The history of AI coding agents begins before anyone seriously called them agents. In 2017, Attention Is All You Need paper introduced the Transformer, the architecture that made modern large language models possible.
In 2020, CodeBERT brought that foundation closer to software development by showing that natural language and programming language could be learned together in a single pretrained system for tasks like code search and documentation generation.
These were not agents in the modern sense. They did not open files, run tests, or act inside a development environment. But they established the premise that made everything else possible. Code could be modeled as language, and language models could learn useful representations of how software is written, explained, and transformed.
By 2021, that line of research had matured into practical, testable code generation. Codex 2021 described a GPT model fine-tuned on publicly available code and evaluated with HumanEval. GitHub announced Copilot on June 29, 2021 and the Codex paper followed on July 7, explicitly noting that a distinct production version of Codex powered Copilot. That detail matters because it marked the bridge LLMs crossed from research artifact to mainstream developer product.
Copilot made AI coding feel native

When Copilot arrived, it did something historically more important than “write code.” It made AI feel native to the act of programming. GitHub described Copilot as an AI pair programmer that could draw context from the code around it and suggest whole lines or even entire functions inside the editor.
That sounds ordinary now, but in 2021 it was a genuine interface breakthrough. Code generation stopped living in research demos and started living on the editing surface itself, where latency, relevance, and developer trust mattered more than abstract benchmark scores.
That is why Copilot accomplished more than a traditional autocomplete tool. Its significance was not just model quality. It was the product decision to put the model directly into the workflow of writing software.
GitHub’s later research found that Copilot users completed tasks faster and reported conserving mental effort. In other words, Copilot did not merely show that a model could emit code. It showed that AI assistance could change the process of software development.
After autocomplete came intent
The next important signal came in 2022 and it did not come from an editor. DeepMind’s AlphaCode showed that harder programming problems often require something beyond elegant one-shot generation. AlphaCode generated many candidate programs, filtered them aggressively, and leaned on program behavior rather than surface fluency alone. In competitive programming, it reached roughly the level of the median competitor.
Historically, AlphaCode mattered because it previewed a principle that later coding agents would rely on constantly. Difficult software tasks are often search problems, not just language problems.
Later that same year, ChatGPT made conversational interaction with a model mainstream, and InstructGPT had already shown why that mattered. Models tuned to follow user intent are more useful than models that merely continue text.
In March 2023, GitHub Copilot X brought that shift directly into software development with chat, pull request assistance, documentation help, and GPT-4 integration. From that point on, the relationship between developer and machine changed. You no longer had to wait for the right completion to appear.
You could explain what you wanted, ask for a refactor, request tests, or ask the system to explain unfamiliar code.
Conversation wasn’t enough, the assistant had to see the repo

As soon as coding AI became conversational, a new bottleneck appeared: context. Chat is only as good as what it can retrieve about the project in front of it. GitHub’s repository indexing docs make the shift explicit.
Indexing runs in the background, and once an index exists, Copilot Chat can answer questions about the repository in GitHub and in VS Code. This was the moment coding AI stopped acting like a brilliant stranger and started acting more like a coworker who had at least read the codebase.
At the same time, open code models started adapting more directly to how programmers actually edit. SantaCoder emphasized fill-in-the-middle generation. StarCoder pushed the open-model frontier with broader language coverage and longer context. Code Llama emphasized infilling and larger input windows.
Those details mattered because real developers rarely write left to right from a blank page. They insert, patch, refactor, stub, and repair inside existing systems. The training objective was beginning to match the mechanics of software work.
An agent is a model that can act

This is where the modern meaning of “agent” starts to crystallize. A coding model becomes a coding agent when it can do more than generate plausible code. It has to inspect files, call tools, run commands, observe failures, and continue.
The ReAct paper gave the field a crisp conceptual template for interleaving reasoning and action, while OpenAI’s function calling made tool use practical as a product and API pattern. Together, they shifted the field from passive generation toward closed-loop interaction with an environment.
That idea quickly became concrete. The authors of the SWE-agent paper argued that language-model agents needed their own “agent-computer interface” for navigating repositories, editing files, and executing programs.
Devin packaged a shell, editor, and browser inside a sandboxed compute environment. OpenHands turned the same thesis into a more open and composable stack that can run locally, in the terminal, or in CI/CD workflows. In each case, the breakthrough was not just better code generation. It was the ability to take an action, inspect the result, and try again.
Benchmarks stopped asking for functions and started asking for work

The benchmarks tell the history in miniature. In 2021, HumanEval measured whether a model could synthesize a correct function from a docstring. By 2023, the authors of the SWE-bench paper asked whether a system could resolve real GitHub issues in real repositories. That shift is enormous.
The field stopped asking whether a model could produce code that looked competent and started asking whether a system could actually complete software tasks under real constraints.
Then the bar rose again. SWE-bench Verified introduced a human-validated subset for more reliable evaluation. LiveCodeBench focused on contamination-free evaluation and explicitly broadened the target to include self-repair, code execution, and test-output prediction.
Terminal-Bench moved closer still to reality by measuring performance on hard, realistic command-line tasks. Evaluation stopped rewarding code that merely looked plausible and started rewarding systems that could finish real work.
The background agent era
By 2025, the category had changed shape again. As of early 2026, GitHub documents two complementary agent experiences. In VS Code, you can describe what you want to build and let an agent plan, implement, and verify changes across the project. In GitHub itself, Copilot coding agent works in the background as part of the pull request workflow. You assign work, it makes changes, opens a pull request, and then asks for review. The assistant no longer had to wait at the cursor. The agent could take a task and come back with work product.
Other platforms converged on the same pattern. Recycling the term Codex, the OpenAI Codex product was reintroduced in 2025 as a software engineering agent for longer-running tasks, while Google’s Jules is explicitly framed as an experimental coding agent that integrates with GitHub, works autonomously, and can open pull requests with runnable code and test results inside secure cloud VMs. The cloud sandbox became the natural habitat of the background coding agent.
The terminal and the editor became control planes
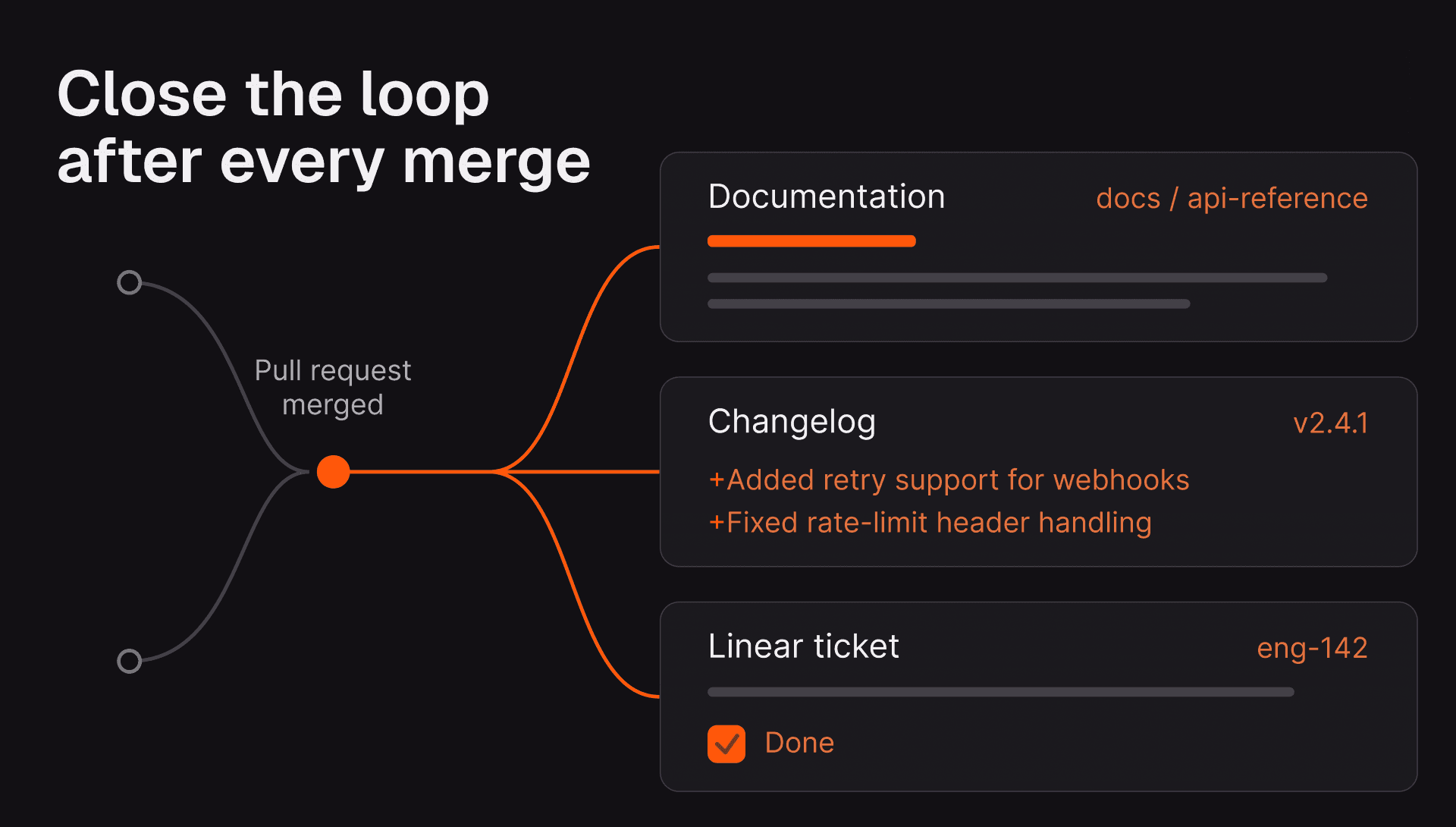
The local interface evolved in parallel. Claude Code is described by Anthropic as an agentic coding tool that reads your codebase, edits files, runs commands, and integrates with development tools. Its GitHub Actions workflow can respond to @claude mentions in issues and pull requests, and Claude Code now supports specialized subagents for task-specific workflows.
Codex CLI brings OpenAI’s coding agent into the terminal, GitHub Copilot CLI is now framed as a terminal-native agent with higher-autonomy modes, and Google’s Gemini CLI powers Gemini Code Assist agent mode. The terminal stopped being just a shell. It became an operating system for agents.
AI-native editors pushed the same logic further. Cursor describes itself as an AI editor and coding agent. Cursor Agent can complete complex tasks, run terminal commands, and edit code, while Cloud Agents run remotely and Automations can trigger agent work on schedules or events.
Windsurf’s Cascade combines planning, code edits, memories, workflows. The editor was no longer simply where humans wrote code. It became a coordination layer where humans supervise, redirect, and collaborate with agents.
Instructions and integrations became infrastructure

Once agents could act, organizations discovered a new problem. How do you make them act like your team? That is why instruction files and interoperability protocols became central.
Anthropic introduced MCP in late 2024 as an open standard for AI applications to connect to external tools and data sources. At the same time, repository instruction files like AGENTS.md gave coding agents a predictable place to find setup steps, testing commands, architectural guidance, and review expectations.
OpenAI’s docs say Codex reads AGENTS.md files before doing any work. Anthropic’s CLAUDE.md files and auto memory give Claude persistent project context. GitHub supports repository and organization custom instructions, and Cursor exposes persistent Rules. Prompt engineering had become something closer to infrastructure.
This matters historically because it marks another conceptual shift. In the early Copilot era, the prompt was mostly ephemeral: a comment, a function name, a cursor position. In the agent era, the durable instructions matter just as much as the transient request.
Teams now encode setup commands, testing rules, code style, escalation paths, and review standards in files that travel with the repository. That is a very different world from “predict the next line.” It is much closer to giving a new teammate an operating manual.
What the history actually shows
The cleanest way to describe this history is not as autocomplete getting smarter, but as the systematic decomposition of software engineering into machine-operable layers. First came code models. Then inline generation. Then conversation. Then codebase awareness. Then tool use. Then background execution. Then persistent memory. Then a layer of review and validation. Each breakthrough solved a bottleneck created by the one before it.
We began by teaching machines to predict code. We are ending, for the moment, by reorganizing software engineering around machines that can take goals, navigate systems, and produce working changes.
Interested in trying out AI code reviews? Get a free 14-day trial.