動が当初の目標と一致しているのかを理解することです。コードレビューは常に、人々にそれを差分から推測することを強いてきました。そしてAIは、そのギャップをはるかに明白なものにします。
このすべての根底にある要因は、コードをレビューするためのインターフェイスが、エージェントがコードの大部分を書くようになるという変化に追いついていないことです。現在のインターフェイスは、変更されたファイルを順番に表示すれば、誰かが意図を再構築するのに十分だと、いまだに想定しています。それはAI以前から弱い想定でしたが、いまではさらに悪い想定です。
エージェント時代のワークフローでコードレビューが持ちこたえるには、生の差分ビューアの中に存在することはできません。レビュアーが意図を理解し、リスクを切り分け、判断が本当に重要な箇所に注意を集中できるよう手助けするシステムにならなければなりません。
エージェント時代のワークフローでは、私たちは1行ずつの検査から意図の検証へと軸足を移さなければなりません。私たちが答えるべきは次の問いです。システムは、私たちが作ろうとしたものを作ったのか? その変更は既存のコードベースの制約を尊重しているか? この転換が不可欠なのは、AIが生成したコードの量が、私たちが手作業で検査できる能力をとうに上回ってしまったからです。
コードをレビューし、意図をよりよく理解するために、チームには意図を引き継いでいく検証レイヤーが必要です。それは、変更の形を読み取れるようにし、ファイルをまたいだ関連作業を結びつけ、見えにくいリスクを浮かび上がらせ、ファイルシステムがたまたま返す順番ではなく、理にかなった順番でレビュアーがPRを進められるよう手助けすべきです。
この転換が重要なのは、コードレビューのボトルネックが、変更が正しいか、安全か、そしてチームが意図したとおりに動くかを判断できるだけ、その意図を十分に理解することに常にあったからです。
AIはそのボトルネックの本質を変えたわけではありません。アウトプットの速度を劇的に引き上げたのです。そしてチームはいま、従来のレビュープロセスがそもそも支えられるよう設計されていたよりも速く、意図を理解しなければならなくなっています。
レビュアーには依然として、変更の形、読むべき順番、重要な依存関係、そして人間の判断で速度を落とすべき箇所を見ることが必要です。コード生成が加速するとき、コードレビューは意図を引き継いでいくことに長けたものにならなければなりません。さもなければチームは恩恵を受けられず、ただボトルネックを下流に移すだけになります。
それがCodeRabbit Reviewの背後にある方向性です。PRをファイルのフラットなリストのままにしておくのではなく、変更を論理的なコホートと順序付けられたレイヤーへと再編成し、それらのレイヤーを実際のコード範囲に紐づけ、視覚的な説明によって変更が理解しやすくなる場合には図を追加します。
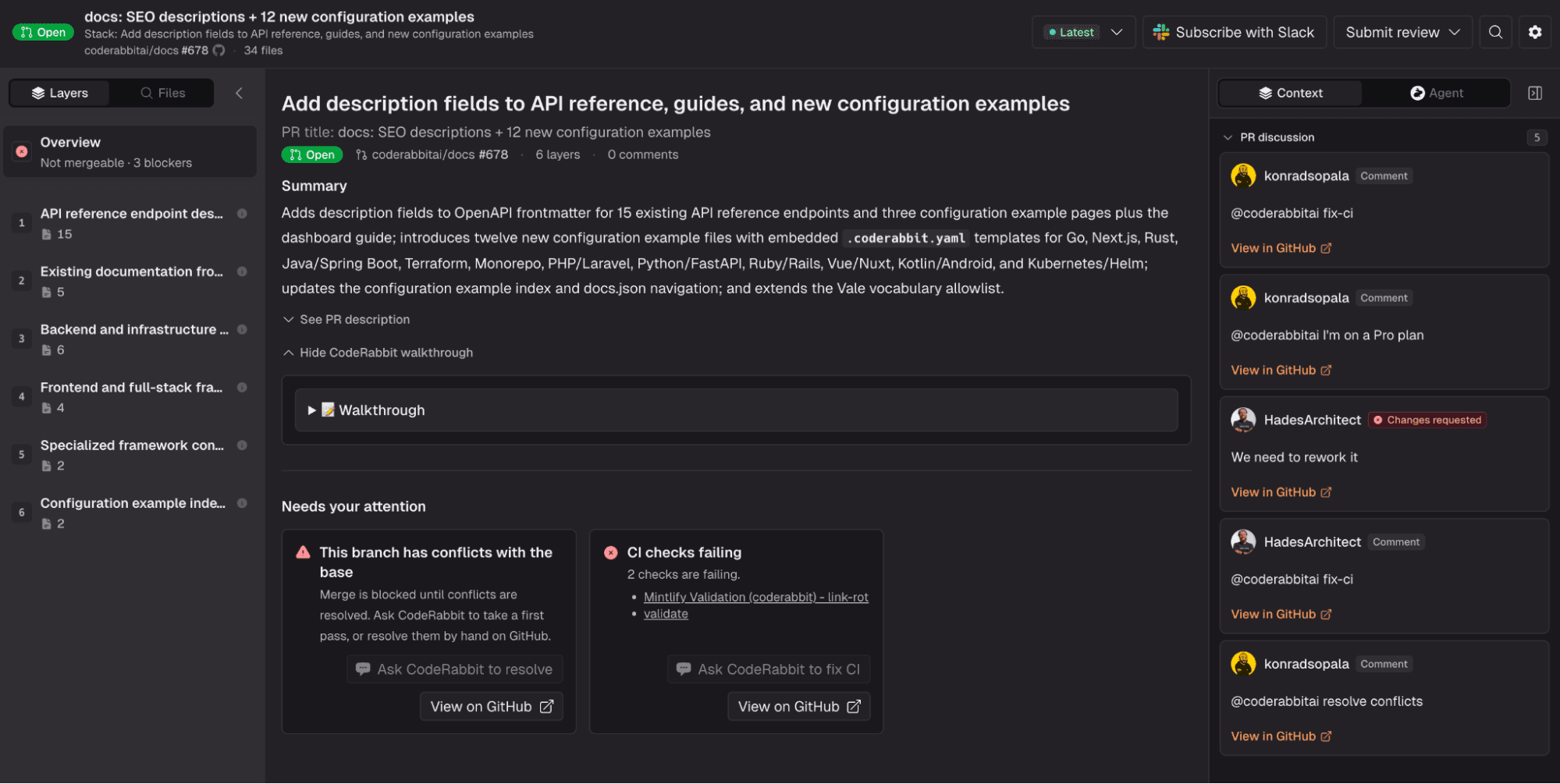
これは、変更されたブロックをまたいだ関係を理解し、依存関係をマッピングし、レビューすべき行の山ではなく、説明可能なウォークスルーへと差分を変えることを意味します。目的は、チームをさらに多くのAIコメントで溢れさせることではなく、長年コードレビューを遅く脆いものにしてきた再構築のステップを取り除くことです。
次のPRでCodeRabbit Reviewを試してみてください。CodeRabbit Reviewは、すべてのCodeRabbitユーザーが期間限定で無料で利用できます。CodeRabbitのPRサマリーコメント内の「Review Change Stack」をクリックすると見つけられます。


