
CodeRabbitがClaude Marketplaceに登場!Learn more

Atsushi Nakatsugawa
April 27, 2026
2 min read
Agentic SDLC: How AI agents are changing SDLCの意訳です。
ここ10年ほどのあいだ、開発ワークフローにAIを取り入れるということは、開発者に「より賢い自動補完」を渡すことを意味してきました。コードを書くのは依然として人間で、判断するのも変わらず人間でした。レビューも、人間が差分を読んでコメントを残すことを前提に組まれていましたし、AIは個々の作業を速くしたものの、ソフトウェアが作られる根本的な形までは変えていなかったのです。
その「形」がいま変わりつつあります。エンジニアリングチームは、一連のワークフローを自律的にやり切るコーディングエージェントを実戦投入しはじめており、ソフトウェア開発ライフサイクルはエージェントを中心に再編されつつあります。ツール、プロセス、そして多くの場合は私たちの頭の中の整理(メンタルモデル)が、まだその変化に追いついていないのが現状です。この変化がどう起きてきたのか、地に足のついた解説を読みたい方は、Copilotから次世代エージェントまで ― AIコーディングの歴史を振り返るから始めるのがおすすめです。
本記事では、エージェント型SDLCとは具体的に何なのか、AI支援開発と何が違うのか、そこでどんな新しい問題が生まれるのか、そしてこれから先、うまく設計されたエージェント型スタックとはどんな姿になるのかを、実務的な視点で見ていきます。
この区別は、見た目以上に重要です。AI支援開発とは、開発者が自分の主導する作業を、AIを使ってより速く進めることです。たとえば、関数の生成やエラーの説明、リファクタリングを提案させる、といった使い方です。意味のある判断のポイントでは、開発者は常にループの中に残っています。
エージェント型開発はそうではありません。AIがゴールを与えられ、人間がいちいち指示しなくても、複数のステップにまたがってそのゴールを追いかけます。計画を立てて実行し、自分の出力を評価して必要ならループを回し、最後に完成した成果物を引き渡します。開発者は意図を設定し、結果をレビューします。けれども、その間のワークフローは自律的に走ります。
エージェント型SDLCを実務的に定義するなら、こうなります。AIエージェントが、自動補完やPRレビューのような単一のチェックポイントに居座るのではなく、計画、コーディング、レビュー、リリース、運用といったライフサイクル全体にわたって、意味のある形で関わるソフトウェア開発のやり方です。チームが単機能のツールを行ったり来たりするのではなく、エージェントが横に並走し、ステージ間でコンテキストを運び、チームの代わりに動き、学習を蓄え、自分が行ったことに対して説明責任を持ち続けます。

エージェント型SDLCが本当に機能するには、4つの条件が同時に揃っている必要があります。
コンテキスト。 エージェントには、組織の動きを示す全体像が必要です。1つのリポジトリだけでなく、コード、チケット、ドキュメント、モニタリング、クラウドの情報まで含めてです。1つのリポジトリの中だけで考えるエージェントは、ストーリーの残りの部分を見落とします。Slackに残っているインシデントのスレッド、なぜコードがそういう構造になっているかを説明するチケット、許容されるふるまいを定義した運用手順書などです。
ナレッジ。 タスク開始時のコンテキストだけでは足りません。エージェントには、チームが実際にどう仕事を進めているかを示す「生きた記憶」が必要です。時間をかけて積み上がってきたパターン、慣習、判断の蓄積です。これがあれば、毎回ゼロから始めなくて済みます。
マルチプレイヤーでの協働。 ソフトウェアは1人で作るものではありません。エージェント型ワークフローも、孤立したターミナルセッションの中で動くのではなく、チームが普段使っているチャンネルやスレッドの中で進んでいく必要があります。そうでなければ、チーム全体に状況が共有されません。
ガバナンス。 スコープを区切ったアクセス権、誰が(何が)実行したかが追跡できる仕組み、設定と監査が可能なガードレール。特にエンタープライズのチームには、エージェントがアクセスできるリポジトリ、呼び出せるツール、コストの発生先について制御できることが求められます。
この4つが揃っていなければ、それは本当の意味でのエージェント型SDLCとは言えません。「ステップが増えただけの、もう少し速い自動補完」にすぎません。

これらは、Claude Code、Cursor、Codex、Gemini、そして増え続けるその他のツールを使って、いまこの瞬間にも本番環境のエンジニアリングチームで動いています。その出力はそのままコードベースに着地し、本番環境に向かって流れていきます。
従来のSDLCには、はっきり定義された段階があります。計画、開発、レビュー、マージ、デプロイです。エージェント型SDLCは、これらの段階を置き換えるわけではありません。しかし、各段階で誰(あるいは何)が作業をしているのかは確実に変えます。さらに重要なのは、本当のボトルネックやリスクの集中点が、どこに移ったのかを変えてしまうという点です。
計画(プランニング)は、品質が「文書化される段階」ではなく、「決まってしまう段階」になりつつあります。エージェントが実装を担うとき、チケットの意図が曖昧だと、単に開発者の手が遅れるだけでは済みません。技術的には正しくても、機能的には間違っているPRが生まれてしまい、そのやり直しに大きなコストを支払います。そのため、コーディングエージェントを使うチームは、計画段階により多くの投資をするようになっています。曖昧な要件に対してAIを使い、コードを書き始める前にコンテキストに根ざした正確な仕様へと変換しているのです。CodeRabbitのIssue Plannerは、まさにこの段階のために設計されています。
開発は、エージェント型のシステムが最も進んでおり、最も速く動いている領域です。コーディングエージェントは、機能開発のワークフローを一通り完了させ、自律的なデバッグループを回し、これまでシニアエンジニアがまとまった時間を割いていたリファクタリングを引き受けています。スピードの向上は本物で、定量的にも確認できます。
レビューは、ギャップが存在している段階です。意図と出力がぶつかる場所、基準が強制されるべき場所、そしてセキュリティ上の問題が本番に出ていく前に捕まえられるべき場所です。それにもかかわらず、エージェント型開発の影響を最も直接的に受けているはずなのに、最も変化していない段階でもあります。
マージとデプロイは、いまのところ依然として人間のゲートが効いています。ただし、レビュー層が成熟しているチームは、その層に対する信頼が高まるにつれて、この段階の自動化を進めはじめています。
エージェント型開発でチームが本当に直面している課題は、スピードではありません。「信頼できるかどうか」です。エージェントは、チームが検証できるよりも速くコードを生成します。しかも、エージェントの出力は不透明で、人間が書いたコードよりも検証が難しいのです。私たちが以前詳しく書いたとおり、AIコーディングエージェントの本当のコストは、トークンや計算資源ではなく、ワークフローのあらゆる段階で静かに積み上がっていく「ズレ(misalignment)」です。
人間がPRを書いた場合、レビュアーは本人に質問でき、思考の道筋をたどれ、特定の選択の意図を理解できます。エージェントが40ファイルにまたがるデバッグワークフローを回し、15回イテレーションを繰り返し、200行のコードに触れたPRでは、何がどう変わったのか、そしてなぜそうしたのかを再構築するのは、差分を読むという作業ではなく、能動的な調査作業に近くなります。PRの表面は、ほかのPRと何も変わりません。しかし、その下にあるものは、はるかに把握が難しいのです。
ここから、チームが現場で対処している、いくつかの具体的な問題が出てきます。
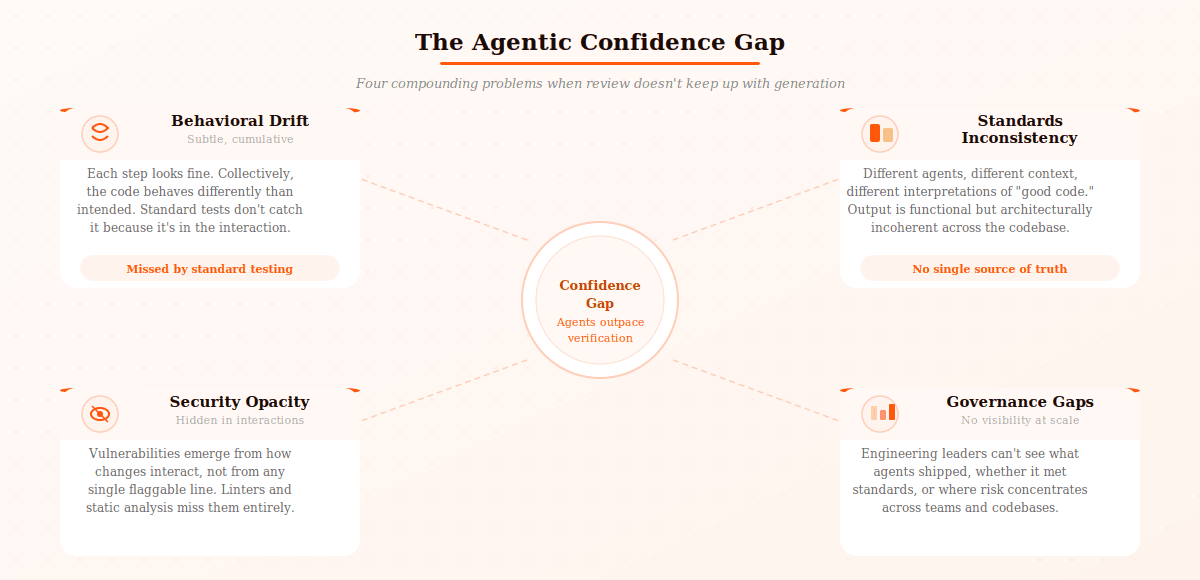
ふるまいのドリフト: 各ステップで見れば妥当な判断なのに、それらが積み重なった結果、コード全体のふるまいに微妙な変化が生まれ、標準的なテストや表面的なレビューでは捕まえられない場合。
不揃いな基準: 別々のエージェントが、別々のタイミングで、別々のコンテキストのもとに動くと、「このコードベースにとっての良いコード」の解釈もバラバラになり、技術的には動くものの、アーキテクチャ的には統一感のない出力が生まれる場合。
セキュリティの不透明さ: エージェントの出力が引き起こす脆弱性が、標準的なLinterや静的解析では見えてこない場合。問題は、ある特定の1行ではなく、複数の変更の組み合わせから立ち上がってくるからです。
ガバナンスのギャップ: エンジニアリングのリーダーが「エージェントが何をリリースしたのか」「チームの基準を満たしているのか」「並行で動く多数のエージェントの中でリスクがどこに集中しているのか」を、信頼できる形で把握する手段を持っていない場合。
これをうまく乗りこなしているチームの共通点は、レビューを「エージェント型ワークフローの最後に取り付ける、レガシーな人間の作業」とは見なしていない点です。エージェントが生み出すスピードと複雑さに見合った形で機能する、スタックの中の能動的なレイヤーとして扱っているのです。
従来の自動レビューツールは、別の問題を解くために設計されていました。Linterや静的解析、基本的なCIチェックは、「人間のレビュアーが見落とすかもしれないもの」を拾うために作られたものです。つまり、既知のパターン、構文エラー、フォーマットのルールに最適化されているということです。役には立ちますが、エージェントが複数ファイルにまたがる複雑な変更で何をしようとしていたのか、当初の意図からズレていないか、コードベースの他の場所で似た問題をどう扱っているかと整合しているか、といったことを推論するためには作られていません。
エージェントの出力に対して効果的に働くレビュー層は、従来のツールにはできなかったことをいくつか実現する必要があります。
まず、コードベースのコンテキストを、十分な深さで理解する必要があります。一般的なベストプラクティスではなく、そのコードベース固有のパターンと基準に照らして、変更を評価できる深さです。そのためには、ファイル同士の関係、コードの依存関係、過去のPR、関連するイシューを分析して、差分にラベルを貼るだけでなく、意図を再構築できなければなりません。
次に、コードがどこから来たかに関係なく、一貫した基準を適用できる必要があります。シニアエンジニアのPRにも、ジュニアのPRにも、リファクタリングのワークフローを5回目に回したエージェントの出力にも、同じ基準が適用されることが大事です。
それから、生成のスピードに追従できる必要があります。人間の集中力のペースではなく、です。レビュー層が行列を作ってしまうのなら、それはボトルネックを解消したのではなく、移動させただけだからです。
そして、指摘を行動に移せるくらい具体的に説明できる必要があります。エージェントが生成したPRに対して「ここをリファクタリングしてはどうでしょう」というコメントは、ほとんど役に立ちません。開発者は、その出力を受け入れるのか、退けるのか、修正するのかを判断しなければならないからです。
CodeRabbitは、まさにこのために作られています。コンテキストエンジニアリングのアプローチで、複数リポジトリの情報、過去のPR、関連Issueを取り込み、コードベースから切り離すのではなく、その実態と照らし合わせて変更をレビューします。Code Guidelinesを使えば、コーディングエージェントに設定したのと同じ基準をレビュー層にも設定できるため、生成とレビューの間でルールが揺れません。さらに、エージェント型のコード検証として、PRごとにサンドボックス環境で検証エージェントを走らせ、手動で炙り出すには手間がかかり、ミスも起きやすい類の問題をキャッチします。
ここに「唯一の正解」はありません。チームによって導入の段階も、許容できるリスクのレベルも違うからです。それでも、エージェントを本格的に運用しているチームのあいだに見られる共通パターンは、おおよそ次のような形になります。
エージェントは、スコープが明確で、仕様もきちんと書かれたワークフローに使われること。意図を十分な精度で表現できれば、出力も予測しやすくなります。曖昧なチケットからは、どれだけ優秀なエージェントを使っても、曖昧なPRしか出てきません。
計画段階への投資が、純粋に人間中心のワークフローのときよりも増えていること。エージェントが15回イテレーションを回したあとで誰かがようやく結果を見る、という流れでは、意図の曖昧さが生むコストが格段に高くなるからです。
レビューが、レガシーな工程ではなくスタックの能動的なレイヤーとして扱われていること。自動レビューが生成のスピードで動き、人間によるレビューは、パターンマッチングではなく本当に人間の判断が必要な意思決定にだけ温存されます。
基準とガイドラインは一度定義し、どこにも同じものを適用すること。コーディングエージェントの設定、レビュー層、CIパイプラインの3つにです。そうすれば、ツールを切り替えるたびに「このコードベースで良いコードとは何か」を説明し直さずに済みます。
ガバナンスのためのツールが、エンジニアリングリーダーに必要な可視性を提供していること。エージェントが何をリリースしているのか、リスクはどこに集中しているのか、チームやコードベース横断で基準が一貫して適用されているかを、リーダーが把握できる状態を保ちます。
エージェント型スタックの「生成」側は、速く動いていて、これからも速く動き続けます。エージェントはより有能になり、自律的にこなせるワークフローの幅も広がっており、それを導入したチームには実際にスピードのメリットが積み上がっています。けれども、2025年は「AIスピード」の年、2026年は「AI品質」の年になるでしょうで論じたとおり、純粋なスピードは物語の半分にすぎません。
仕事として残っているのは、レビューとガバナンス側です。レビューが開発より本質的に重要だから、ではありません。エージェントが生成できる量と、チームが自信を持って検証できる量との差こそが、そのスピードのうちどれだけが「信頼できる、本番投入可能なソフトウェア」に化けるかを決める、本当の制約になっているからです。
ここを正しく押さえているチームこそが、レビューを「人間のペースに合わせた開発フローから引き継いだ、後付けの作業」ではなく、エージェント型スタックにおける一級のエンジニアリング課題として扱っているチームと言えるのです。


