Erfan Al-Hossami
David Loker
March 12, 2026
7 min read
March 12, 2026
7 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GetStarted in2 clicks.
In practice, developers experience AI code review through the comments it leaves on pull requests: how often it finds real issues, how much noise it produces, and how actionable its feedback is.
To answer those questions, we ran a benchmark comparing Google’s Gemini 3.1 Pro against our internal review baseline, a proprietary blend of OpenAI and Anthropic models tuned for CodeRabbit’s agentic PR review workflow.
Using real pull requests with injected bugs, we measured not just detection rates but the structure and quality of the review comments themselves. The result reveals a clear trade-off: Gemini leaves fewer, more focused comments with a higher signal-to-noise ratio, but it also surfaces fewer bugs overall.

Our benchmark uses an internal dataset composed of real GitHub pull requests into which specific, known error patterns must be addressed. Each error pattern (EP) has a ground-truth description of an issue.
A model "passes" an EP if at least one of its review comments directly addresses or surfaces the root cause of the injected bug, either by proposing a concrete fix or by explicitly identifying the risk with an actionable direction.
We used a suite of 25 hard PRs, each seeded with a known error pattern (EP). Our scoring focuses on:
Actionable comments only: Comments that get posted (not additional suggestions or outside-diff notes).
EP PASS (per comment): The comment directly fixes or surfaces the EP.
Important comments: Either EP PASS or another major/critical real bug.
Precision: EP PASS ÷ total comments.
SNR: Important ÷ (total − Important).
We compared:
Gemini 3.1 Pro
CodeRabbit Production (a proprietary blend of OpenAI and Anthropic models tuned for CodeRabbit’s agentic PR review workflow)

Gemini 3.1 Pro trails on coverage by 4.3 percentage points. It generates 24% fewer actionable comments while landing a slightly higher proportion of them on target (33.3% vs 29.8%). On raw coverage, Baseline has the edge.
The baseline’s nitpick-level comments detect 2 additional EPs (+8.7pp) beyond its main comments, meanwhile Gemini does not detect EPs in its nitpick comments.

Gemini has a higher important-comment rate (77.8% vs 71.9%) and a better SNR (3.5 vs 2.6). Its comments are more likely to be classified as serious issues. It generates proportionally fewer minor comments than our baseline. On signal quality per comment, Gemini is ahead.
Most benchmark posts stop at pass rate and precision. This one doesn't. We ran tone classification on every comment to measure how each model communicates and found a meaningful difference.
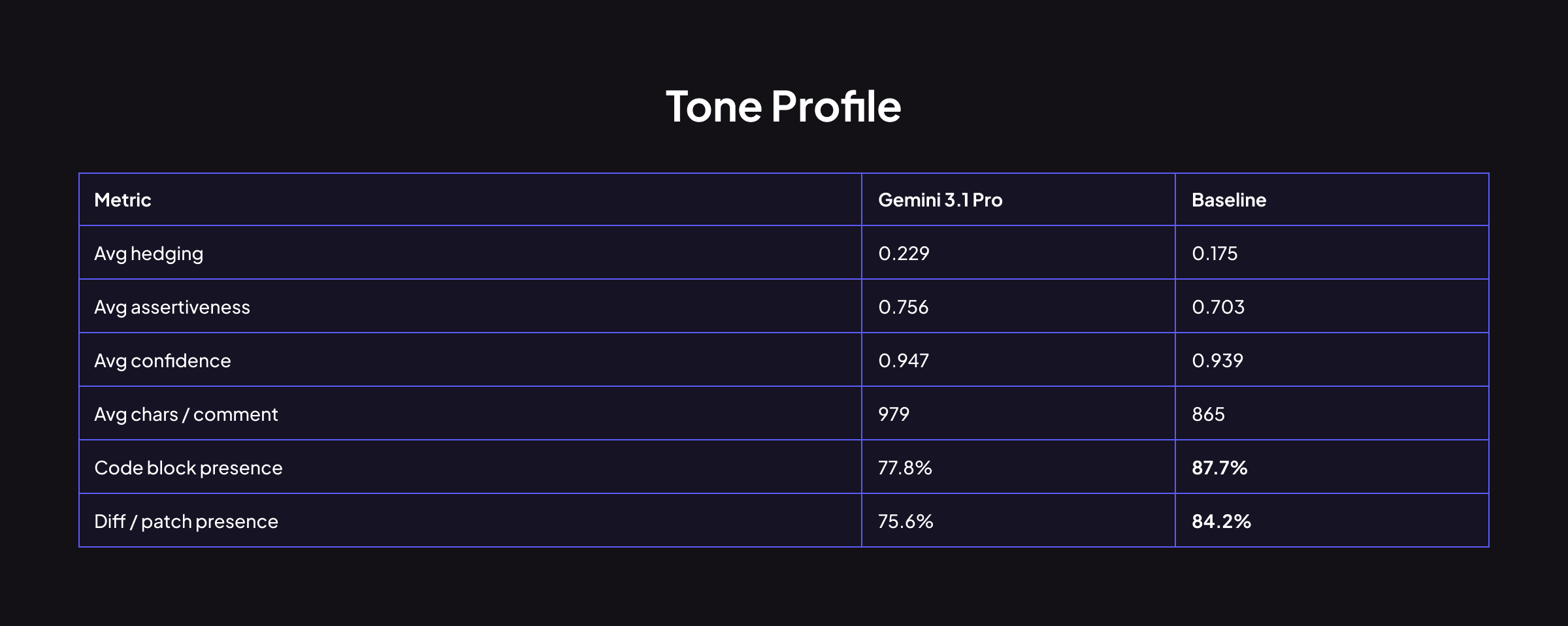
Gemini hedges more (0.229 vs 0.175) but is simultaneously more assertive (0.756 vs 0.703) and more confident (0.947 vs 0.939). This isn't contradictory; it reflects a style where Gemini softens its framing ("you might want to consider…") while its technical conclusions remain decisive. Its comments are longer on average but less likely to include code blocks or diff patches compared to Baseline.
When we split tone metrics by pass/fail outcome, a strong pattern emerges:
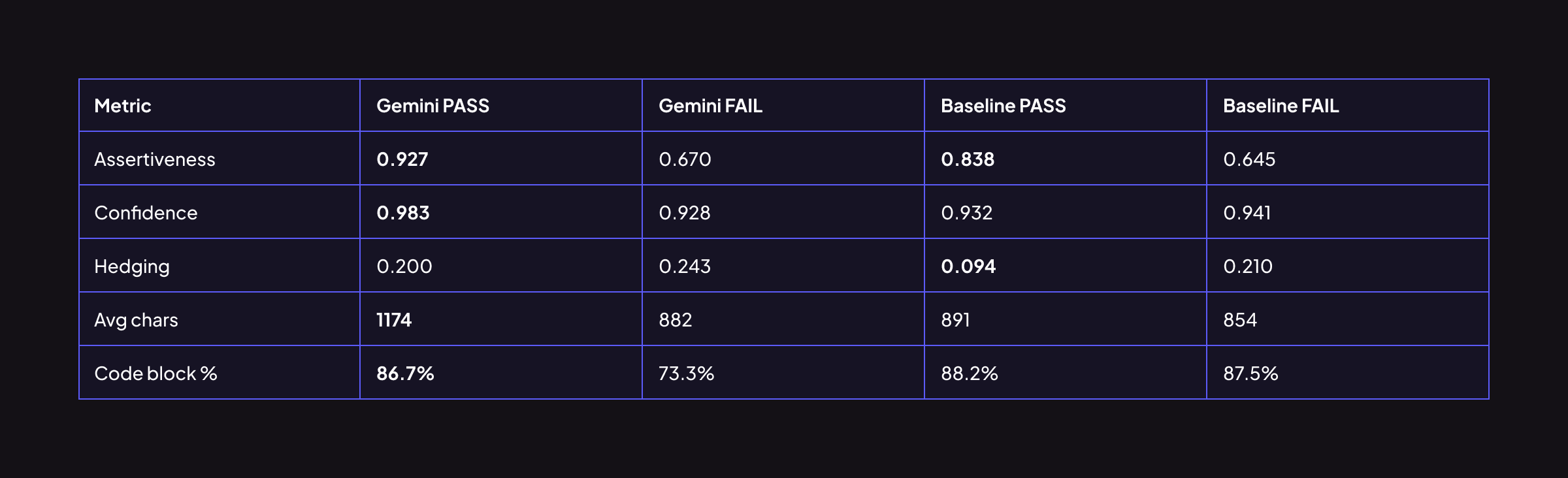
Gemini's passing comments are 38% more assertive and 33% longer than its failing ones. When Gemini catches a bug, it's measurably more decisive, more detailed, and more code-inclusive. Its internal confidence signal is reliable: if Gemini is assertive and long, it's probably right.
Baseline shows the same directional pattern but the gap is narrower; its passing and failing comments look more similar to each other. Baseline's code block rate is nearly identical whether the comment passes or fails (88.2% vs 87.5%). Baseline applies effort broadly; Gemini concentrates it.
This has a practical implication for teams using these models: Gemini's comment tone is a useful proxy for comment quality. A terse, hedged Gemini comment warrants more skepticism than an assertive, code-heavy one. Baseline's comments are more uniformly formatted regardless of accuracy.

Comment density when on target: On the EPs where both models pass, Gemini's passing comments tend to be more specific. Its average passing comment is 1174 characters, nearly 32% longer than a typical Baseline passing comment (891 chars), and concentrates more on the root cause rather than symptom.

Concurrency and threading (56% vs 78% on 9 EPs): This is the critical gap. Nine error patterns covered concurrency bugs, lock misuse, timing dependencies, race conditions, livelock. Gemini detected 5; Baseline detected 7. The 22-point gap on the dominant category in this dataset is what drives the coverage difference.
Gemini 3.1 Pro produces higher-quality, more focused comments with better signal-to-noise, but it covers fewer bugs overall. Its SNR of 3.5 vs 2.6 means a developer reading Gemini's review is less likely to waste time on a low-quality comment.
But with 60.9% EP detection vs 65.2% for Baseline, you're leaving more real bugs undetected. For codebases where concurrency bugs are a material risk, that gap matters.
One finding worth tracking across future evaluations: Gemini's internal tone calibration is strong. Its assertiveness score seems to provide a signal as to whether a comment is likely to address the underlying issue.
That said, these findings are scoped. The benchmark covers 25 error patterns across five repositories spanning Python, TypeScript, C/C++, and a mixed-language GitHub Actions codebase, but the error distribution is weighted heavily toward concurrency bugs (9 of 25 EPs), which is both where Gemini struggles most and where the gap is widest. Results may look different on codebases where OOP, transaction-semantic, or other bugs dominate. The tone calibration finding in particular should be validated on a broader error distribution before being trusted as a source of greater likelihood the comment is right.
Evaluation conducted February 24, 2026. Baseline: Internal baseline on 25 difficult PRs evaluated for Gemini 3.1 Pro. Tone classification by GPT-5.1. Pass/fail determined by independent LLM judge per comment against ground-truth error description.
Interested in trying CodeRabbit? Get a 14-day free trial!