
CodeRabbit is now in the Claude Marketplace!Learn more

Tommy Elizaga
September 17, 2025
9 min read
September 17, 2025
9 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Once upon a time, getting context into an LLM meant stringing together hacks, prayers, vector strategies, and overly complex RAG pipelines. Then came the Model Context Protocol (MCP), a clean, modular way to serve external data to models in production. It quickly became the protocol of choice for anyone building agentic systems that are trying to actually do things.
Every tech company is now launching MCP functionalities – and for good reason. MCP separates context logic from application logic, improves reliability, and helps tame the chaos of prompt construction in complex workflows.
We’ve been deep in the context engineering space for a while, and as we launch our own MCP client, we’re genuinely excited by how it lets us inject richer context into our code reviews. But let’s be honest: with great context comes great risk. Because here’s the dirty secret of the MCP era: most of us are now drowning in the context we used to beg for. More logs, more traces, more diffs, more "relevant" files and way less clarity about what the model actually needs.
What starts as helpful input quickly turns into token bloat, noise, and degradation in model performance. Think hallucinations with citations, latency spikes, or reviews that read like they were written by an over-caffeinated intern who rambles. Good context engineering isn’t about cramming in everything, it’s also about knowing what to leave out. And in the aftermath of MCP, that balance is harder (and more important) than ever.
In this article, we’ll break down the ballooning context problem, what happens when well-intentioned context goes rogue, and how we’re tackling it head-on. If you’re shipping LLM-based features with MCP and want to avoid accidentally building a prompt-shaped black hole, this blog is for you.

MCP servers and clients make it easy to hand models a firehose of information: logs, traces, diffs, configs, tickets, and sometimes even that dusty corner of the repo nobody remembers owning. It’s all right there at the model’s fingertips. But here’s the question: is more context always better? Definitely not!
Too much context is like cramming for an exam by reading the entire library. You end up with noise, not knowledge. And when context goes unchecked, three problems show up fast:
Token bloat. LLMs don’t have infinite stomachs. Input windows are expensive and finite, and stuffing them full of “just in case” details means higher costs, slower throughput, and wasted budget on irrelevant text.
Relevance decay. More information doesn’t mean better outputs. In fact, it often means worse. Irrelevant or redundant snippets dilute the signal, and the model starts chasing tangents instead of insights.
Latency. Every extra log, diff, or stack trace has to be fetched, processed, and shoved into the prompt. Context building becomes the bottleneck, dragging review speed down to a crawl.
In short, ballooning context turns the elegance of MCP into a liability. Without deliberate context engineering, the very thing meant to sharpen outputs can just as easily smother them.

In practice, we see three common pathologies:
Context confusion. This happens when the model latches onto irrelevant detail and treats it as signal. Imagine a pull request that updates authentication logic but the context dump also includes unrelated test fixtures. The model might start reviewing the fixtures instead, producing comments that feel informed but have nothing to do with the actual change.
Context clash. Not all context agrees with itself. Suppose a code review includes both the latest schema migration and an outdated docstring that contradicts it. The model now has to “choose” which source to trust. Often, it hedges, producing muddled reviews that cover every angle without real confidence: the LLM equivalent of a reviewer who can’t commit.
Context poisoning. The most insidious case is when bad information makes it into the context. A hallucinated “related file” or a mis-indexed snippet gets injected, and suddenly the model is citing non-existent code. In a review, that looks like a comment about a bug in a file that doesn’t exist, confusing developers, wasting time, and eroding trust.
And it’s not just code reviews. The same pitfalls show up anywhere context gets overstuffed: customer support bots pulling in irrelevant tickets, research assistants distracted by tangential papers, or security agents treating noisy logs as hard evidence. In each case, the wrong context is worse than no context at all.
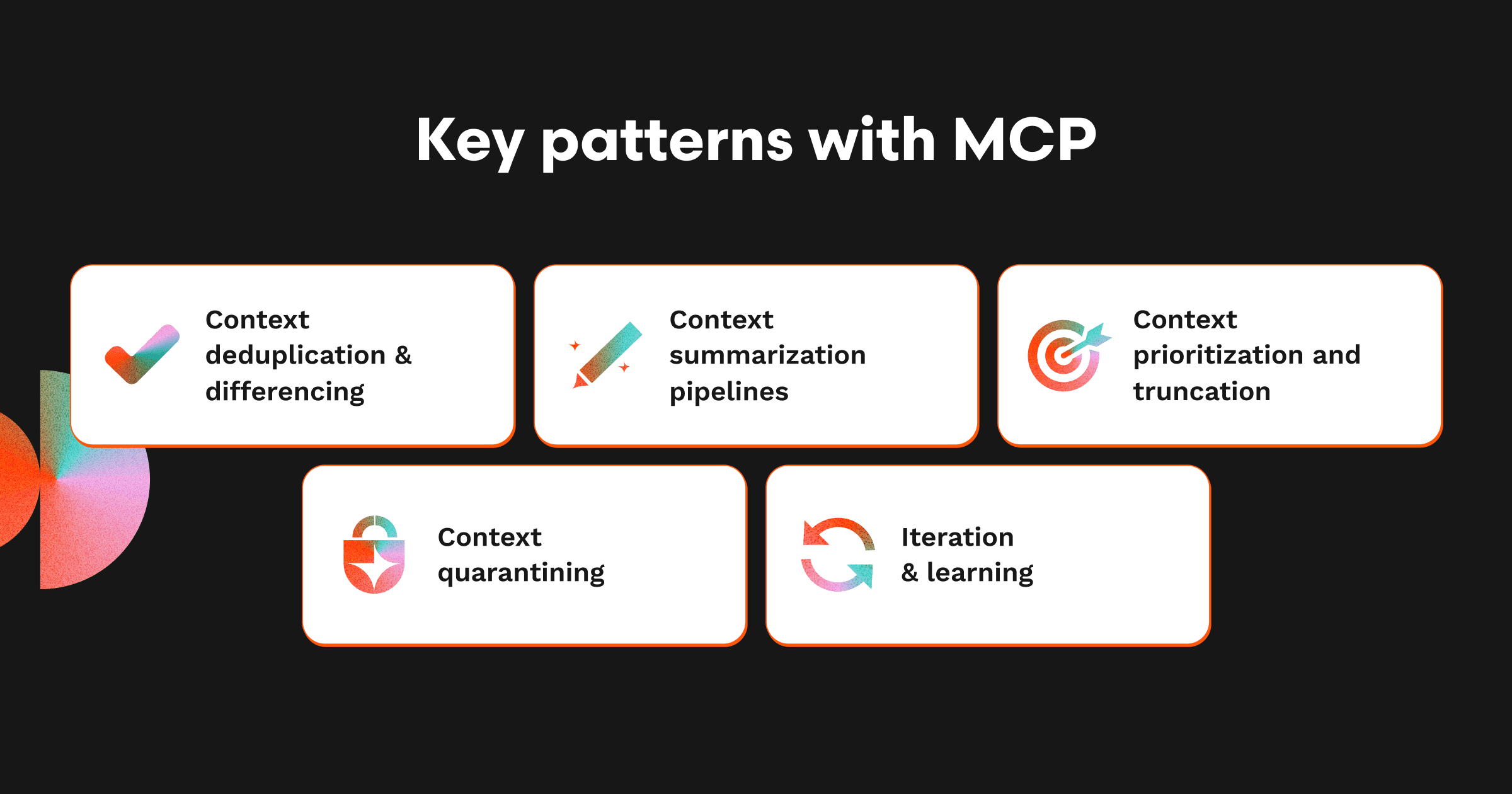
If the problem of the MCP era is ballooning context, the solution isn’t to stop piping in information — it’s to curate, compress, and serve it with intent. MCP context should be treated as raw material that goes through a well-designed data transformation process before it ever reaches the model. For our own MCP client for code reviews, we’ve leaned on a set of patterns that keep context high-signal and low-noise.
Context deduplication and differencing
Redundant inputs are the fastest way to waste tokens. Identical stack traces, repeated log lines, or unchanged sections of a diff don’t need to appear ten times. Our client identifies duplicates, collapses them, and highlights only what’s new. The same principle applies in other domains: collapse duplicate customer tickets, compress recurring traces, and reduce context to delta rather than bulk.
Context summarization pipelines
Sometimes raw MCP output is still too big. Here, LLMs themselves can help by summarizing retrieved context into something smaller. The tradeoff is compression vs. fidelity: a summary might miss nuance, but the alternative is a model drowning in detail. In practice, we use hybrid designs: raw diffs for high-priority files, summaries for less-critical context.
Context prioritization and truncation
Even after pruning and summarizing, you still need to decide what goes first, what can be deferred, and what gets dropped if there isn’t room. Setting a token budget per MCP query is critical, or else prompts will balloon unpredictably. We’ve experimented with truncation-aware designs; sometimes front-loading summaries for quick orientation, other times end-loading detail for deep dives. The “right” design depends on the workflow and the model’s feedback loop.
Context quarantining
Not every piece of context belongs in the first prompt. Subtasks should carry their own dedicated context threads, so the model sees exactly what it needs when it needs it. For example, in our MCP client, test failures live in a dedicated review sub-thread rather than clogging the main review context. This approach reduces confusion and helps preserve clarity across long interactions.
Iteration and learning
Context engineering isn’t static. We use model feedback and human-in-the-loop corrections to tune priorities over time. Observability is key: logging actual prompt inputs, broken down per module, lets us see what’s getting through and what’s wasted. Tooling like MCP dashboards or token heatmaps can highlight where budgets are blown or irrelevant inputs are sneaking in.

The MCP era makes context retrieval easy. Maybe too easy. A couple of common anti-patterns are worth calling out:
Blind vector stuffing
Vector databases are great at surfacing “relevant” chunks of information, but treating them as an oracle is a recipe for trouble. Stuffing in every vaguely related snippet means you get reviews full of tangents: comments about files that weren’t touched, or nitpicks based on stale code. Context irrelevance doesn’t just waste tokens — it actively drags down model performance by pulling attention away from the real task.
“Just give it everything”
The brute-force approach: dump every log, diff, and docstring into the context window and pray. This guarantees high costs, long latencies, and unpredictable results. The model can’t tell which parts are critical and which are fluff, so you end up with bloated reviews that read like they were written by an overeager intern trying to cover every angle. Worse, when contradictions sneak in, the model hedges or hallucinates to reconcile them.
In short: more context isn’t always better. Without filtering, prioritization, and careful design, “everything” quickly turns into noise that makes the system slower, dumber, and more expensive.
In the MCP era, context is king. But let’s be honest: sometimes it’s a king that’s had one too many and can’t tell up from down. The challenge isn’t getting context anymore; it’s taming it. Great context engineering requires careful transformation pipelines, ruthless prioritization, and the humility to keep iterating. Done poorly, you get token bloat, latency, and reviews that sound confused. Done well, you get sharper outputs that scale with your workflow.
We’ve seen this firsthand in our own MCP client for code reviews. When testing, we initially passed full logs and entire file sets straight through. The result? Expensive reviews that rambled more than they helped. Once we introduced deduplication, summarization, and task-specific quarantining, review quality jumped. Instead of commenting on everything, the model zeroed in on real cross-file risks, while token use and latency both dropped.
That’s the payoff of good context engineering: reviews that feel informed, not bloated. And that’s what we’re building toward with our MCP client.
👉 Ready to see context done right? Start your 14-day trial of our AI code reviews.



