

Atsushi Nakatsugawa
September 05, 2025
2 min read
September 05, 2025
2 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
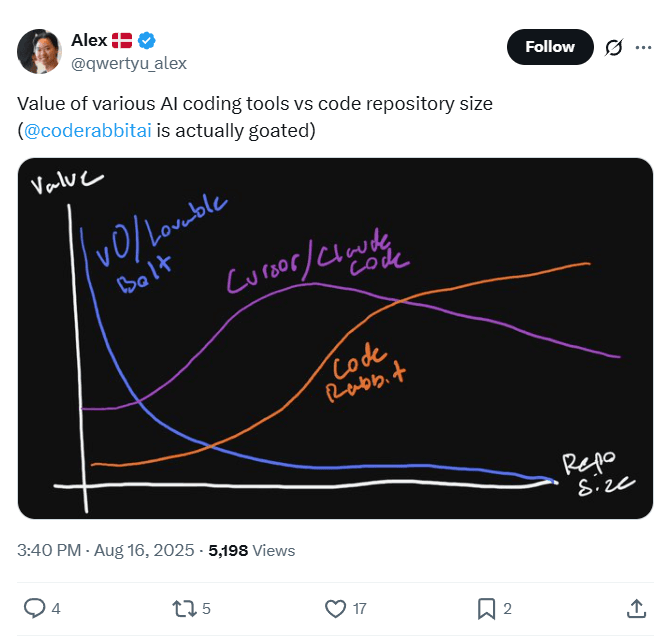
How CodeRabbit delivers accurate AI code reviews on massive codebasesの意訳です。
大規模なコードベースは特別な存在です。数百のファイルに広がり、何年ものコミットで進化し、時にはなんとか組織的な記憶でつながっているように見えることもあります。その環境で変更をレビューするのは難しいだけでなく、まるで考古学の発掘作業のようです。この行が先週ここに移動したのは理由があったのか?他のファイルが密かに依存しているのではないか?
まさにそこでCodeRabbitが力を発揮します。スケールに対応するよう設計されているため、ファイルごとのバラバラなコメントになることなく、大規模コードベース全体の履歴とアーキテクチャを考慮してレビューを行います。リポジトリが大きく古いほど、CodeRabbitは役立ちます。人間がプルリクエストの途中で忘れてしまいがちなパターン、依存関係、ルールを見抜けるからです。
CodeRabbitは大規模リポジトリで高いパフォーマンスを発揮することで知られています。私たちのツールはプルリクエストを表面的に読むだけではなく、アーカイブ役のように振る舞います。コメントを残す前に、周辺のコードや多数の文脈を引き込みます。AIエージェントはそれらが履歴の中でどう動いてきたかを追跡し、チームのコーディング規約を適用し、スクリプトやツールで自らの推論を二重チェックします。
その結果、レビューは異常なほど「文脈に詳しい」ものになります。クロスファイルの問題を事前にキャッチし、一貫性を強制しつつも不要な指摘は避け、複雑で長い過去を持つリポジトリ全体にスケールします。
得られる結果は明確で、早い段階でのリスクに対するフィードバック、予期せぬ副作用の減少、そしてコードベース全体を理解したレビューになります。
コードの差分は必要ですが十分ではありません。大規模コードベースでは、10行の変更が複数サービスで共有されるヘルパーを密かに変えたり、公開されているAPIの要件を変更したり、差分ファイル以外のセキュリティ前提を崩したりすることがあります。
差分だけを見るAIレビューは、大規模コードベースでは計器なしで飛んでいるようなものです。変更箇所がどこで参照されているのか、他に一緒に変わりやすいコードは何か、チケットの意図に合っているかが見えなければ、小さなコードベースでは通用しても大規模コードベースでは役立ちません。
文脈がないと「これも更新してもらえますか?」というやり取りが繰り返され、マージ時に遅れて驚きが発生し、小さなリグレッションが積み重なります。紙の上ではレビューが良く見えても、本番では違う結果になるのです。
CodeRabbitを「意見を出す前に調査ファイルを組み立てる存在」と考えてください。そのケースファイルには以下の要素が含まれ、それぞれがレビューに反映されます。
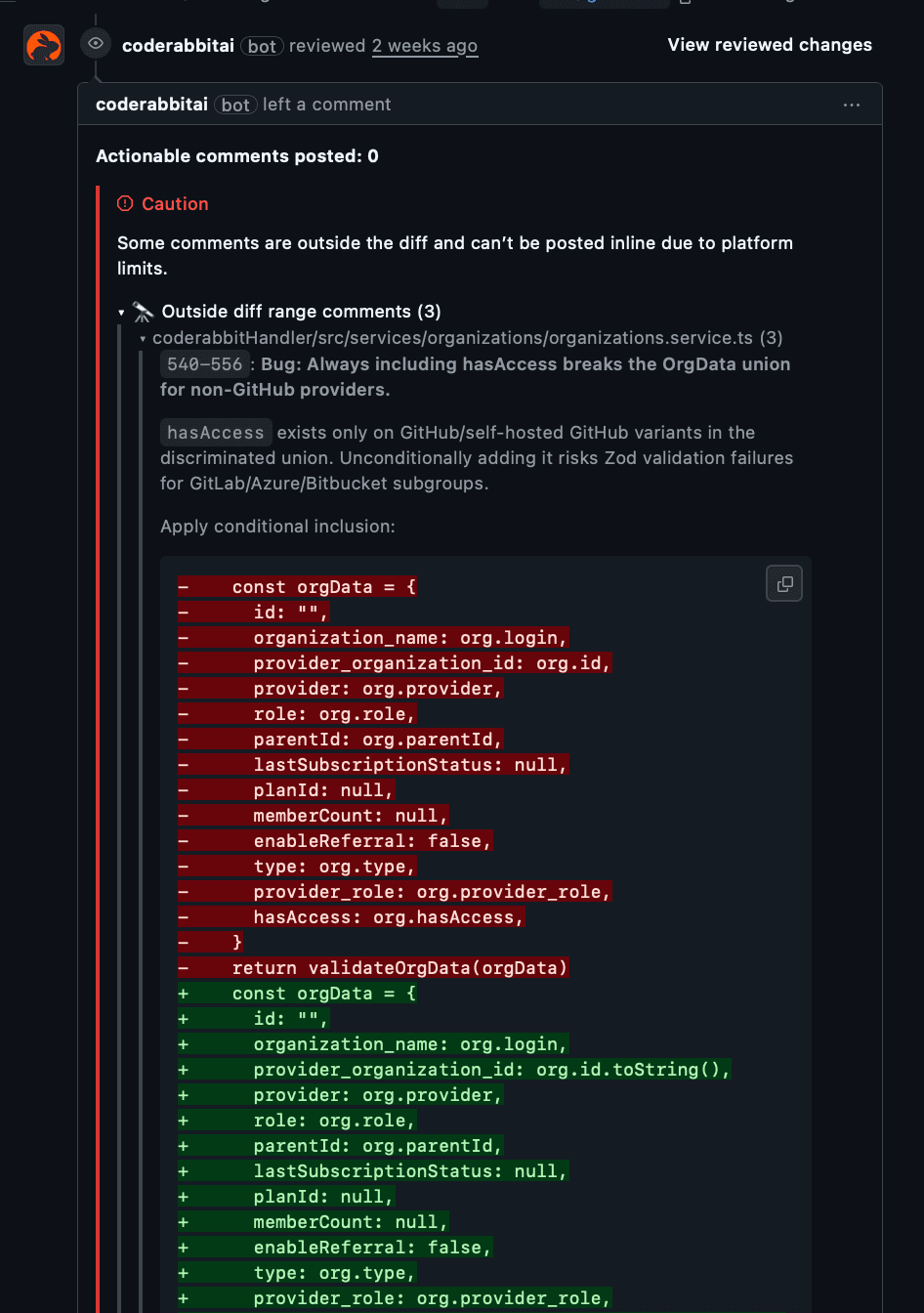
CodeRabbitは定義と参照の軽量なマップを構築し、履歴をスキャンして頻繁に一緒に変更されるファイルを特定します。これにより、依存関係のマップを作成し、PR内の変更が他の依存関係を壊さないかを確認します。
なぜ役立つか: 行単位ではなくファイル間で推論できる。
実際の動作: Codegraphを使って関連ファイルを辿り、差分外で見つかったバグをまとめて通知します。
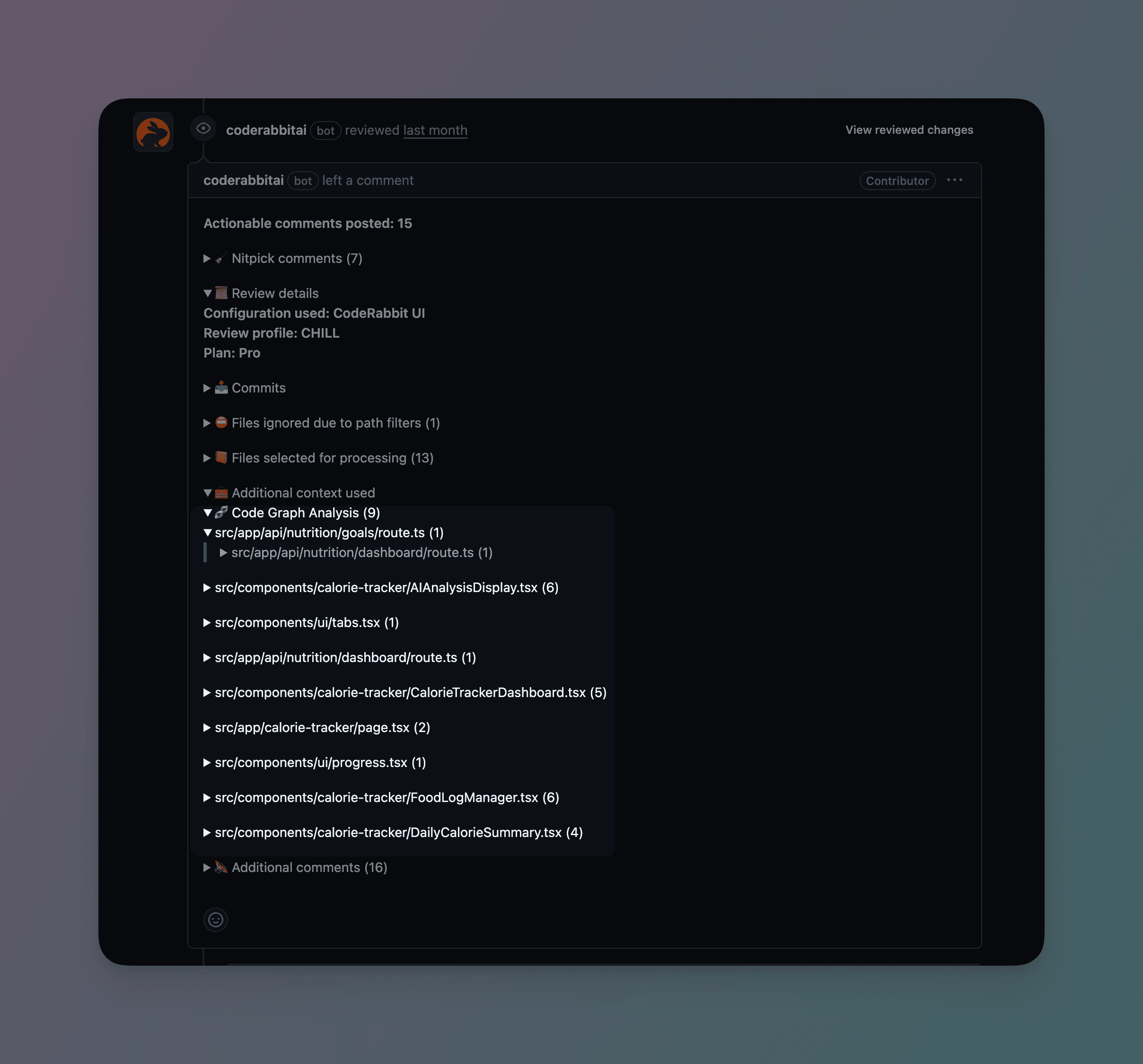
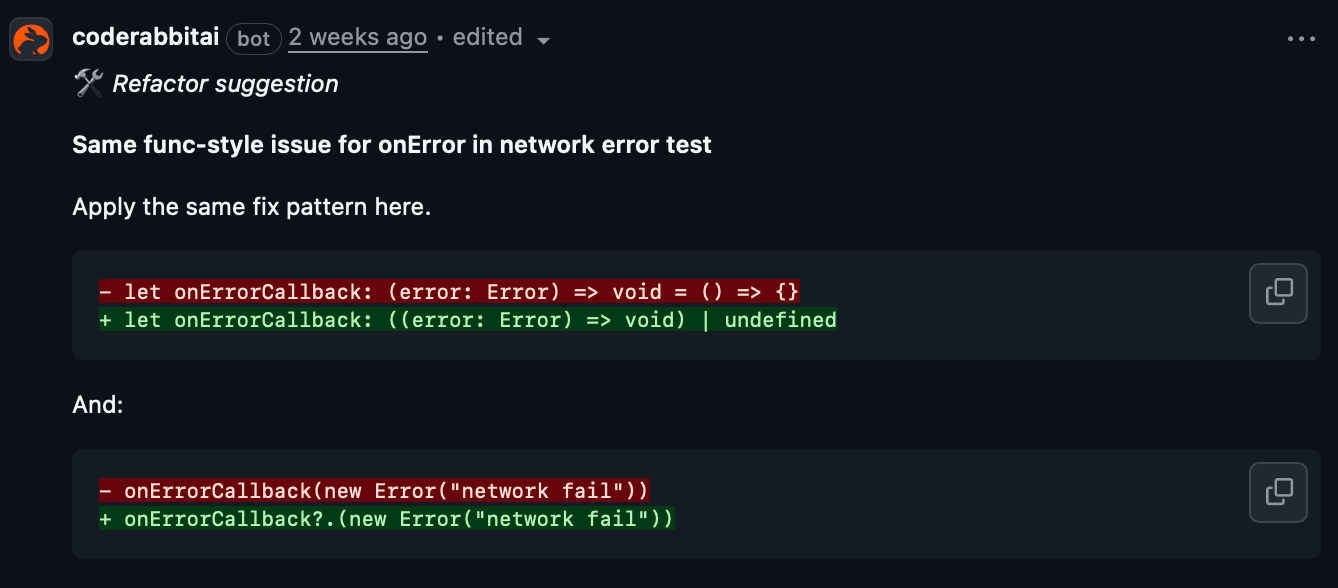
CodeRabbitは関数、クラス/モジュール、テスト、過去のPRや変更のセマンティックインデックス(埋め込み)を保持します。レビュー時にはキーワードではなく目的ベースで検索し、類似実装を見つけ、再利用すべきテストを引き出し、過去の修正方法を思い出します。
なぜ役立つか: レガシーコードベースですでに解決している方法を参照でき、一貫性向上、手戻り削減、テスト拡充が速くなる。
実際の動作: 類似検索により同じコールバックパターンを使った別のテストを提示し、同じ修正を提案します。
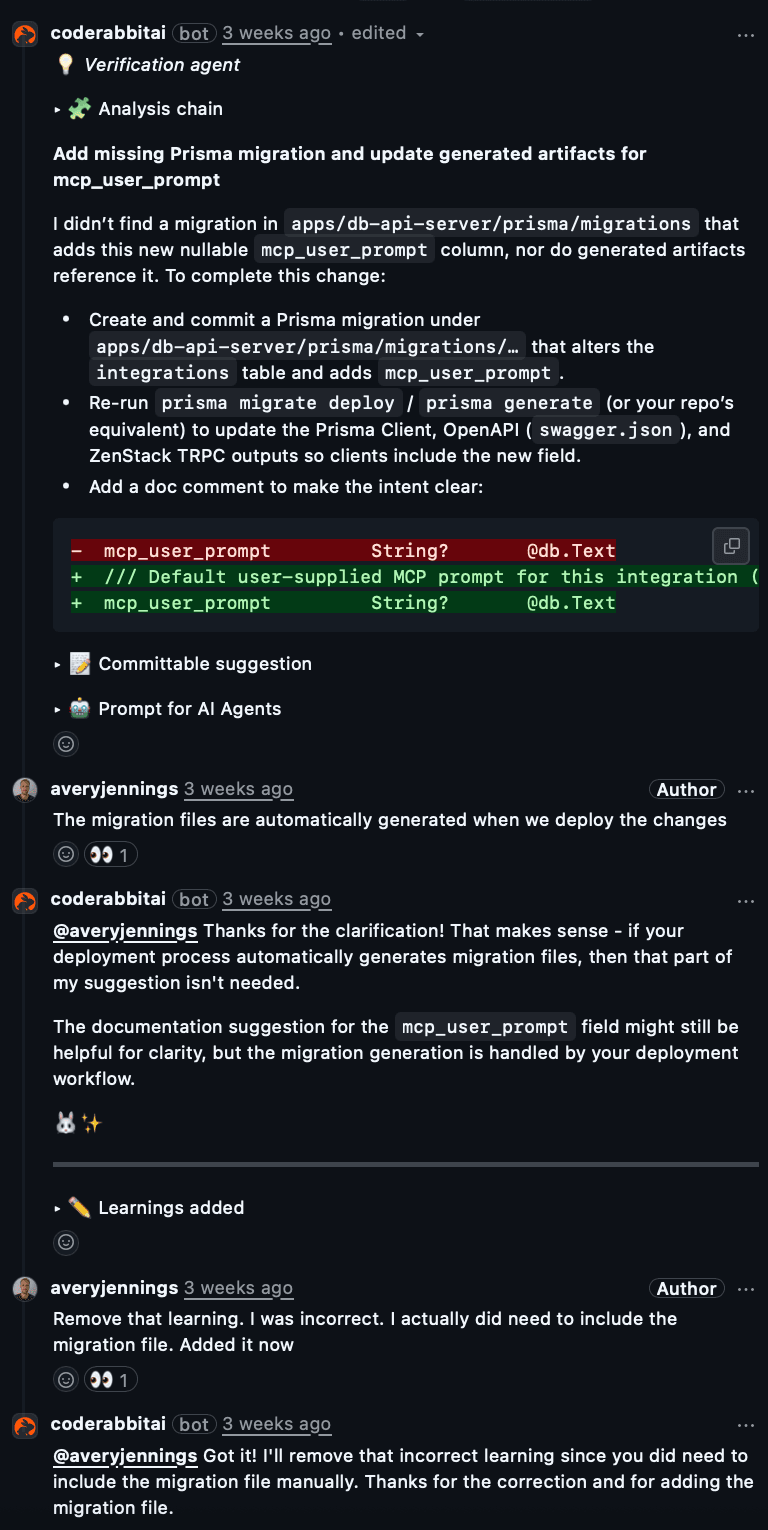
CodeRabbitのレビューはチームの規約(命名、エラーハンドリング、API境界、セキュリティ要件、性能要件、テスト規範など)に基づいて行われます。
なぜ役立つか: 一般的なチェックリストではなく、チーム固有の基準に沿ったフィードバックが得られる。
実際の動作: スキーマ変更後にPrismaのマイグレーション不足を指摘。開発者が「デプロイ時に自動生成される」と返答すると、CodeRabbitはそれを学習として保存し、将来の誤検出を避けます。
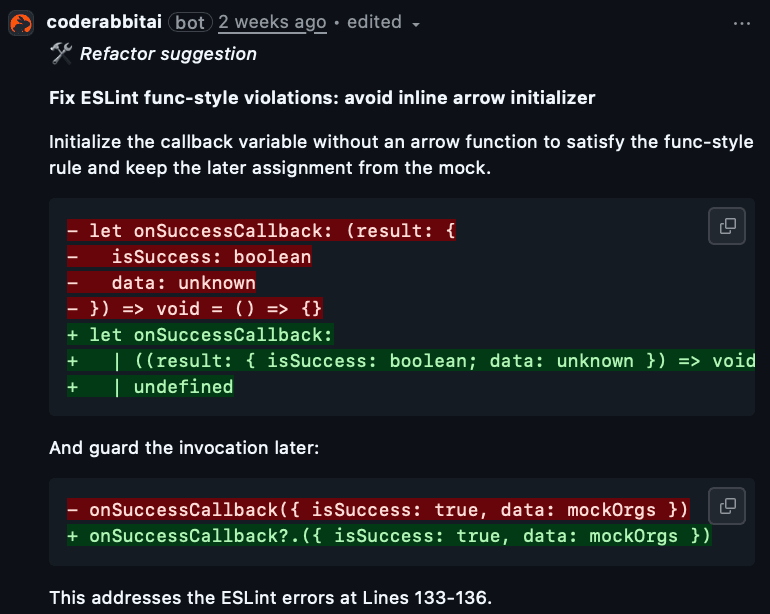
AIの推論と並行して、CodeRabbitはリンターやセキュリティ解析ツールを実行し、その結果をレビューに統合します。
なぜ役立つか: AIとツールの両方に裏打ちされた具体的な改善提案が得られる。
実際の動作: ESLintルールと行番号を示し、コールバックを型付き宣言に書き換え、オプショナルチェイニングで安全性を確保します。
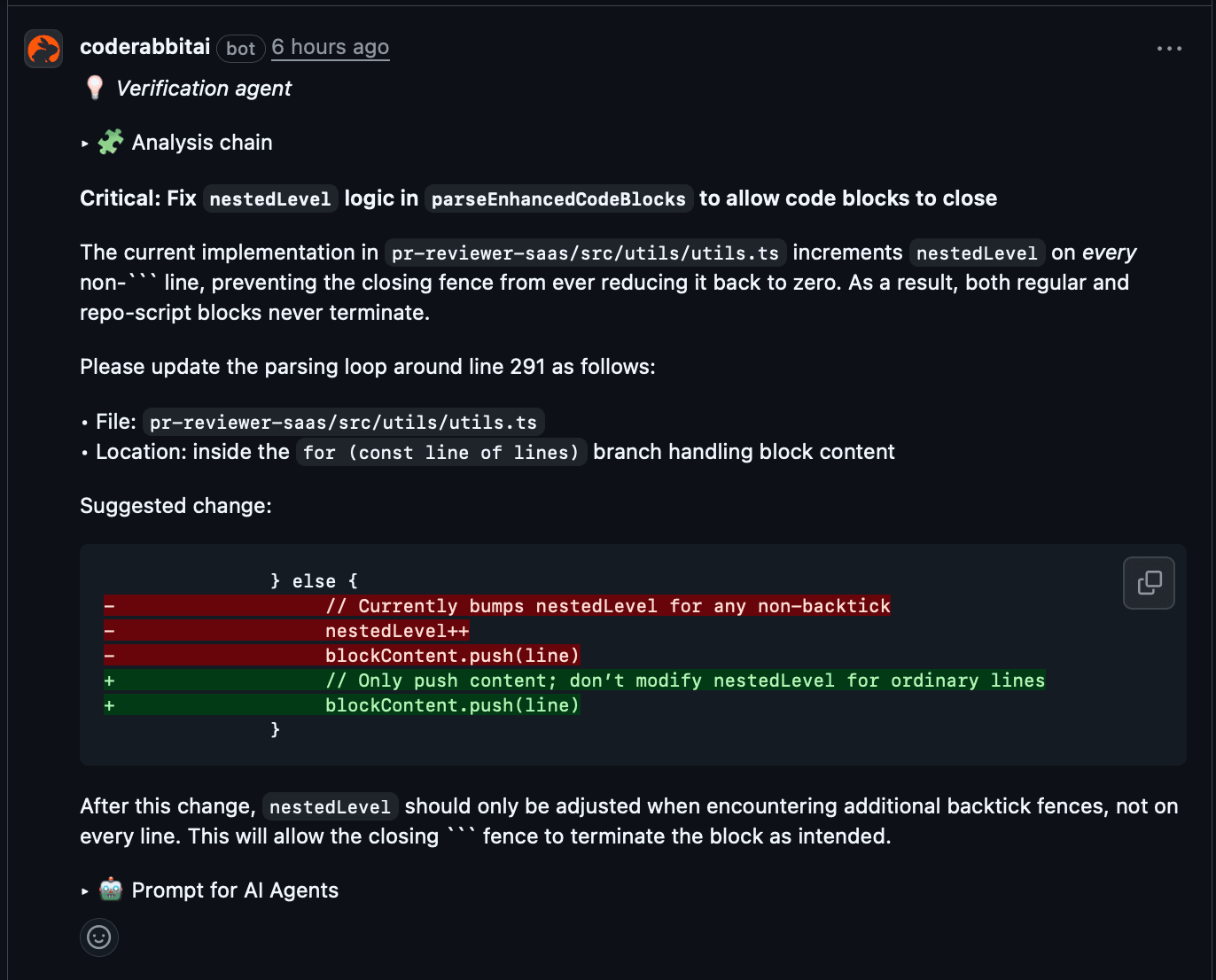
検証が必要な場合、CodeRabbitはシェル/Pythonスクリプト(grepやast-grepのようなもの)を生成し、仮定を確認したり証拠を抽出してからコメントを残します。
なぜ役立つか: コメントに裏付けがあるため、ノイズが減り、実際にコードを改善する指摘だけが残る。
実際の動作: ファイルとループを特定し、失敗モードを説明し、検証エージェントが解析後に導いた正確な修正案を提案します。
これは実践的なコンテキストエンジニアリングです。正しい情報を集め、絞り込み、整理してからモデルに判断させる。CodeRabbitは創業時からこのアプローチを核としてきました。
成果はシンプルです。シグナルが強く、ノイズが少なく、システムを理解しているレビューになります。
CodeRabbitはスケールを意識して設計されたパイプラインにより、大規模・レガシーコードベースで強みを発揮します。
PRが届くと、CodeRabbitは隔離された、短期間だけの安全な環境を立ち上げます。必要なものだけを取得し、文脈を構築し、検証を実行し、終了後に破棄します。ピーク時には多数のワーカーが並列実行され、レビュー速度は一定に保たれます。パスフィルターで不要なアセットを除外し、キャッシュやインデックスを選択的に有効化して繰り返しのレビューを高速化できます。
要するに、範囲の選択で文脈を集中させ、隔離で安全性を確保し、弾力性ある実行方法で高速性を維持します。この手法はコードベースとリリーススケジュールに合わせてスケールします。
CodeRabbitの強みは単一のトリックではありません。コンテキストエンジニアリングを端から端まで適用する姿勢にあります。変更が何に触れるかをマッピングし、意図に結びつけ、チームルールを適用し、ツールで検証し、証拠付きでコメントします。
このやり方は「コンテキストエンジニアリング」という言葉が流行る前から一貫しており、スケールした環境で正確でノイズの少ないレビューを実現する唯一の方法です。
あなたの大規模コードベースで深い文脈を持つレビューを体験してみませんか? → 14日間のトライアルを開始する



