
Atsushi Nakatsugawa
January 23, 2026
2 min read
January 23, 2026
2 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
What to know about prompt requestsの意訳です。
1996年の映画『ザ・エージェント』では、トム・クルーズが「Show me the money!(金を見せろ!)」と叫ぶ有名な電話のシーンがあります。あの一言が、場の空気を一変させ、責任の所在を明確にします。

AI支援によるソフトウェア開発においても、「プロンプトを見せてください(show me the prompt)」は、同様の役割を果たすべきです。
大規模言語モデル(LLM)によって生成されるコードが増えるにつれ、責任が消えるわけではありません。責任の位置が、より上流へと移動します。現代のエンジニアリングチームが直面している問いは、「AI生成コードをレビューできるか」ではなく、「コードが存在する前の段階で、意図がどのように表現されるようになったとき、どこで、どのようにレビューすべきか」という点です。
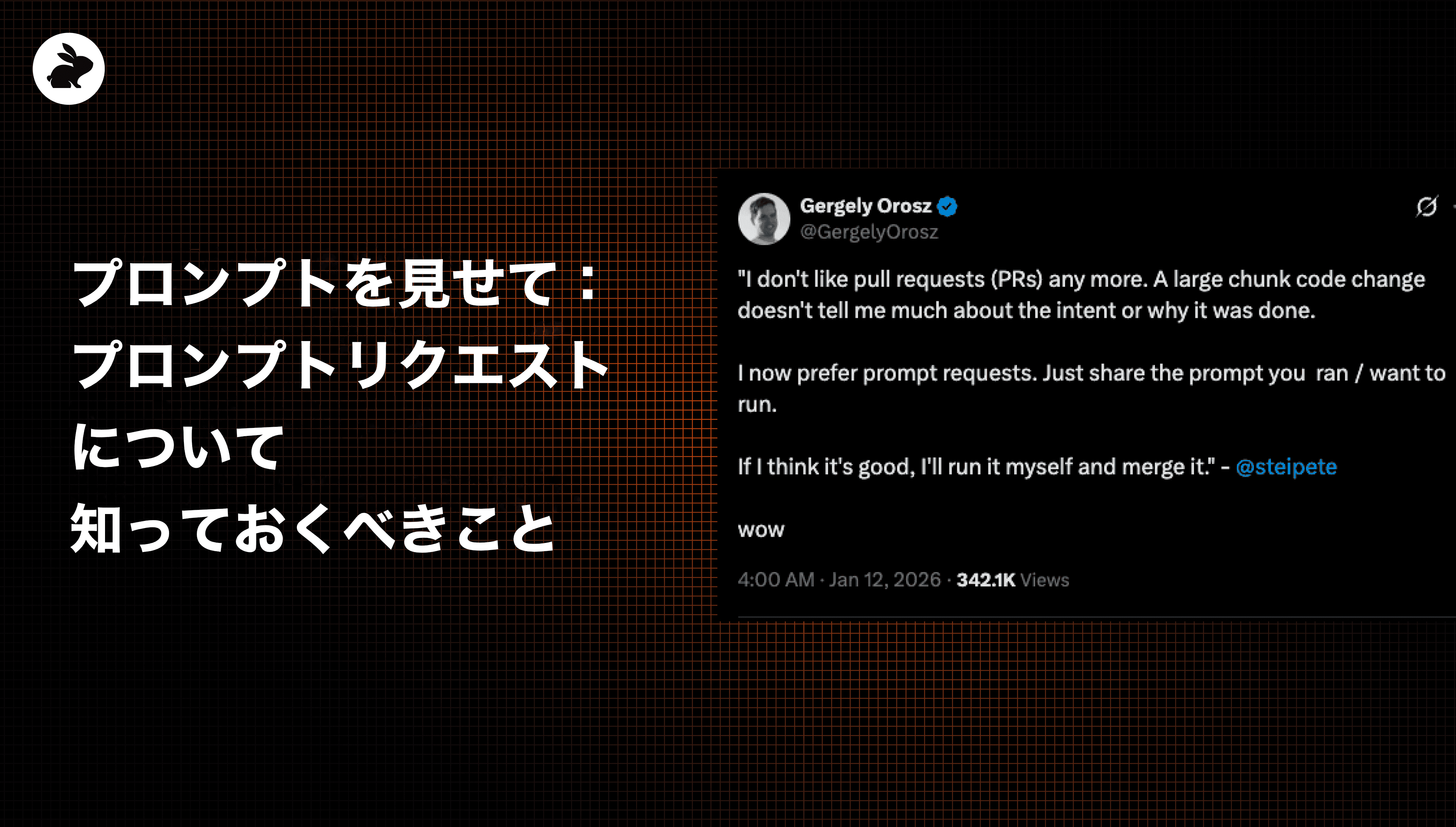
今週初め、Pragmatic Engineer の Gergely Orosz 氏が、セルフホスト型AIエージェント Clawdbot の作者である Peter Steinberger 氏とのポッドキャスト収録からの引用を、Twitter(あるいはX)で共有しました。
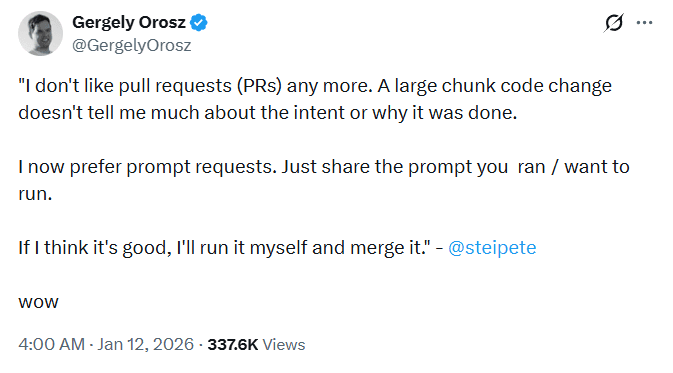
Steinberger 氏の主張はシンプルでありながら挑発的でした。LLMによって生成されるコードが増えるにつれ、従来のプルリクエストは変更内容をレビューする最適な方法ではなくなるかもしれない。その代わりに、変更を生成したプロンプトをレビュアーに渡すべきだ、というものです。
この意見はすぐに賛否両論を呼びました。
支持者は、AIが生成した巨大な差分をレビューすることが、ますます現実的でなくなっていると主張しました。
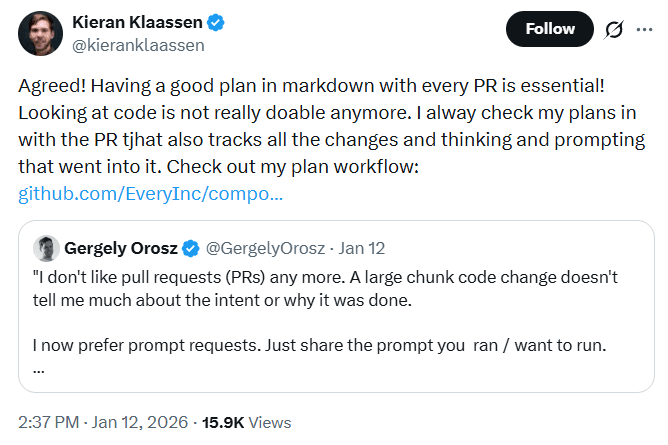
彼らの視点では、プロンプトはアウトプットよりも直接的に「意図」を捉えます。開発者が何を達成しようとしたのか、どのような制約を置いたのか、どこまでをスコープとしたのかが分かります。さらに、プロンプトは再実行や調整が可能であるため、何千行もの生成コードを精査せずとも、アプローチを検証しやすいという利点があります。
一方で批判的な意見は、プロンプトだけでは解決できない問題を指摘しました。たとえば、決定性、再現性、git blame、そして法的な責任です。
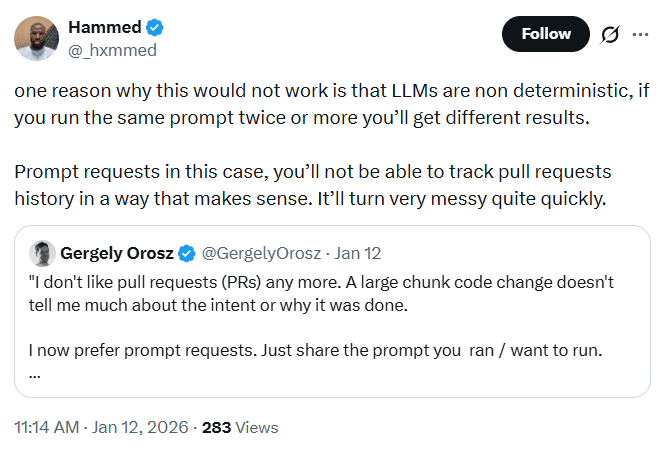
LLMの出力は実行ごと、モデルごと、設定ごとに変わる可能性があります。そのため、プロンプトを承認したからといって、最終的にリリースされるコードそのものを承認したことにはなりません。監査、所有権、下流の責任という観点では、この違いは重要です。彼らの考えでは、PRベースのワークフローが提供してきた保証を弱めることなく、「プロンプト承認」でコードレビューを置き換えることはできません。
つまり、核心となる対立点は「プロンプトをレビューに含めるべきかどうか」ではありません。AI支援ワークフローにおいて、責任をどこに置くべきか、プロンプトなのか、コードなのか、あるいは意図的に設計された両者の組み合わせなのか、という点です。
プロンプトリクエストとは、その名の通り、LLMにコード生成をさせる前に、開発者が自分のプロンプトについて同僚にレビューを依頼することです。マルチショットや対話型プロンプトの場合は、開発者とエージェントとのやり取り全体をレビュー対象にすることもあります。
差分レベルからレビューを始める代わりに、プロンプトリクエストでは、LLMに与えた指示そのものを評価します。レビュアーは、モデルの出力を導く文脈、意図、制約、前提条件に同意したり、改善に貢献したりできます。一般的なプロンプトリクエストには、次のような情報が含まれます。
システムプロンプトおよびユーザープロンプト
関連するリポジトリやアーキテクチャの文脈
使用するモデルの選択と設定
制約、不変条件、非ゴール
期待される振る舞いの例
目的は、モデルが「どのような指示を受けたのか」を明確にしたうえで、その成果を評価することです。
この意味で、プロンプトリクエストはコード成果物というより設計成果物に近い存在です。生成時点の意図を記録し、要件を満たすのに十分で明示的なプロンプトになっているかを確認する助けになります。チームがプロンプトの書き方について認識を揃え、同じ文脈を使ってコード生成を行えるようにします。
今週の議論の多くは、プロンプトリクエストとプルリクエストを競合するものとして扱ったことに起因しています。どちらか一方を選ぶべきだ、という意見です。
しかし、本来そのように考える必要はありません。
両者は開発ライフサイクルの異なる段階で、異なる失敗パターンに対処します。コードレビューをしたからといってテストを省略しないのと同じように、プロンプトリクエストをしたからといってコードレビューを省略すべきではありません。
プロンプトリクエストは、コードが生成・コミットされる前の早い段階で、認識合わせやベストプラクティスを保証する点に価値があります。何を作るべきか、境界はどこか、エージェントの振る舞いをどう制限するかを明確にします。LLMは非決定的であるため、変動が最も大きい上流で意図を明示的に捉えることは、より重要になります。
また、プロンプトリクエストは、特定のモデルやツールに最適化されたプロンプトになっているかを確認する助けにもなります。これは、モデル間の差異が大きくなっている現在、出力品質を担保するうえで不可欠です(これは私たちの評価でも一貫して確認しています)。
一方、プルリクエストは、最終的にリリースされる具体的なコードをレビューする段階で不可欠です。決定性、トレーサビリティ、テスト、監査、責任を担保します。一方は意図を捉え、もう一方は実行結果を捉えます。
プロンプトリクエストをプルリクエストの代替とみなすと、不必要な対立を生みます。両者を併用すれば、相互補完的に機能します。プロンプトリクエストを行ったうえでプルリクエストを省略するのは、実際のコードが検証されていない以上、無謀だと言えるでしょう。
十分なコードレビューを含む通常の開発フローの一部として使う場合、プロンプトリクエストは、より早い段階で問題を見つけるための「シフトレフト」の手段になります。機能の目標についてチームの認識を揃え、使用するモデルに最適なプロンプトに調整し、生成品質を高めるための適切な文脈が提供されているかを確認できます。これにより、後工程でのレビュー負荷や問題を大幅に減らせます。
一方、コード生成後のプルリクエストを行わず、単独で使われる場合の主な魅力は、認知的効率とスピードです。
AIはコード生成の速度を劇的に高めましたが、レビュー工程はそれに追いついていません。AIが書いた変更が大規模かつ頻繁になるにつれ、1行ずつのレビューはますます困難で、精神的負荷も高くなります。欠陥が見逃されるのは、エンジニアが無関心だからではなく、巨大な機械生成差分をレビューすること自体が消耗する作業だからです。
それに対してプロンプトは、通常短く、宣言的です。プロンプトをレビューすることで、モデルが生成した実装の詳細に埋もれることなく、スコープ、意図、制約について直接考えられます。
プロンプトファーストのレビューは、特に次のようなケースで有効です。
スキャフォールディングやボイラープレート生成
小規模な変更
グリーンフィールドのプロトタイプ
反復速度を重視する素早いチーム
本番の欠陥が致命的にならない趣味プロジェクト
これらのケースでは、「すべての行が正しいか」よりも、「これは本当に作りたかったものか」が重要になることが多いです。
プルリクエストと併用する場合、生成前にもう一度レビューの機会を増やすだけなので、大きな欠点はほとんどありません。最大の懸念は、レビューにかかる時間と認知的コストであり、これが長引くとコード生成の新たなボトルネックになり得る点です。
プルリクエストの代替として扱う場合、最大の制約は非決定性です。
同じプロンプトでも、実行やモデルが変われば異なる出力が得られます。そのため、プロンプトレビューは、実際にリリースされたコードの監査可能な記録をレビューする代替にはなりません。git blame、コンプライアンス、法的責任の観点では、プロンプトレビューだけでは不十分です。
また、セキュリティや正確性のリスクもあります。プロンプトで網羅したつもりでも、安全でない前提を含んでいたり、エッジケースを見落としていたり、通常のコードレビューであれば検出されるはずのシステム固有の制約を考慮できていない可能性があります。意図をレビューしたからといって、生成結果が安全で、高性能で、要件に適合しているとは限りません。
さらに、プロンプトは文脈依存性が高いです。単体で見ると妥当に見えるプロンプトでも、レビュアーがコードベース、インフラ、実行環境に精通していなければ、問題のある実装を生む可能性があります。人間のレビュアーでさえ実コードでミスをします。そこにモデルの予測不能性が加わると、バグやダウンタイムにつながりやすくなります。これらのリスクは、プロンプトを再利用したり、時間をかけて変更したり、モデルを切り替えたりすると増大します。
両者を組み合わせることで、それぞれの弱点を補えます。
実用的なワークフローは次のようになります。
開発者が、意図、制約、前提を記述したプロンプトリクエストを提案します。単一のプロンプトの場合もあれば、生成するコードの各部分に対して複数のプロンプトを用いる場合もあります。対話型プロンプトの場合、開発者が想定する応答を提示したり、事後的にLLMとのやり取りのログを共有したりすることもあります。その場合、レビューを通じてより良い結果を得るために再プロンプトできます。
チームがコード生成前にプロンプトをレビューし、認識を揃えます。
コードを生成してコミットします。
従来通りのプルリクエストで、具体的な出力を正確性、安全性、適合性の観点からレビューします。
このモデルでは、プロンプトリクエストはAI生成作業における上流の認識合わせとして機能します。早期に曖昧さを減らし、下流の差分を小さくし、プルリクエストのレビューを容易にします。
プロンプトリクエストは、後工程のプルリクエストに必要な厳密さを置き換えるものではありません。単に、その厳密さをより早い段階で追加するだけです。
正直に言えば、プロンプトリクエストが完全にプルリクエストを置き換える可能性は低いでしょう。大規模な上場企業が、AI生成コードをそこまで無条件に信頼し、慎重なレビューなしに事業や将来を賭けるとは考えにくいです。
CodeRabbitではプロンプトリクエストに前向きですが、業界全体ではまだ導入初期段階であり、現時点のLLMはプルリクエストを完全に置き換えられるほど成熟していません。
小規模なオープンソースプロジェクトや単独メンテナのプロジェクトでは、プルリクエストの代わりにプロンプトリクエストが使われる未来が、比較的早く訪れる可能性はあります。しかし、現在のソフトウェア開発ライフサイクルにおいて、プルリクエストは依然として不可欠です。特に、本番システム、規制環境、共有責任を持つ大規模チームや、長期にわたって保守される複雑なコードベースでは重要です。
プルリクエストが存在するのは、ソフトウェア開発が最終的に、具体的で決定的な成果物を本番にリリースする行為だからです。その前提が変わらない限り、チームには、実際に動くコードをレビューし、テストし、監査し、承認するための具体的な仕組みが必要です。
より現実的な未来は、「プルリクエストの代わりにプロンプトリクエスト」ではありません。「プルリクエストの前にプロンプトリクエスト」です。
明らかになりつつあるのは、アウトプットの品質が、ますますプロンプトの品質によって左右されるという事実です。プロンプトを第一級の成果物として扱うことは、従来のコードレビューが提供してきた安全策を捨てることなく、この現実を認める行為です。
その意味で、「プロンプトを見せてください」は責任をなくすものではありません。手戻りを減らし、意図を可視化し、プルリクエストの段階を不要にするのではなく、より容易にするために、責任の一部を前倒しするものです。
CodeRabbitを試してみませんか? 14日間の無料トライアルはこちら。



