

Brandon Gubitosa
June 26, 2026
8 min read
June 26, 2026
8 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
We got one big thing wrong about code review. We assumed the problem was speed. If AI helped teams write code faster, review would stay what it always had been, a final check for bugs, style, and edge cases before merge.
No one questioned that assumption. So when the code started arriving faster and in greater volume, review quietly became the bottleneck, and fixing that fell to whoever happened to notice, because no one had planned for it.
That approach belongs to a world where humans are still the main producers of code, which is no longer true. Microsoft's Satya Nadella has said AI now writes as much as 30% of the company's code, and Google's Sundar Pichai has said AI generates more than 30% of the company's new code.
Across companies and open source projects, this is the new normal. Cheaper code generation is exciting but AI agents are now writing code faster than anyone can review it, let alone trust it.
Human reviewers can't keep pace with the volume, and the tools for verifying that generated code does what it claims haven't matured nearly as fast as the models writing it. The result is more code shipping that no one fully understands.
Since our inception, CodeRabbit has prioritized automating code review and surfacing better intent analysis for AI-generated code. The nature of review hasn't changed: it's still where teams build understanding, trust, and alignment. What's changed is how much time people can give it.
The stakes are too high to treat AI-generated code as just another final checkpoint. CodeRabbit started as an automated code review tool, built to help teams catch issues faster. But as the volume of AI-generated code grew, the harder problem became clear: review isn't only about speed, it's about whether developers still understand and trust what they're shipping.
That's why we're going beyond faster automated review to support the people doing it. We want developers to move through manual review faster while holding onto the understanding and trust the process is meant to protect.
We redesigned the code review interface for the agentic SDLC so that, whether code is written by an AI agent or a person, developers can see what's changing, why it matters, what the risks are, and what's actually about to ship.
For the last two years, the industry optimized for its most visible breakthrough: code generation. You can see it in where the effort went. Benchmarks were built around coding tasks. Each new generation of models pushed to give AI agents more ability to solve complex problems.
That was the obvious place to focus, because the change felt dramatic and immediate. Whether it actually makes teams more productive is still hard to pin down, but the velocity of shipping has clearly changed one developer can now potentially ship far more in the same amount of time.Stack Overflow's 2025 Developer Survey says 84 percent of developers now use or plan to use AI tools in their development process, which is a sharp signal that AI-assisted coding is no longer a fringe workflow.
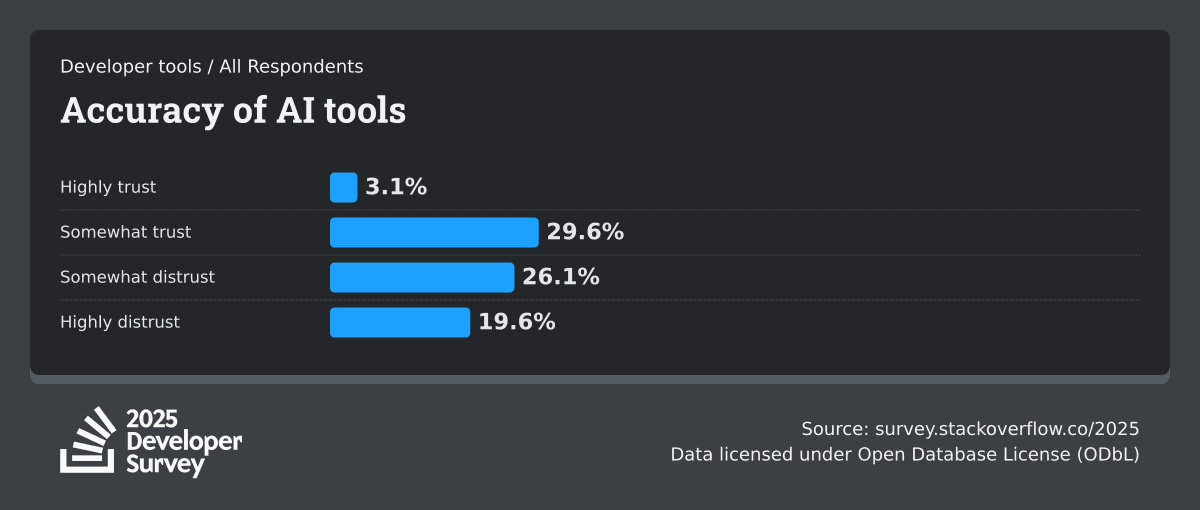
But, the same survey also says 46 percent do not trust the accuracy of AI output and 45 percent say debugging AI-generated code is time-consuming, which is the part the market moved past too quickly. Companies like OpenAI and Anthropic changed code generation, but understanding the code shipped hasn’t kept up to speed.
That gap becomes even clearer once you look past coding speed and into the rest of the software lifecycle. Atlassian's 2025 developer experience research says 99 percent of developers report time savings from AI tools and 68 percent save more than 10 hours a week, but 50 percent still lose 10 or more hours every week to organizational inefficiencies.
The main drag engineering teams face is finding information, adapting to new technology, and context switching across tools. That is why the story cannot just be that AI made engineers faster. It also made it easier for teams to generate more work than they can comfortably understand.
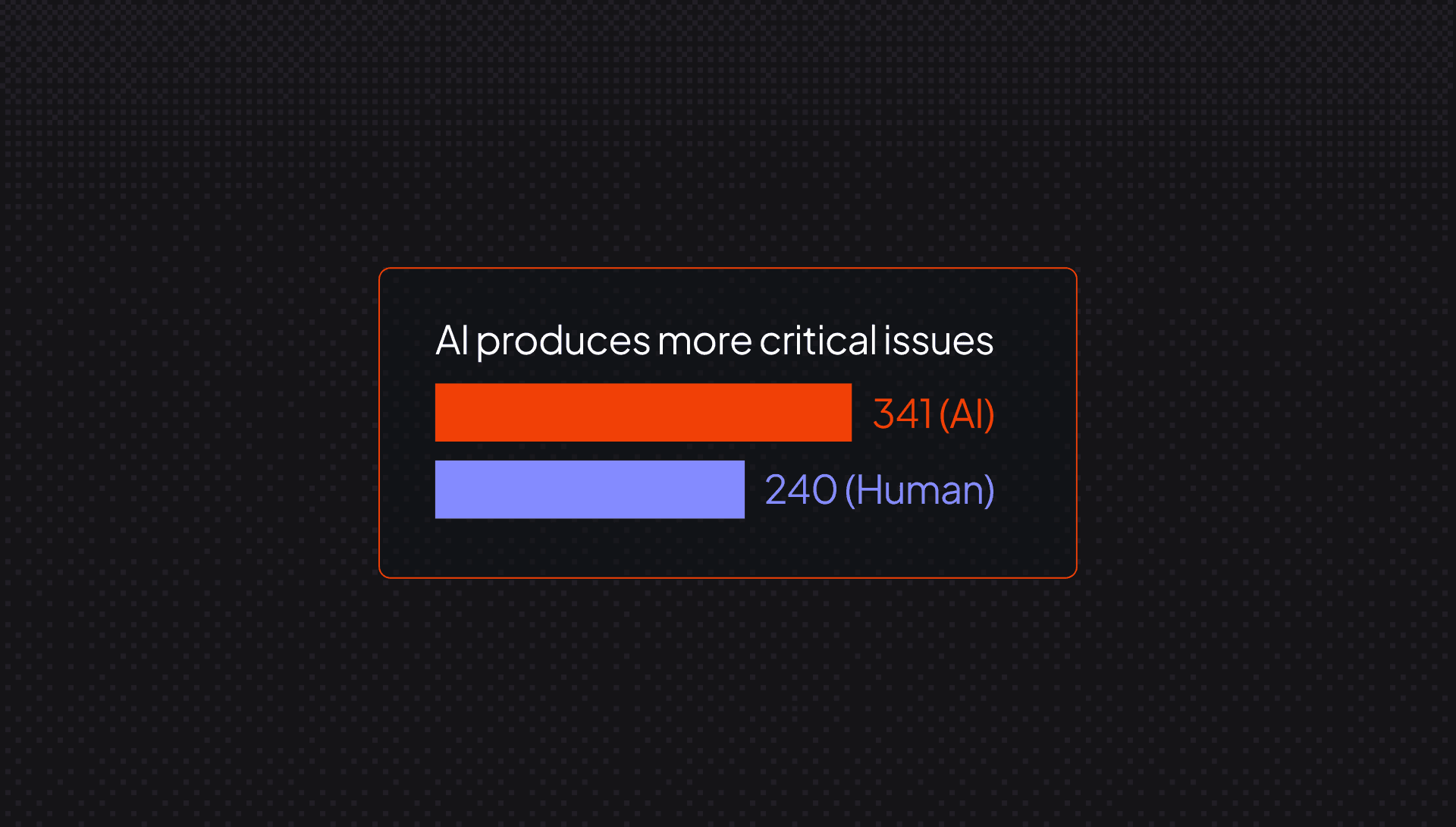
CodeRabbit's own data shows how that tradeoff appears inside pull requests. In the State of AI vs Human Code Generation report, which analyzed 470 real-world open source PRs, AI-generated PRs contained about 1.7 times more issues on average than human-written PRs, with logic and correctness issues up 75 percent, security vulnerabilities up 1.5 to 2 times, and readability problems up more than 3 times. The biggest takeaway from this is that code can arrive looking plausible long before it is genuinely trustworthy.
That model starts to fail once the volume of generated code rises and the reviewer is no longer just validating a change, but reconstructing it. The practical question is no longer only whether the code passes inspection. It is whether anyone on the team actually understands what the change is doing, why it was made this way, and where the risk sits.
The trust problem is what turns review from a narrow checkpoint into a much broader function. Google Cloud's 2024 DORA report says more than 75 percent of respondents rely on AI for at least one daily professional responsibility, but 39 percent report little to no trust in AI-generated code. If teams cannot trust the output at face value, then review becomes the place where intent, quality, and confidence are rebuilt before software moves forward.
Review now has to create explainability so a team can understand what changed without reverse engineering the whole diff. It has to create trust so reviewers can decide whether the implementation matches the stated intent. And it has to create coordination so linked issues, downstream systems, security concerns, and follow-up work do not get lost between the code and the conversation around it.
Atlassian's research on friction across the lifecycle and CodeRabbit's findings on defect rates in AI-generated PRs both point to the same conclusion, which is that the limiting factor is increasing comprehension rather than output.
That is also where the Agentic SDLC becomes a useful description instead of a vague one, because the lifecycle is no longer a simple sequence of human-only handoffs from ticket to code to review to merge. Once the whole agentic lifecycle is all shaped by agents, review stops being a final gate and becomes the shared place where teams recover intent and decide what is actually ready to ship.
Code review used to be the forcing function that made software at least somewhat collaborative. Too often they produce code with the same traits people already distrust in LLMs: confident hallucinations, stubborn wrongness, weak explanation, and very little sense of shared context.
CodeRabbit is the collaborative AI platform built for the agentic era. Our context engine understands your codebase, your conventions, and your team's past decisions, so reviews are grounded in how your team actually builds software, not in generic model behavior.
That foundation shows up in three places:
If you want to feel the difference, try one simple prompt: tell your coding agent to collaborate. Try CodeRabbit Review on the next PR, it is free for a limited time for every CodeRabbit user. You can find it by clicking Review Change Stack in the CodeRabbit PR summary comment.



