Token prices fell 98% since late 2022 yet enterprise AI bills tripled. Uber burned through its entire 2026 AI coding budget by April per TechCrunch. Gartner predicts that by 2027, 40% of enterprises using consumption-priced AI coding tools will face unplanned costs exceeding twice their expected budgets, increasing demand for structured cost oversight and optimization strategies. For a while, the industry treated token consumption as a proxy for ambition: the more your agents burned, the more "AI-forward" you were.
This logic is flawed as tokens are an input, not an outcome. Goodhart’s Law applies here, as once token consumption becomes the target, it stops being a useful measure of effectiveness. The industry learned this lesson once before with lines of code as a metric to measure developer productivity. Companies are now relearning it with tokens, and the focus shifts towards measuring outcomes per dollar spent.
Nowhere does this matter more than in AI code review. The outcome you are buying is not tokenmaxxing, it is high-quality code, merged and shipped with confidence. That means the system you choose should be optimized for what we call merge maxxing: maximizing merge pull request velocity without compromising quality or cost. Most systems are not built to optimize quality and cost at the same time.
Quality at any cost: The brute-force approach
One approach to AI code review is to optimize for quality by maximizing token spend. For example, at launch, Cursor's Bugbot ran eight parallel review passes over every PR with majority voting to filter noise. Today it's a fully agentic design where the model "decides where to dig deeper," pulling in whatever context it wants at runtime, steered by prompts that encourage it to "investigate every suspicious pattern."
The post details 40 experiments hill-climbing on quality metrics. What it never mentions is token cost. In other words, rather than being smart about it, they've decided to just throw more horsepower at it.
The approach works and it produces precise reviews. But when the agent decides how much to explore, the cost of every review is often unbounded.
Cursor’s Bugbot recently started to charge on consumption, and It charges $1.00-$1.50 per run, depending on PR size and complexity. A community member estimates $7–$10.50 per PR, which lands a developer shipping 15–20 PRs a month at $105–$210 per user, per month. The inefficiency is passed to you.
A general harness: Overbuilt for review, billed by the token
The other common approach points to a general-purpose frontier coding agent at your PR. The harness is built to do anything, including writing features, building spreadsheets, and drafting docs. In code review, that flexibility becomes overhead, and the system burns significant tokens rediscovering context that a purpose-built reviewer would already know.
The result is an expensive review with potentially fewer bugs detected. An example of this is using Claude Code Review for code reviews which average $15–$25 per PR, billed on token usage and scaling with PR complexity. At typical velocity, that's $225–$500 per user, per month. And the incentive structure is worth noticing: when the vendor bills by the token, every token the harness burns is revenue.
Both roads lead to rationed reviews
The hidden cost of these tools is behavioral, and over time it becomes a quality problem. When review is metered, spend controls become quality controls. These tools often let teams configure when reviews trigger, how often they run, and how much effort the reviewer applies.
But, the moment you start adjusting review behavior to manage a bill, you are also deciding which code gets scrutiny. Your team might review the “high-stakes” PRs, skip the re-review after revisions, and think twice before pushing another iteration.
This does not mean every skipped review ships a bug but fewer issues are caught early, when they are cheapest to fix. Rationing review pushes that cost downstream, closer to production, where defects are harder and more expensive to fix.
CodeRabbit: Relentlessly optimizing both quality and cost
We do not believe that teams should have to choose between quality and cost. A well-built review system should deliver both and be efficient and accurate. Every irrelevant token in a model's context window dilutes its attention and raises the odds it misses a real bug. The discipline that strips waste out of the system is the same discipline that makes reviews accurate.
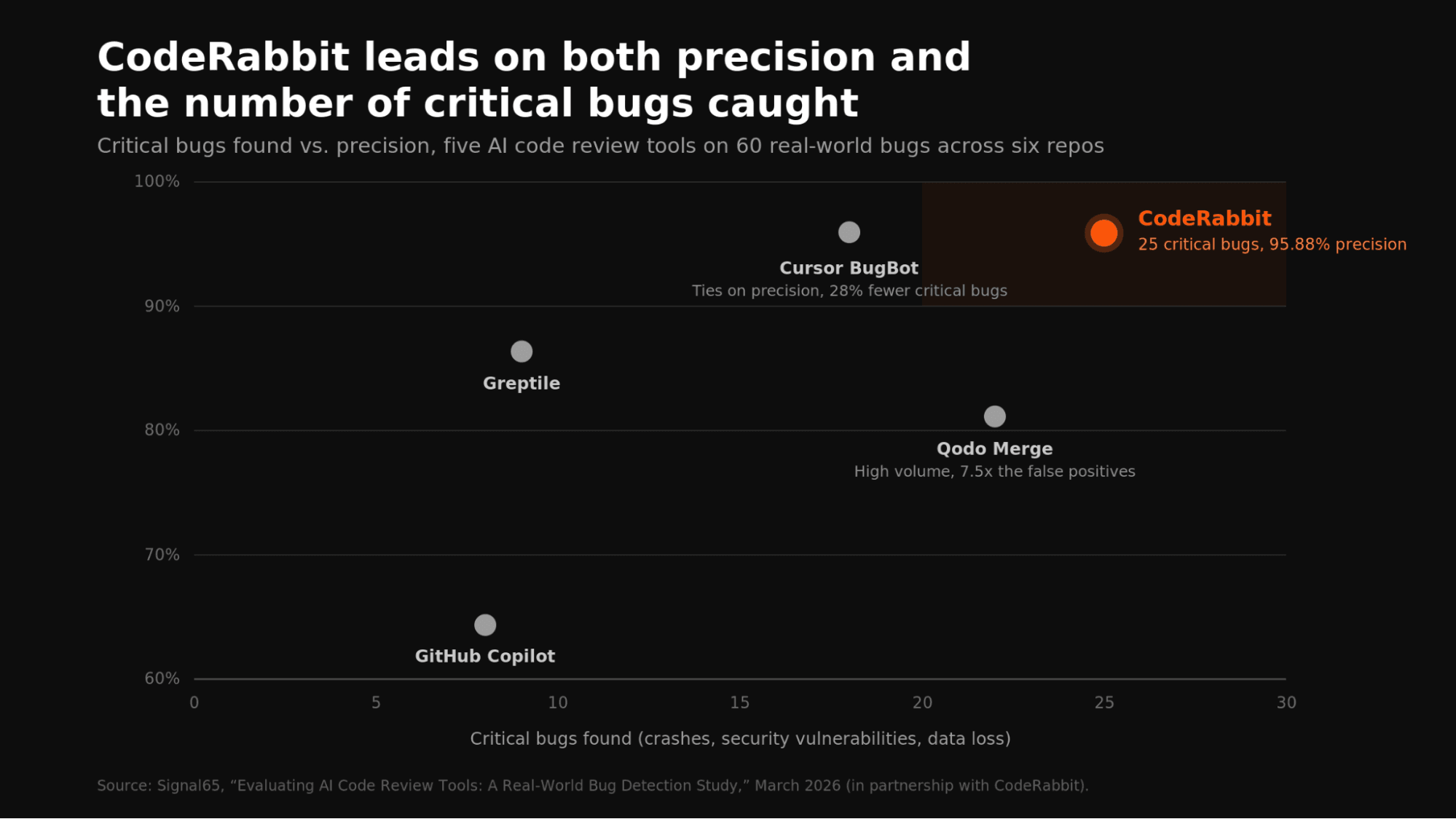
In a hands-on evaluation by Signal65 testing five AI review tools against real historical bugs across six open-source repos, CodeRabbit found the most critical bugs such crashes, security vulnerabilities, data loss at 95.88% precision. It was the only tool to lead on both dimensions simultaneously. The nearest competitor on precision found 28% fewer critical bugs. Martian’s evaluation showed the same pattern. CodeRabbit leads on F1 score and, more importantly for code review, recall: the measure of how many real issues a system catches.
Every PR gets that same caliber of review, giving teams the confidence to merge and ship. Under the hood, that outcome comes from two approaches (token and cost optimization) and three key technologies (Context discipline, Smart LLM Routing, and Prompt Caching) working together.

Token optimization: Engineering the context
Better reviews come from better-selected context. This is known as context discipline, a subset of context engineering. CodeRabbit has built this technology into its context engine, avoiding overwhelming the LLM with irrelevant information or missing the critical context that would make the review more accurate.
Distillation at every layer. Every context source, including the code graph, MCP integrations, documentation, coding guidelines, learnings, and static analysis output pass through a processing layer that extracts only what's relevant to the PR at hand. CodeRabbit deliberately spends a majority of its input tokens in this enrichment phase to give the reviewer better context. A function your PR calls might be hundreds of lines long, but the review agent may only need a precise summary of what it does.
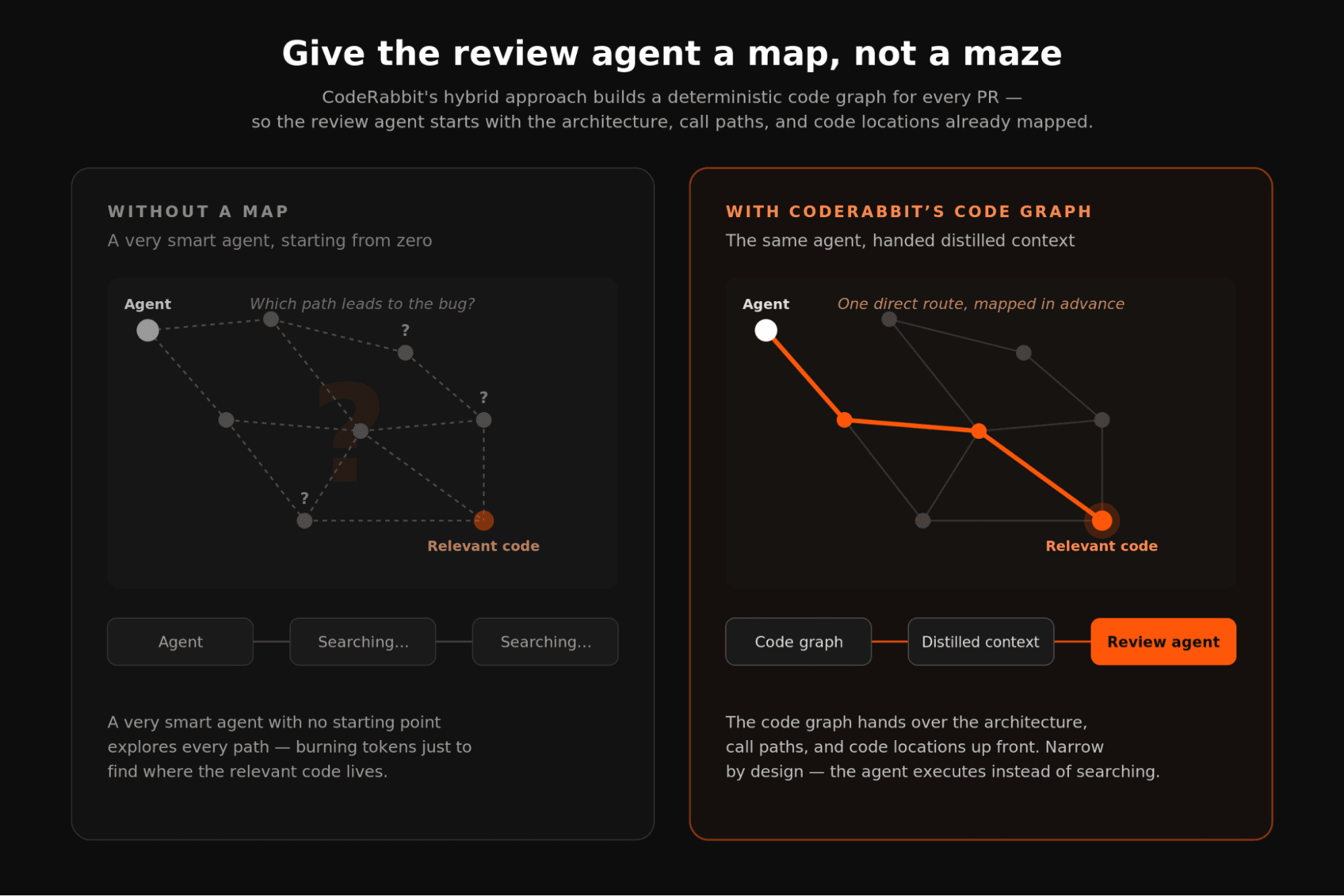
Domain expertise instead of open-ended exploration. At CodeRabbit, we approach review as experienced engineers: we know the baseline signals a good reviewer needs before it starts reasoning. So we do not leave that discovery entirely to the agent.
CodeRabbit uses a hybrid AI approach to code review, combining deterministic analysis with agentic reasoning. For every PR, it builds a deterministic code graph for every PR, so by the time the agentic steps begin, the agent already understands the architecture, the call paths, and where the relevant code lives. Its discovery path is narrow by design as we tell it where to start, so it does not have to spend extra tokens figuring out how to find out.
Cost optimization: Engineering the spend
Cost optimization is making every remaining token as cheap as possible without losing quality.
Smart LLM Routing CodeRabbit has a dedicated engineering team continuously evaluating and benchmarking models to understand where each one improves the system, where it simply adds cost, and where a smaller model can do the job better.
Compact models handle distillation, while the largest multi-step reasoning models are reserved for the review agent, where deeper analysis pays off. Larger models are not automatically better, and when a task does not require that level of reasoning, they can add latency, noise, and unnecessary complexity. Per-task routing keeps each part of the system matched to the work it is best suited to do, improving both efficiency and review quality.
Intelligent incremental reviews using Prompt Caching CodeRabbit treats every follow-up review as incremental. Unchanged code is not reviewed from scratch, and stable parts of long prompts can be cached instead of present on every iteration. This is also known as Prompt Caching and allows the reviewer to focus its attention, reasoning, and tokens on what actually changed.
Purpose-built efficiency, passed on to customers
The token and cost optimization are passed onto our customers. Many teams start by building their own AI review systems and do not realize how quickly token spend adds up, especially when a frontier model is used for every task in the review pipeline. Some customers tell us they are already spending thousands of dollars a month on tokens alone for small teams, and that the approach does not scale.
Token cost is only part of the problem. Model routing, context distillation, benchmarking, and keeping up with every new model release require expertise and infrastructure most teams do not have the knowledge and time to build. CodeRabbit absorbs that complexity and turns it into business value for customers.
A little optimization goes a long way
In an internal experiment by our VP of AI, David Loker, he built a simple review system with no domain intelligence or context engineering. It churned through roughly 200,000 tokens to find a single bug. With a small amount of domain-informed optimization, the updated version found the same bug with about 18,000 tokens total: roughly 17,000 tokens for the diff itself, plus only about 1,000 additional tokens of targeted context. That is a 91% reduction in total tokens!
CodeRabbit delivers the best ROI in AI code review
And that was one simple optimization loop. As a pioneer in AI code review, CodeRabbit has spent the past three years refining the engineering and technology behind context discipline, smart LLM routing, and prompt caching for AI review. That accumulated optimization is passed directly to customers. We know, and continue to refine, which context matters, which signals add noise, and which review patterns actually catch bugs.
That is how CodeRabbit delivers the best ROI for code review. Teams get high performance, predictable seat-based pricing, and flexible usage-based add-ons for high-throughput agentic loops, so they can ship high-quality code with confidence.
Maximize merges, not tokens
The point of AI code review is not to consume more tokens, but to help teams ship better code faster, with fewer production issues and less review bottleneck.
That is what CodeRabbit delivers, high-quality reviews on every PR. Developers get continuous feedback without wondering whether another review is worth the bill, and engineering leaders get the confidence that review quality is scaling with the team, not being rationed by token spend.
Mergemaxxing is the better metric, and every PR is reviewed, real issues caught early, developers free to iterate, and code shipped with confidence.
Out with token maximization. In with merge maximization.
Ready to ship high-quality code with confidence? Start a 14-day free trial or talk to our sales team to see what best-in-class review performance looks like on your repos at a cost you can predict.