

Atsushi Nakatsugawa
November 26, 2025
3 min read
Gemini 3 for code-related tasks: The dense engineerの意訳です。
TL;DR: Gemini 3 はパッチを書く以上の仕事をします。変更の一つひとつに対し、完全な論証を構築します。正しいときは驚くほど正確で、間違っているときでさえ「正しそうに見える」レビューを生成します。

CodeRabbit のモデルはすべて、短い見出し・説明・パッチという同じ構造的な枠組みに従っています。しかし Gemini 3 はその枠組みの使い方が異なります。レビューの隅々まで、前提条件、根拠、因果関係で埋め尽くします。それぞれのレビューは、技術ブリーフ(設計資料)を diff で包んだような構造になっています。
Gemini 3 は自信に満ち、詳細で、徹底的に具体的です。コメントは「なぜその修正が必要なのか」を示す証拠とともに、シニアエンジニアが書いたかのような明確さを持っています。この「密度」こそが Gemini 3 の特徴であり、たとえ最終的に採用しない指摘でさえ、重要な示唆に満ちています。

CodeRabbit 標準ベンチマークを使って Gemini 3 を評価しました。これは C++/Java/Python/TypeScript にまたがる 25 のプルリクエストに、既知のエラーパターン(EP)を埋め込んだものです。すべてのコメントは複数の LLM ジャッジが採点し、さらにエンジニアが手動で検証しました。評価指標は精度(precision)、重要度割合(important-share)、シグナルノイズ比(S/N比)で、CodeRabbit のモデル比較に毎回使用しているものと同じです。
またモデルの 書き方 が提案の採用率に影響するため、口調・長さ・スタイルも評価しました。
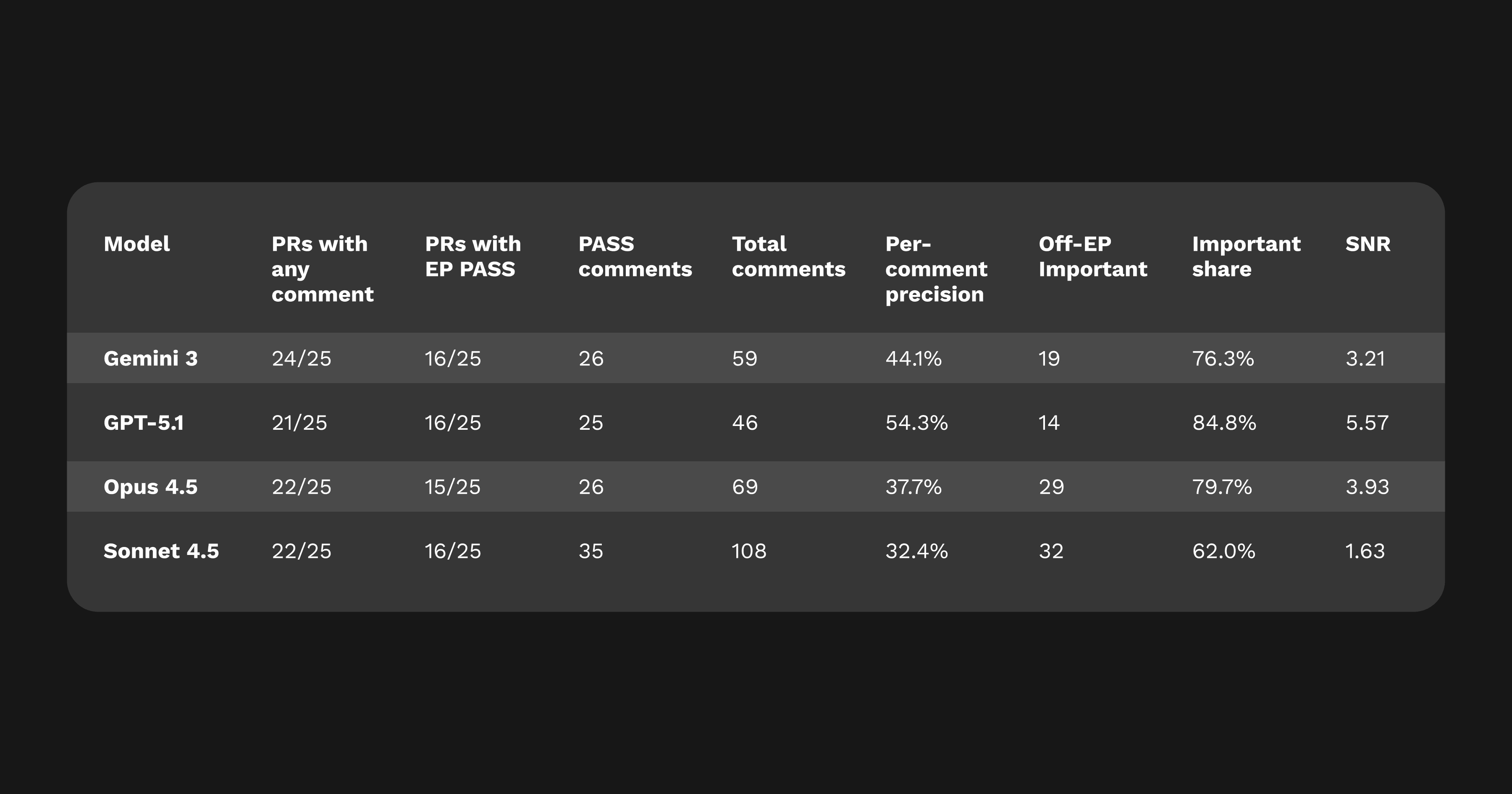
解釈: Gemini 3 は精度において中間層に位置しますが、本物のバグのカバレッジが非常に優れています。コメントの約 4 件中 3 件が重要(Critical/Major)に分類されました。S/N比 は 3.2 と信頼性では Opus 4.5 に近いですが、Gemini 3 の方がより強い確信と詳細さを持って表現します。
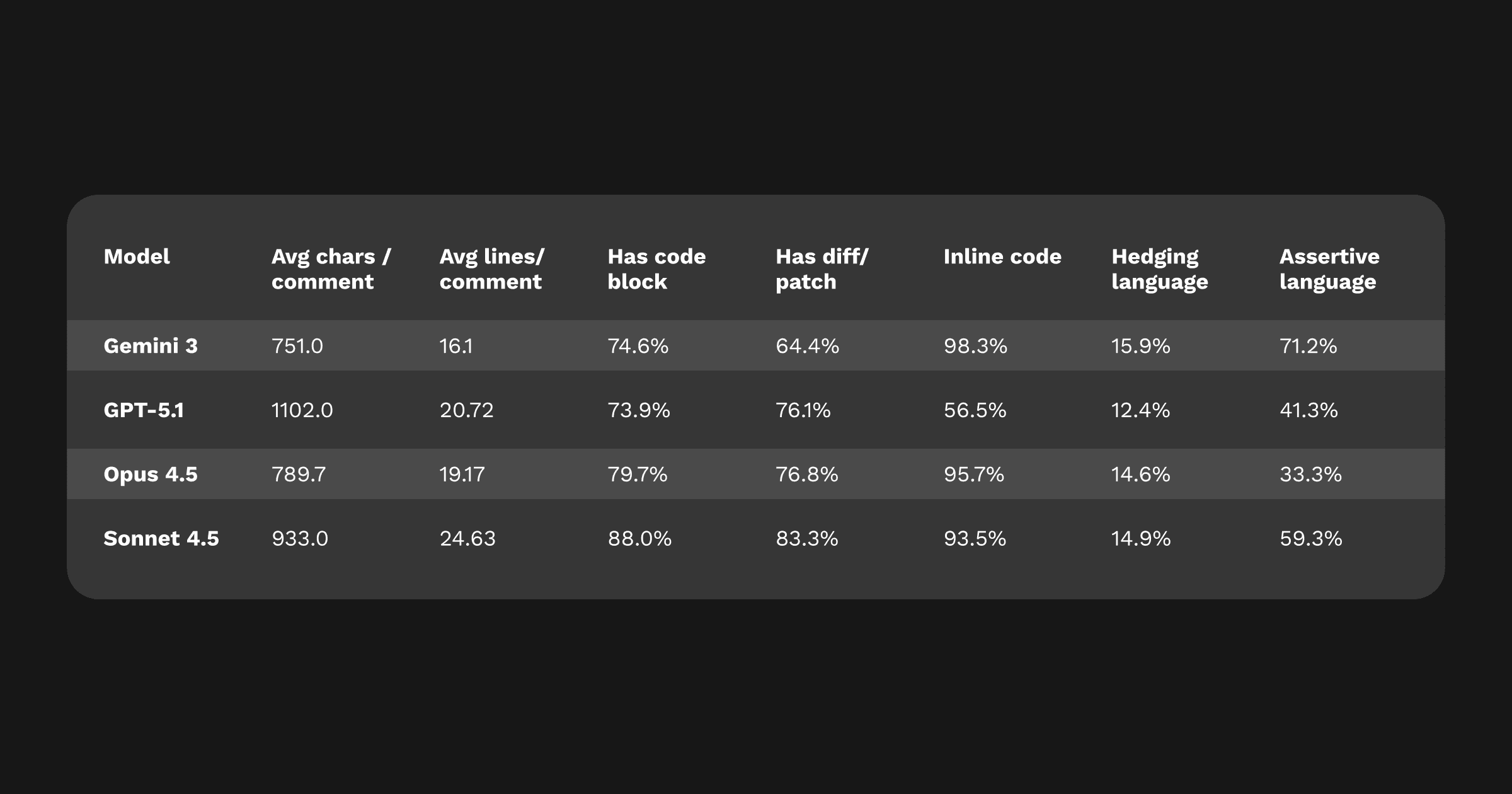
トーンの概要: Gemini 3 は4つのモデルの中で最も断定的です。自信をもって語り、その多くは正当化されています。仮に間違っていても、コメントが十分に説得力を持つため、開発者がコードをもう一度確認したくなることが特徴です。これは実用的価値を高めますが、人によっては混乱を招く可能性もあります。

Gemini 3 は、驚くほど多くの推論をコンパクトなコメントに圧縮します。平均コメントは 16 行ですが、その中に「何が壊れたのか」「なぜ壊れたのか」「どう修正するのか」という因果関係がすべて詰まっています。
例:
C++ のワーカープールでの並行性バグを検出した際、Gemini 3 は単に「ロックが抜けている」とは言いません。アンロック → ウェイト → シグナル喪失 → スレッド停止、という一連の流れを再構成します。そして 1 行のパッチで競合状態を修正します。
また TypeScript のレビューでは、MAX_SAFE_INTEGER がキャッシュの自動削除を無効化している問題を突き止め、パフォーマンス上のリスクを説明し、LRU フォールバック案を提示します。
これはスタイルの問題ではなく、プログラムの信頼性を改善する実質的な修正です。
Gemini 3 の密度と正確さが、明確な「人格」を形成しています。
すべてのコメントが論証であり、その多くは厳密な検討に耐えます。

Gemini 3 のレビューは他のモデルとはまったく異なります。自信があり、構造化されていますが、特に推論が密です。各コメントは、変更を承認する前にコンテキストを求めるリードエンジニアのレビューのようです。
多くのコメントは「この競合状態を修正してください」のような指示から始まり、ファイル参照を交えた説明に続き、最後にパッチを提示します。まるで専門家が問題と解決策を同時に案内してくれるような感覚です。
開発者は Gemini 3 について「確信に満ちたレビューで、主張を証拠で裏付ける」と評価しています。その直接的なトーンは強く感じるかもしれませんが、コメントはミニ設計レビューのように、変更点・重要性・トレードオフを説明してくれます。
情報密度が高いため、注意深く読む必要がありますが、それに見合う洞察が得られます。誤りがあっても、隠れたエッジケースや設計上の前提を浮き彫りにすることがよくあります。
1. 密度は正確性と相関する。
長めのコメント(上位50%)は、短いコメントに比べ精度が高く、53% の精度を達成。
重要コメント(Critical/Major)は 平均 847 文字 で、重要でないコメント(442文字)の 2 倍近い長さ。
Gemini 3 が丁寧に書くとき、それはたいてい正確です。
2. トーンは重大度を反映する。
断定的な文体は重大度に比例:
Major の 92%
Critical の 67%
が断定的。
一方 Minor では断定的なメッセージが 36% に減り、hedging(曖昧表現)は 36% に増加。
3. 自信は品質と相関する。
断定的なコメントは 47.6% の精度で、
ニュートラル(36%)、曖昧さ(33%)より高い。
Gemini 3 の自信は全体的に、根拠に裏打ちされています。
4. パッチの有無は信頼性の指標。
diff やコードブロックが登場する場合、精度が向上。
断定的なコメントの 70% 以上 が diff を含み、
曖昧なコメントでは 17% に留まる。
パッチの存在は、モデルが実際のコードに基づいて推論しているサインです。

Gemini 3 が最も得意とする領域は 並行性 と システム正確性 です。
他モデルが見落とすインターリーブや同期問題を頻繁に検出します。
そしてバグの なぜ を正確に説明します。
スレッドセーフティ:
Lost Wake Upやロックの不整合を物語のように説明し、簡潔なパッチを提示。
ライフサイクル管理:
シャットダウンフックの欠如や未クローズのリソースを検出し、明示的なクリーンアップを推奨。
アルゴリズムの安定性:
コンパレータのロジックや off-by-one バグを修正。
システム設定:
デフォルト値が期待する動作を妨げている場合に実用的な上限を提案。
これらは、Gemini 3 の詳細な推論が直接的で検証可能な修正につながっている例です。
Gemini 3 の確信は、時にやりすぎることがあります。
スタイルや軽微な問題に対して、重要度を過大評価することがあります。
“Critical” とラベルされたコメントの中に、実際には軽微な指摘が含まれる場合もあります。
その断定的なトーンは、些細な問題を深刻に見せることもあります。
とはいえ、こうした行き過ぎた指摘も、実際の非効率や可読性問題に触れていることが多く、無価値なコメントはほとんどありません。
Gemini 3 は簡潔さより理解を優先します。
修正だけでなく、小さな調査レポートを提供します。
この深さは、大規模で複雑なシステムにおいて非常に価値があります。
Precision は「当たったかどうか」を測る指標ですが、
Density は「そのコメントを読むことでどれだけ学べるか」を測ります。
本番環境において、この違いは重大です。
GPT-5.1 のような簡潔なモデルは迅速な指摘に優れますが、
Gemini 3 は包括的な推論で開発者の理解を深め、
見落とされがちな微細な欠陥の発見を助けます。
言い換えれば、
“Gemini 3 は読み飛ばすものではない。読み込むものだ。”
| 使うべき場面 | 理由 |
| 並行性やリソース管理が重要なコード | 同期やライフサイクル問題の検出に強い |
| 深さが必要で、短さが不要 | 長いコメントの方が正確な傾向 |
| 実用的なパッチが必要 | 約65%のコメントに適用可能な diff が含まれる |
| 強めのトーンを扱える | 自信が助けになる場合が多い |
| 若手エンジニアの育成 | コメントがそのまま教育コンテンツになる |
Gemini 3 は表面的なレビューには向いていません。
精度、説明、洞察が重要なときに真価を発揮します。
Gemini 3 は、コードを修正するだけではありません。
修正のために 論理的なケース(主張) を提示します。
各コメントが、原因・影響・解決の完全なストーリーになっています。
正しいときは、シニアエンジニアの深い分析を読んでいるような感覚です。
間違っているときでさえ、問題の考え方に関する洞察が得られます。
まとめ:
GPT-5.1 が「決断力のあるチームメイト」
Opus 4.5 が「規律あるアーキテクト」だとすれば、
Gemini 3 は「密度の高いエンジニア」。
自信と包括性を併せ持ち、論証に基づく diff を提供します。
CodeRabbit を試してみませんか?
14日間の無料トライアルはこちら


