CodeRabbitがClaude Marketplaceに登場!Claude Marketplaceの発表を読む

Atsushi Nakatsugawa
April 14, 2026
2 min read
April 14, 2026
2 min read
共有
Agentic Code Review vs RAG: Why Agents Win for Multi-Repository Analysisの意訳です。
今日のソフトウェア開発が単一リポジトリに限定されることはほとんどありません。複雑なシステムには、マイクロサービスのバックエンド、共有型ライブラリ、フロントエンドアプリケーション、統合テストスイートなど、すべてが別々のリポジトリに存在しているケースが多くあります。
このため、あるリポジトリでAPI処理を変更すると、他の複数のリポジトリのコンシューマーが気づかないうちに壊れる可能性があります。
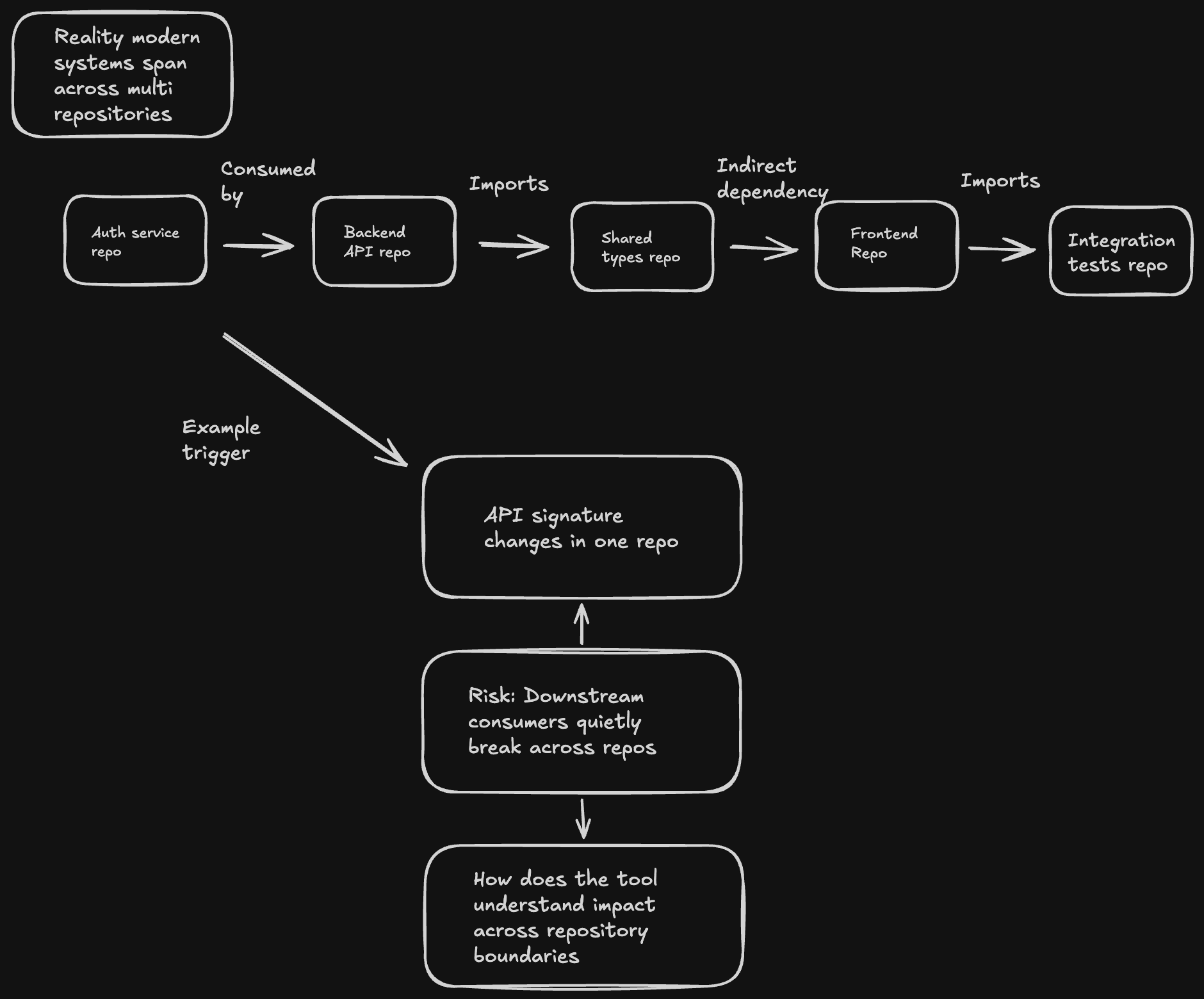
図1:現代のシステムは複数リポジトリにまたがっており、1つの変更が他のリポジトリを知らず知らずの内に破壊する可能性があります
従来のコードレビューツールは、各プルリクエストを独立した単位として扱います。レビュアーがリポジトリをまたぐ破壊的変更を発見できるのは、通常ツールがそれを提示したからではなく、レビュアー自身がすでにシステムを理解しているからです。
コードレビューツールを評価するエンジニアリングリーダーにとっての本質的な問いはシンプルです。そのツールはリポジトリ境界を越えた影響をどのように把握するのか、ということです。
この問いへの答えは、事前構築されたベクトルインデックスに依存するツールと、レビュー時にコードを能動的に探索するツールとの間にある、根本的なアーキテクチャの違いを浮き彫りにします。
リポジトリ横断分析でエージェント型システムが優れている理由を説明する前に、率直にお伝えしておきます。CodeRabbitは、このアーキテクチャパターンが業界のコンセンサスになる前の2024年から、このようなエージェントベースの検証ループを構築・運用してきました。
このアプローチは、Anthropicの「Building Effective Agents」ガイドやGoogle Cloudの「Agentic RAG」に関する記事に触発されたものではありません。これらの記事は、私たちが実践の中ですでに学んでいたことを追認したに過ぎません。リポジトリ境界を越えたコードレビューは、本質的に検索ではなく調査問題であるということです。どのファイルが重要かを事前に予測できない以上、事前インデックスで正しい答えにたどり着くことはできません。
以下は、リポジトリ横断の影響をレビューする際に、エージェントが生成する検証スクリプトの具体例です。
// Agent-generated validation: UserService.createUser signature change
// PR: auth-service \#1423 — adds required roleId parameter
const impactedCallSites \= \[
{
repo: "org/backend-api",
file: "src/controllers/admin.ts",
line: 45,
currentCall: "userService.createUser(email, name)",
issue: "Missing required roleId argument — will throw at runtime",
severity: "breaking"
},
{
repo: "org/backend-api",
file: "src/controllers/onboarding.ts",
line: 112,
currentCall: "createUser({ ...userPayload })",
issue: "Spread object may not include roleId — needs verification",
severity: "warning"
},
{
repo: "org/integration-tests",
file: "tests/fixtures/user-factory.ts",
line: 23,
currentCall: "UserService.createUser(email, name)",
issue: "Test fixture calls old signature — will fail in CI",
severity: "breaking"
}
\];
これがエージェントの出力です。意味的に類似したスニペットの一覧ではなく、ライブコードに基づいた正確なファイルレベルの分析結果です。本記事の残りでは、この違いがアーキテクチャに起因するものであり、RAGパイプラインのみに依存するツールではこれを再現できない理由を解説します。
主流のパターンはRAGパイプラインに従います。
このアプローチは広く知れ渡っており、幅広く採用されています。Forresterの分析でも、RAGはエンタープライズのナレッジアシスタントのデフォルトアーキテクチャとして確認されています。しかし、研究により構造的な弱点が特定されており、それはリポジトリを横断するコードレビューにおいて特に顕著です。このドメインでは精度が重要であり、誤った確信は危険です。
初回の検索で関連コードを見逃した場合、セマンティックな不一致、関数を2つのフラグメントに分割してしまう不適切なチャンキング、あるいはテキスト的ではなく構造的な関係性が原因であったとしても、システムにはリカバリーメカニズムがありません。
コードレビューにおいて、これは次のことを意味します。ベクトル検索が、変更されたAPIの下流コンシューマーを見つけられなければ、ツールはその存在を通知しません。再試行の機会も代替戦略もありません。
業界データがこの深刻さを裏付けています。NVIDIAの技術ブログでは、標準的なRAGは「一度検索して一度生成する。ベクトルデータベースを検索し、上位Kチャンクを取得し、その中に答えがあることを期待する」と報告されています。この一発勝負が外れると、レビュー全体が損なわれます。
最新のベクトルデータベースはインデックス作成のレイテンシを大幅に削減しており、多くはわずか数秒で更新を提供できるようになっています。しかし、「高速な」インフラストラクチャが正確で完全なコンテキストを保証するわけではありません。RAGパイプラインは依然として、変更の検出、ファイルの再チャンキング、Embeddingの再計算、インデックスの更新といった複数のステップに依存しています。複数リポジトリのシステムでは、この問題が複合的に発生します。
コードレビューにおいて不完全または不整合な分析に依存することの結果は、多くの場合、誤った確信です。エージェント型システムは、レビュー時にコードをライブで分析することで、このリスクを回避します。
コード分析における一般的な問題は、意味的に類似した検索結果が実際の関連性を欠いていることが多く、AIの推論を汚染してしまうことです。Anthropicのエンジニアリングチームはこれを「コンテキストの腐敗(context rot)」として文書化しています。コードレビューにおいてこれは、誤ったコードに基づいた自信に満ちた分析として現れます。これは分析がない場合よりも、むしろ悪い結果をもたらすと言えます。
コードの関係性は本質的にセマンティックではなく構造的です。例えば、関数呼び出し、import文、protobufスキーマへの参照はグラフ関係であり、類似度検索では特定が困難な構造です。共有型定義が変更された場合、重要なのはそれをインポートしているコードを特定することであり、テキスト的に似ているだけのコードチャンクを見つけることではありません。
ベクトル検索は、変更したコードに似ているコードを見つけることはできます。しかし、src/controllers/admin.ts:45がuserService.createUser(email, name)を2つの引数で呼び出しているのに対して、PRではシグネチャが3つの引数を必要とするように変更されているということを判定することはできません。それにはコードを読み、呼び出し箇所を理解し、不整合について推論することが必要です。
Anthropicは影響力のある「Building Effective Agents」ガイドで最も明確な線を引いています。リポジトリ横断の影響分析は、「必要なステップ数を事前に予測することが困難または不可能」というエージェントの要件によって正確に表現されています。
OpenAIは2025年3月にAgents SDKをリリースし、チームが「ステップバイステップのプロンプティングからエージェントへの作業委任」にシフトするシナリオに対応しました。
Google Cloudは最も直接的に述べています。「グラウンディングへの最も強力なアプローチはAgentic RAGであり、エージェントはもはや情報の受動的な受け手ではなく、検索プロセスそのものにおける能動的な推論の参加者となります。」
これらの記事は、業界が収束しつつある方向を反映しています。そしてそれは、CodeRabbitが2024年から行ってきたことをまさに記述しています。
CodeRabbitの複数リポジトリ分析は、エージェント型アーキテクチャを体現しています。コードを静的な表現に事前インデックス化し、クエリ時に適切なチャンクが出てくることを期待するのではなく、CodeRabbitはリンクされたリポジトリをリアルタイムで能動的に探索する自律的なリサーチエージェントをデプロイします。
設定はシンプルです。チームは関連するリポジトリを宣言するだけです。
knowledge\_base:
linked\_repositories:
\- repository: "org/backend-api"
instructions: "Contains REST API consumers of shared types"
\- repository: "org/integration-tests"
instructions: "End-to-end test fixtures"
PRがオープンされると、エージェントは複数ステップのリサーチ戦略を実行します。
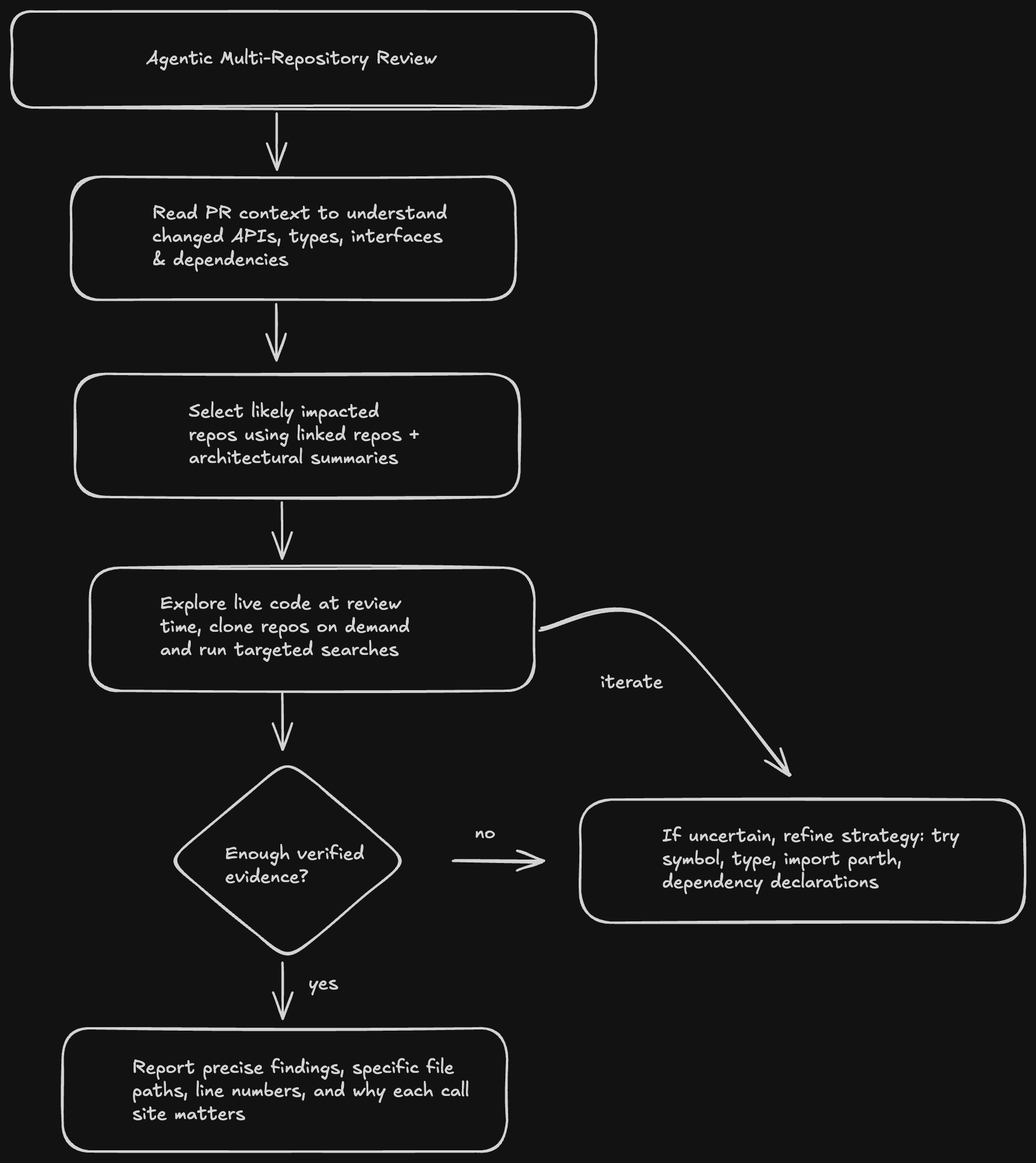
図2:CodeRabbitのエージェント型レビューフロー — 検証済みのエビデンスが得られるまで反復します
auth-serviceリポジトリでUserService.createUserメソッドのシグネチャを変更し、必須のroleIdパラメータを追加するプルリクエストを考えてみましょう。RAGベースのツールは「createUser」という文字列を含むコードフラグメントを特定できますが、それらの呼び出し箇所がシグネチャの変更により実際に失敗するかどうかを判定する能力はありません。
backend-api (org/backend-api)
integration-tests (org/integration-tests)
この違いは漸進的なものではありません。「いくつかの類似コードチャンク」と「壊れる3つの呼び出し箇所(ファイルパスと行番号付き)」の違いです。
| 項目 | RAGベースのレビューツール | CodeRabbit(エージェント型) |
| データの鮮度 | 最後のインデックスビルドを反映(数時間〜数日前) | HEADのライブコード、常に最新 |
| 検索結果の欠落からのリカバリー | なし。フォールバックのない一発勝負の検索 | エージェントが反復:代替検索を試み、参照をたどり、ファイルを読んで検証 |
| コード関係の理解 | テキストの類似性のみ。import、コールグラフ、型階層をたどれない | コードを構造的にナビゲート。importをgrep、呼び出し箇所を読み取り、型定義をたどる |
| 影響の推論 | 類似チャンクを返すのみ。呼び出し箇所が壊れるかどうかの推論は不可能 | コードを読み、引数を数え、型の互換性をチェックし、実際の影響について推論 |
| 曖昧さへの対処 | 確信度に関係なくtop-k結果を返す | エージェントが結果の品質を振り返り、不確実な場合は洗練された検索を実行し、十分な結果が得られた時点で停止 |
| 発見の精度 | コードチャンク(しばしば部分的で、時に無関係) | 特定のファイル、行番号、およびその発見が重要である理由の説明 |
| セキュリティモデル | 外部サービスにコードの永続的なインデックスが必要 | オンデマンドで隔離されたサンドボックスにクローン。永続的なコード保存なし |
Anthropic、OpenAI、Google、Microsoftなどの主要な業界プレイヤーは、MCP、Agents SDK、Agent Development Kit、A2A Protocolを含むエージェント型インフラストラクチャに一様に大規模な投資を行っています。この重要なコンセンサスは、AI搭載ツールの明確な未来を示しています。自律的で推論する能力を持つシステムが、静的な検索パイプラインに取って代わろうとしています。
リポジトリ横断のコードレビューには以下が必要です。
RAG(検索拡張生成)は、複数リポジトリのコードレビューに対して根本的にミスマッチです。RAGはナレッジベースにLLMをグラウンディングする質疑応答には優れていますが、リポジトリをまたぐコード分析には単なる知識検索ではなく、調査的なアプローチが求められます。
CodeRabbitがリポジトリ横断の影響分析にエージェント型アーキテクチャを採用したのは、業界トレンドへの対応ではありません。この問題を実際に解決できる唯一のアーキテクチャだからこそ、私たちはこれを構築しました。業界は、私たちが2024年から行ってきたことに追いつきつつあります。
CodeRabbitのリポジトリ横断分析を実際に体験してみませんか?次のPRで無料でお試しください。


