Before, during, after: The three moments AI Agents earn your trustの意訳です。
私たちは、AIの能力を疑う時代をすでに通り過ぎました。今、ボトルネックになっているのは信頼です。
説明可能性を扱った前回の記事では、可観測性と説明可能性を明確に分けました。エージェントが何をしたのかと、なぜそれをしたのかの違いです。その中では、人間が説明可能性を必要とする仕事は、検証とデバッグ、そして監査可能性という3つに分かれることを示しました。
では、その説明は開発者の日々のワークフローのどこに置かれるべきなのでしょうか。エージェントが完全に作業を終えるまで待ってから要約を見せるなら、その時点でもうユーザーを失っています。この3つの重要な仕事を支えるには、説明可能性をプロダクトのワークフローに直接組み込む必要があります。その瞬間がどこにあるのかを具体的に見ていきましょう。
3つの未来、1つの共通点
ワークフロー上の配置がなぜ重要なのかを理解するには、AI業界全体がどこへ向かっているのかを見る必要があります。Anthropicは最近、AI開発シナリオの分析を公開し、3つの異なる道筋を示しました。
- 1つ目のシナリオ:進歩は停滞しますが、現時点で強力なモデルが経済全体に広がります。
- 2つ目のシナリオ:AIラボは効率改善を積み重ね続け、人間は引き続き方向性を定め、結果を判断します。
- 3つ目のシナリオ:AIシステムが再帰的に自己改善を始め、人間は「自分たちの労力の大半を監督、妥当性確認、検証へ移す」ようになります。
より可能性が高い2つ目と3つ目のシナリオで、人間の役割に何が起きるかに注目してください。人間は作業を行う側ではなくなり、それを検証する側になります。Anthropicによれば、これはすでに彼らの社内で起きています。同社のコードベースにマージされるコードの80%以上が、今ではClaudeによって書かれているからです。そしてコード生成が加速するにつれて、人間によるレビューがボトルネックになりました。同社はAmdahlの法則を引き合いに出しています。プロセスの一部を高速化しても、全体の速度は高速化されなかった部分によって上限が決まる、という考え方です。
これが3つの未来すべてをつなぐ共通点です。どの未来に進んだとしても、希少になる人間の活動はコードを書くことではなく、それを信頼してよいかを判断することです。
結果を信頼することの限界
この1年、AIエージェントに関する業界の中心的な問いは、純粋に能力についてのものでした。私たちは「エージェントはXをできるのか」と問い続けてきました。{X: バグを修正する | サービスをリファクタリングする | 実験を走らせる | など}。業界ベンチマークと現場での利用データの両方から、私たちはすでに答えを得ています。エージェントによるアウトプットの圧倒的な速度を見てみましょう。
- コミットの変動性: GitHubは2025年通年でおよそ10億コミットを処理しました。2026年半ばには、週あたり2億7500万コミットをトラッキングしています(参考)。これは、今年の業界全体が140億コミットのペースにあることを意味します。エージェントは今、非常に速い速度でコードをコミットしています。
- ネットワークトラフィック: Cloudflareは、自律型AIエージェントが生成した週次リクエストが、同社ネットワーク全体で1か月のうちに2倍以上になったと報告しました(参考)。
- タスクの到達時間: METRの計測によれば、エージェントが信頼性を保って動作できる時間の長さは、およそ4か月ごとに倍増しています。2年前には最長4分のタスクが限界だったエージェントが、今では12時間にわたって無人で動作できます(参考)。
こうした定着率の高い導入カーブを支えているのは、結果に対する根本的な信頼です。開発者は、エージェントが十分な数のチケットをクローズし、十分な数の不安定なテストを直し、十分な数の動作するPRを作るところを見てきました。そのため、能力はもはや論点ですらありません。
しかし、「結果を信頼すること」には有効期限があります。
エージェントがより長いタスクを引き受け、影響範囲が桁違いに大きくなるにつれて、「エージェントはたいてい正しい」という範囲から外れるエッジケースの量が増え始めます。あなたのプロダクトがこの段階に達しているなら、まずはおめでとうございますとお伝えします。ただし、その次には覚悟が必要です。エージェントによるアウトプットの量が、人間による行単位レビューを数学的に不可能にする水準に達したからです。
これが究極の締め付けです。人間が検証しきれないほど多くのコードが生成される一方で、失敗したときの影響はかつてなく大きくなっています。このAIファーストの世界を進む唯一の方法は、説明可能性を低コストで扱えるAIツールを作ることです。
つまり、すべてのAIツールは、いずれ説明可能性ツールになる道を避けられません。

もちろん、ここにはわかりやすいオチがあります。誰が説明を担当するのか、という話です。AIツールを説明するAIツールが、さらに別のAIツールを説明し、それがどこまでも続く。しかし、その再帰はいつもの場所、つまり人間で終わります。説明可能性についての最初の記事で示した説明可能性スタックの要点は、監視者を無限に増やすことではありません。その連鎖のどこに人間が座っていても、その人に届く「なぜ」が行動につながるものになっていることを保証することです。
基盤モデル間で重みの差はコモディティ化しつつあります。だから次のフェーズで勝つプロダクトは、モデルがわずかに優れているものではありません。連鎖の最後にいる人間を、速く、正確に、そして少しだけつらくない状態 ;-) にできるものです。
説明可能性のワークフロー
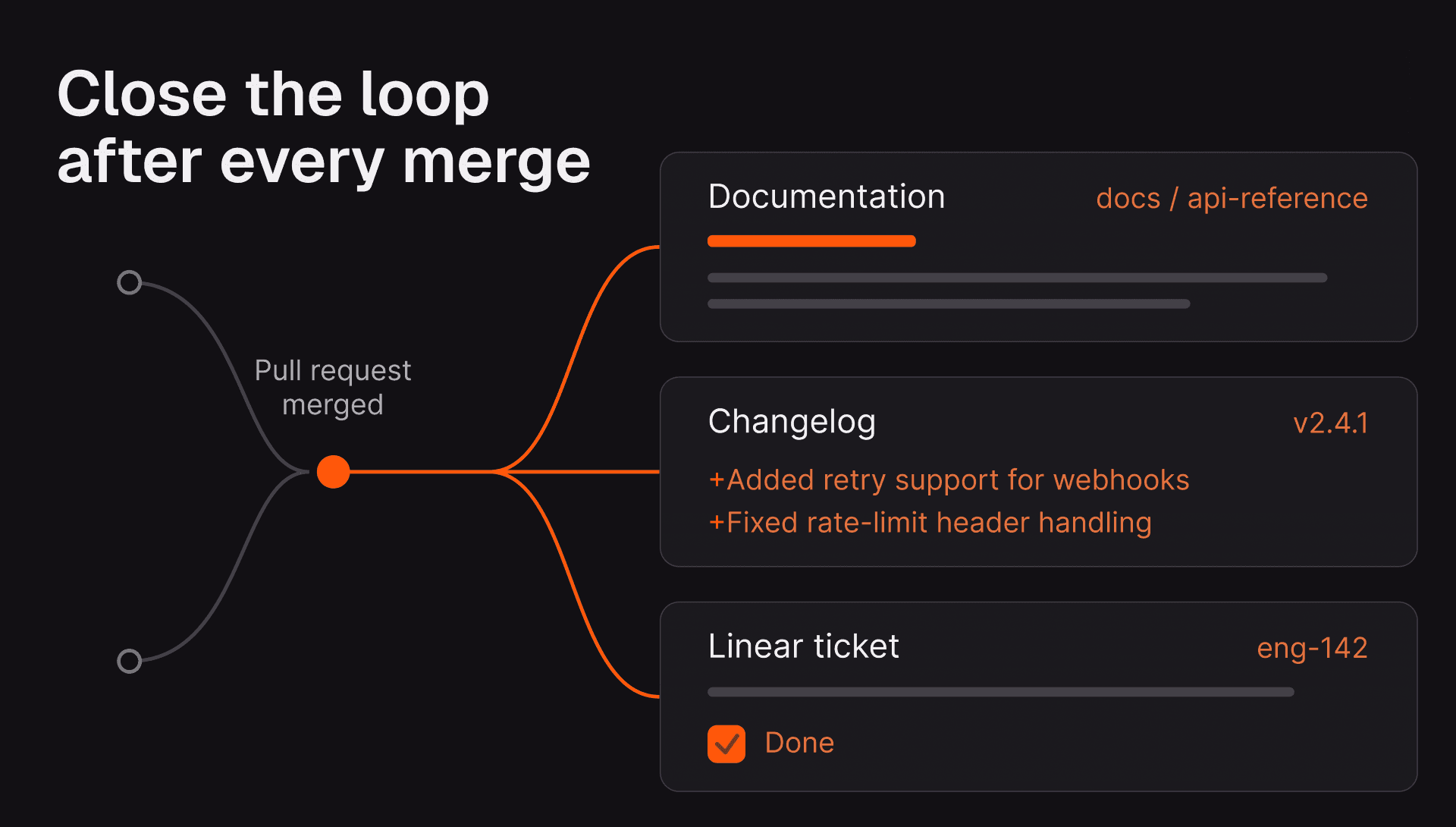
多くのチームは、説明可能性を事後的な成果物として扱っています。エージェントが完了し、その後に要約を生成する、という形です。しかし、それは仕事の3分の1にすぎません。本当の説明可能性は3つの異なる瞬間で発生し、それぞれに異なる種類の「なぜ」が必要です。
1. 作業前:考え方を見せてほしい

誤った判断を見つけるうえで最もコストが低い場所は、作業が始まる前です。エージェントが1つのファイルに触れる前に、次のことを答えられるべきです。あなたの依頼をこう理解した、このような手順に分解した、そして他の選択肢ではなくこの方法を選ぶ理由はこうだ、という説明です。
これは推論と計画のレイヤーであり、意図の不一致が表面化する場所です。たとえば、エージェントに「不安定なcheckoutテストを直して」と依頼したとします。有効な計画の1つは、その不安定さを引き起こしている競合状態を見つけて修正することです。別の計画は、リトライ用のラッパーを追加することです。3つ目は、そのテストを丸ごと削除することです。3つとも技術的には問題を「修正」しますが、あなたの意図に合っているのはそのうち1つだけです。計画があれば、こうしたズレを早い段階で見つけられます。エージェントがトークンや午後の数時間を消費し、後始末のデバッグに突入する前に、方向修正できるのです。
この段階でプロダクトが答えなければならない問い: エージェントは私の意図を理解しているか。そしてタスクの分解は、その意図に沿っているか。
2. 作業中:探索の過程を見せてほしい

エージェントは、プロンプトからPRまで一直線に進むわけではありません。分岐し、行き止まりにぶつかり、引き返し、再調整します。その探索は最終的なdiffには現れませんが、ユーザーが信頼を築くためには欠かせません。
ここで必要なのは、生のツールログではありません。説明可能性についての最初の記事では、「ログを見せる」ことが誰にとってもうまくいかない理由を扱いました。必要なのは意思決定の軌跡です。エージェントがどの道筋を探索し、どれが何も生まないとわかり、そして重要なこととして、どの具体的な情報を見てから分岐先を決めたのか、ということです。
たとえば、「キャッシュによる対応を検討したが、認証済みリクエストではキャッシュレイヤーがバイパスされることがわかったため、クエリの修正に切り替えた」という説明があれば、レビュアーは5秒で判断の妥当性を確認できます。同じ情報が400行の生のツール呼び出しに散らばっていたら、AIプロダクトが「説明可能性に対応している」としても、実用上は隠れているのと同じです。
この段階でプロダクトが答えなければならない問い: エージェントは正しい思考の流れをたどっているか。適切な道筋を選び、有効な入力を与え、返ってきたものを正しく解釈してから次に進んでいるか。
3. 作業後:影響を見せてほしい
ワークフローのこの部分は、最も頻繁に見落とされるにもかかわらず、最も重要です。エージェントは、自分の作業がもたらす全体的な結果を説明するまで、その作業を説明したことにはなりません。特に、目の前のdiffには見えていない結果も含めてです。コード変更の要約は、単なるPR説明文です。影響範囲全体を丁寧に示してはじめて、本当の説明になります。よくあるプロダクト上の誤りは、前者を作っておきながら、それを後者だと思い込むことです。
例を考えてみましょう。エージェントが1行変更のPRを作ります。コードベース全体で表記を統一するために、enum値をcancelledからcanceledへリネームする変更です。diffはきれいです。型チェッカーも問題なしです。リポジトリ内のすべてのテストも通ります。エージェントがそれらも丁寧に更新したからです。PRで確認できるあらゆるシグナルから見ると、これは想像できる限り最も安全な変更です。単純なタイプミス修正です。
しかし、その値はこのリポジトリの中だけに存在しているわけではありません。キュー上のイベントへシリアライズされており、2ホップ先の課金サービスがcancelledという文字列にマッチしてサブスクリプションの請求を止めています。エラーは出ません。アラートも鳴りません。課金サービスはキャンセルを静かに認識できなくなり、キャンセルした顧客への請求が続くだけです。
diffだけを見るレビュアーは、スペル修正を検証しています。影響範囲全体、つまりこの値はサービス境界を越えており、これを利用しているのは誰かを示されたレビュアーは、本来の判断を検証しています。
これは一度きりのエッジケースではありません。今日のコードレビューにおける大きな欠落です。コードレビューは常に目の前にあるものを起点にしてきましたが、変更の結果はdiffの境界を尊重してくれるとは限りません。だからこそ、この段階の説明可能性には高い基準が必要だと私たちは考えています。単に「何が変わったか」ではなく、その変更によってシステムの振る舞いがどう変わるのかを、徹底的に理解できることが必要です。
この段階でプロダクトが答えなければならない問い: この変更は何をするのか。見えていない部分も含めて、漏れなく説明できるか。
説明可能性はプロダクトである
ワークフローにおける3つの段階から一歩引いて、それらに共通するものを見てみましょう。
- 作業前、エージェントは意図を説明します
- 作業中、エージェントは判断を説明します
- 作業後、エージェントは結果を説明します

これらはロードマップ上でチェックを付ける3つの機能ではありません。1つの義務が、人間がエージェントの作業について判断しなければならない3つの地点に適用されているだけです。そのまま進めさせるのか、それとも制御を取り戻して別の方向へ動かすのかを決める地点です。
これこそが、業界が収束しつつある監督役の本当の形です。エージェントを監督する人間は、すべての行を読んでいるわけではありません。誰かが直接確認できる量を超えたアウトプットに対して、先ほどの3つの問いに何度も答えているのです。したがって、監督の質は、その人に届く説明の質によって制約されます。
業界自身の予測が正しく、人間の役割が監督と妥当性確認へ収束していくのなら、説明可能性はAIツールの上に重ねる「あれば便利」なものではありません。それがプロダクトです。
CodeRabbitでは、この前提に基づいて開発しています。私たちがリリースするすべてのものにおいて、設計上の問いは同じです。この作業を検証する人間は何を知る必要があり、それをどの瞬間に知る必要があるのか、という問いなのです。