
CodeRabbit is now in the Claude Marketplace!Learn more

Atulpriya Sharma
November 26, 2024
14 min read
November 26, 2024
14 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Amazon S3 (Simple Storage Service) is a widely used cloud storage solution that allows users to store and manage data, including backups, static websites, and other files using buckets. While S3 offers significant flexibility and scalability, it also presents challenges such as ensuring proper access controls, managing data lifecycle policies, and maintaining security against unauthorized access. Misconfigured S3 buckets can lead to significant breaches, as seen in the FedEx incident, where an unsecured bucket exposed over 119,000 sensitive customer documents.
Cloud misconfigurations are among the leading attack vectors for cybercriminals, with recent industry reports indicating they account for around 15% of all data breaches. These vulnerabilities often happen because cloud environments are complex, and the pressure to release software quickly can make it hard to keep security measures in check.
Integrating security early in the development process is crucial to addressing this challenge. Code Review can play an essential role by ensuring best practices and security measures are in place right from the beginning. To assist with this, CodeRabbit integrates with the development pipeline and automatically reviews configuration files. It identifies potential vulnerabilities in S3 configurations, ensuring storage buckets are secure while allowing development teams to maintain efficiency.
S3 buckets are a powerful cloud storage solution, but improper configurations can expose sensitive data, leading to severe breaches. Developers sometimes delay changes to configurations with the mindset of "I'll fix it later," leaving vulnerabilities like misconfigured access controls unchecked. Over time, these unresolved issues can escalate their way into production environments, creating significant security risks. As seen in the Capita incident, misconfigured AWS S3 buckets exposed sensitive pension data and affected several local city councils in the UK.
S3 buckets are a powerful tool for cloud storage, but minor misconfigurations can lead to potentially disastrous consequences. Some of the major misconfigurations are:
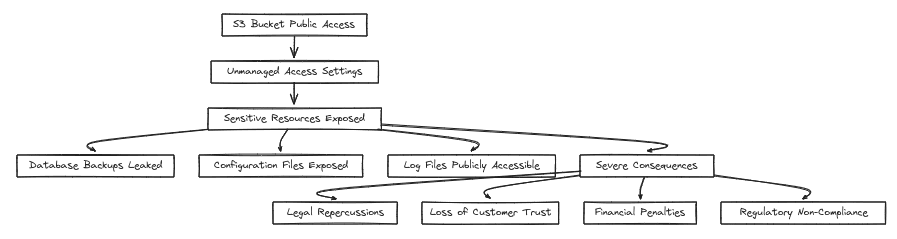
Public Website Assets Spillage: Teams often configure S3 buckets for hosting static assets like images and stylesheets. However, if the bucket’s public access settings are not carefully managed, sensitive resources like database backups, configuration files, or logs may be accidentally exposed to the public. Such exposure can lead to severe legal repercussions, loss of trust, and potential financial penalties due to regulatory non-compliance.
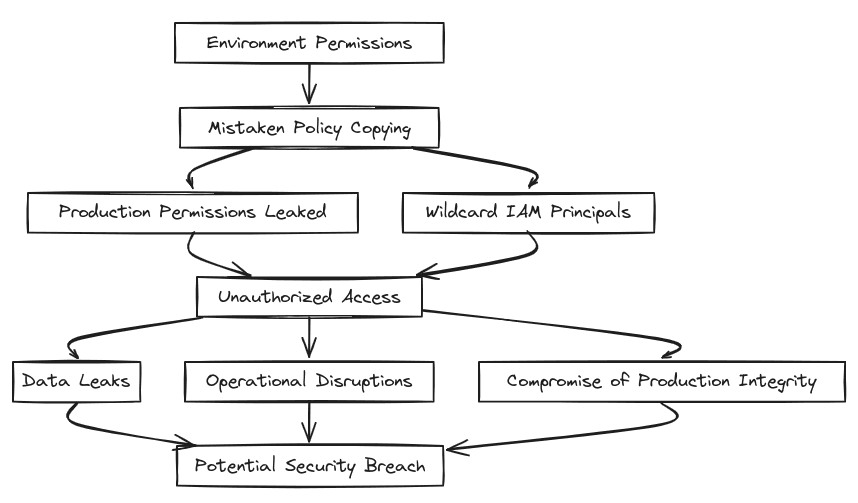
Cross-Environment Access: Development, staging, and production environments often require separate S3 buckets to manage different stages of the application lifecycle. However, issues arise when policies or permissions from the production environment are mistakenly copied to the development or staging buckets, allowing unintentional access. Additionally, wildcard IAM principals grant broad permissions, opening doors to unauthorized access that can result in data leaks or manipulations that compromise the integrity of production data and lead to significant operational disruptions.
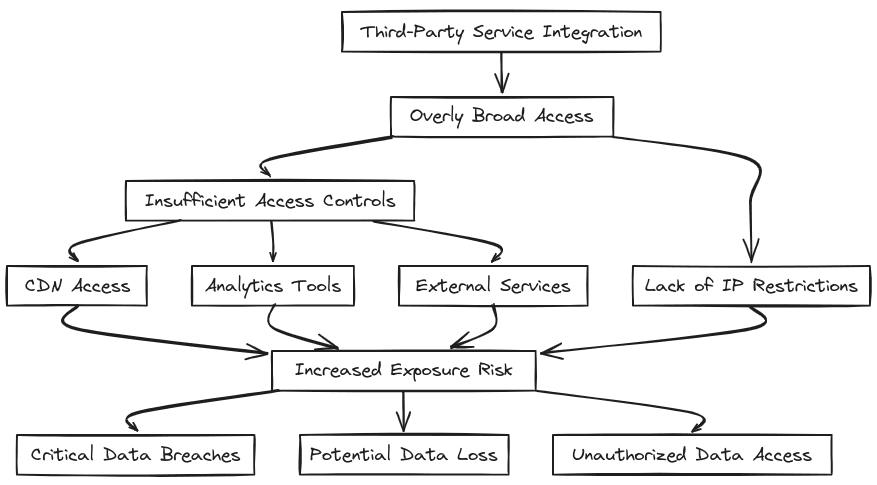
Third-Party Integrations: Many businesses integrate S3 with external services such as Content Delivery Networks (CDNs) or analytics tools to enhance performance and functionality. If bucket policies are not carefully crafted, they may grant overly broad access to third-party services, increasing the risk of unauthorized data exposure. Additionally, failing to implement IP restrictions can further widen this vulnerability leading to exposing critical data breaches or loss.
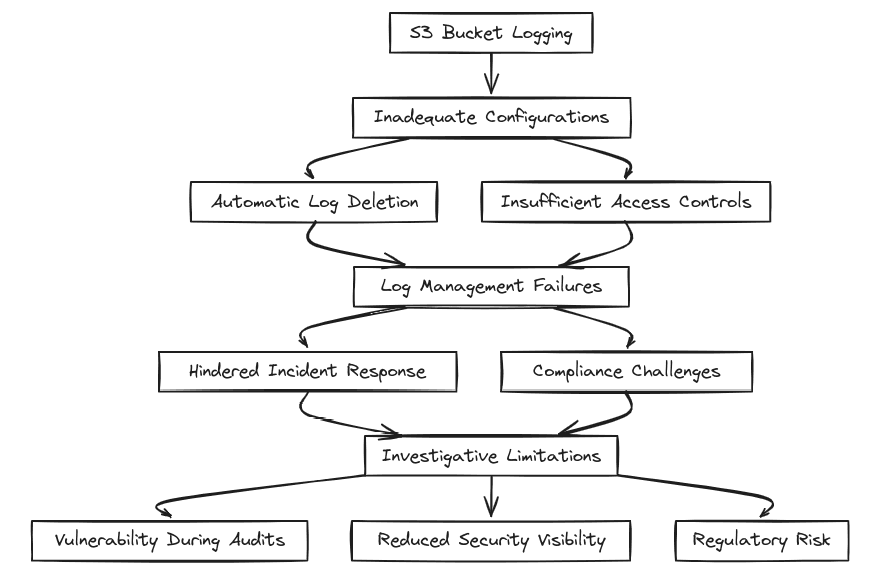
Logging & Auditing Issues: Proper logging is essential for monitoring access and changes to S3 buckets. However, some teams may set up logging without adequate configurations or inadvertently create policies that lead to the automatic deletion of logs. Without proper access controls for logs, organizations may find it challenging to investigate incidents or ensure compliance with regulatory requirements. Inadequate logging can hinder incident response efforts and leave organizations vulnerable during audits or investigations into breaches.
CodeRabbit offers a proactive solution to these challenges by integrating security checks into the development lifecycle. It assists in detecting possible security vulnerabilities, like incorrectly configured S3 bucket access or overly permissive IAM policies, by automatically examining configuration files at the beginning of the CI/CD process. This approach ensures that issues like public website asset spillage, cross-environment access risks, or inaccurate logging setups are detected early, well before they reach production.
To showcase CodeRabbit's ability to detect security vulnerabilities, we deliberately introduced typical misconfigurations in our S3 setup, including overly permissive bucket policies, lack of encryption, and incorrect lifecycle settings.
With a quick two-click setup, we integrated CodeRabbit into our repository, where it seamlessly identified these security risks in real-time.
Upon submitting a pull request, the system automatically reviews the files and produces a detailed report with these key sections:
Summary: A brief overview of the significant changes identified, emphasizing areas requiring attention.
Walkthrough: A detailed, step-by-step breakdown of the reviewed files, pointing out specific issues and offering suggestions for improvement.
Table of Changes: A table outlining all file changes along with a summary for each, helping prioritize actions.
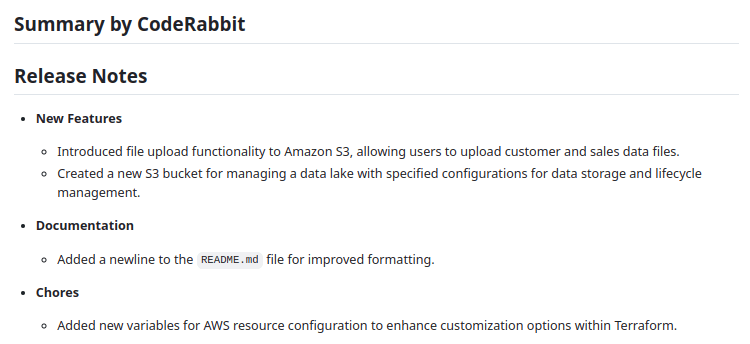

Here’s the sample terraform file that bootstraps a bucket with specific policies, which we will use to demonstrate CodeRabbit's capabilities in detecting S3 misconfigurations.
provider "aws" {
region = "eu-north-1"
}
resource "aws_s3_bucket" "data_lake_bucket" {
bucket = "coderabbit-s3-data-lake-demo"
acl = "public-read"
versioning {
enabled = false
}
encryption {
sse_algorithm = "AES256"
}
lifecycle {
prevent_destroy = false
}
cors_rule {
allowed_headers = ["*"]
allowed_methods = ["GET", "POST", "PUT"]
allowed_origins = ["*"]
max_age_seconds = 3000
}
logging {
target_bucket = "coderabbit-s3-data-lake-demo-logs"
target_prefix = "logs/"
enabled = false
}
tags = {
Environment = "Analytics"
Purpose = "Data Lake Storage"
}
}
resource "aws_s3_bucket_object" "raw_data_object" {
bucket = aws_s3_bucket.data_lake_bucket.bucket
key = "raw_data/customer_data.csv"
source = "customer_data.csv"
}
resource "aws_s3_bucket_object" "processed_data_object" {
bucket = aws_s3_bucket.data_lake_bucket.bucket
key = "processed_data/sales_data.parquet"
source = "sales_data.parquet"
}
resource "aws_s3_bucket_lifecycle_configuration" "data_lake_lifecycle" {
bucket = aws_s3_bucket.data_lake_bucket.bucket
rule {
id = "Move raw data to Glacier"
enabled = true
prefix = "raw_data/"
transition {
days = 30
storage_class = "GLACIER"
}
expiration {
days = 365
}
}
}
resource "aws_s3_bucket_public_access_block" "data_lake_public_access_block" {
bucket = aws_s3_bucket.data_lake_bucket.bucket
block_public_acls = true
block_public_policy = true
}
output "bucket_name" {
value = aws_s3_bucket.data_lake_bucket.bucket
}
The terraform file executes below operations:
Configures AWS provider and creates the S3 bucket.
Sets ACL with AES256 encryption and versioning.
Adds CORS rules and logging configuration.
Uploads raw and processed data files.
Defines lifecycle rules and object expiration.
Blocks public access and outputs the bucket name.
Here is the uploadFile.js script that uploads raw and processed data files to an S3 bucket.
const AWS = require('aws-sdk');
const fs = require('fs');
const s3 = new AWS.S3({
region: 'eu-north-1',
});
const bucketName = 'coderabbit-s3-data-lake-demo';
const rawDataFile = 'customer_data.csv';
const processedDataFile = 'sales_data.parquet';
async function uploadFile(fileName, key) {
const fileContent = fs.readFileSync(fileName);
const params = {
Bucket: bucketName,
Key: key,
Body: fileContent,
ACL: 'private',
};
try {
const data = await s3.upload(params).promise();
console.log(`File uploaded successfully: ${data.Location}`);
} catch (err) {
console.error('Error uploading file:', err);
}
}
uploadFile(rawDataFile, 'raw_data/customer_data.csv');
uploadFile(processedDataFile, 'processed_data/sales_data.parquet');
The file performs the following key operations:
Initializes the AWS S3 client with the region.
Defines the target bucket name and file paths for upload.
Reads file content from the local file system.
Constructs upload parameters including bucket, key, and access control.
Uploads files to the specified S3 bucket paths.
Logs success or error messages after each upload operation.
Having walked through, let’s deep dive into each review given by Code Rabbit.
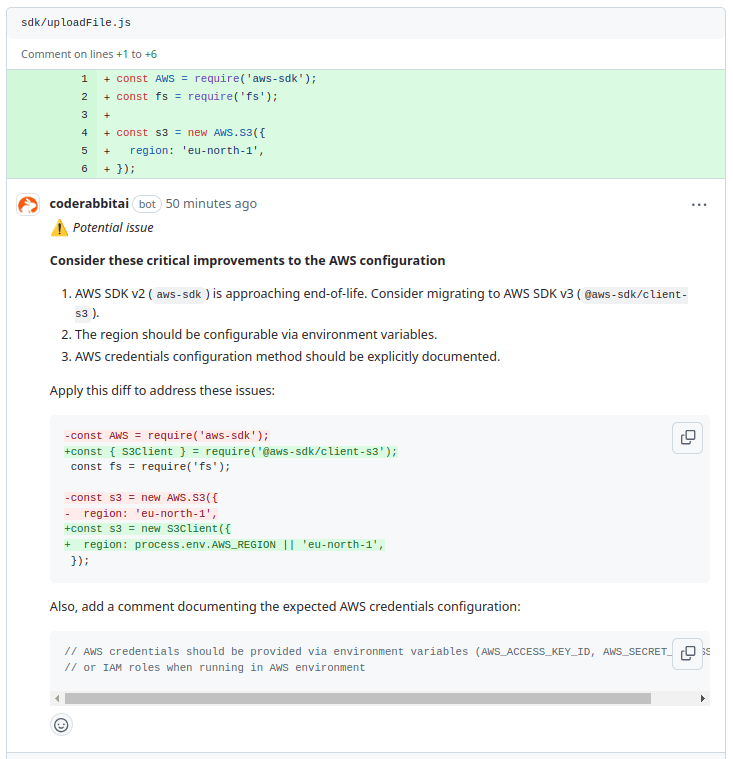
In the uploadFile.js script, CodeRabbit has identified potential issues with the current AWS SDK configuration. The code uses the AWS SDK v2, which is nearing its end-of-life, and should be upgraded to AWS SDK v3 for better performance and modern features. Additionally, the hardcoded region could be made more flexible by using environment variables. Finally, the method for providing AWS credentials is not clearly documented, which could lead to potential misconfigurations.
To improve this setup, it suggests migrating to AWS SDK v3, making the region configurable via environment variables, and explicitly documenting how to securely provide AWS credentials, either through environment variables or IAM roles when running in an AWS environment.
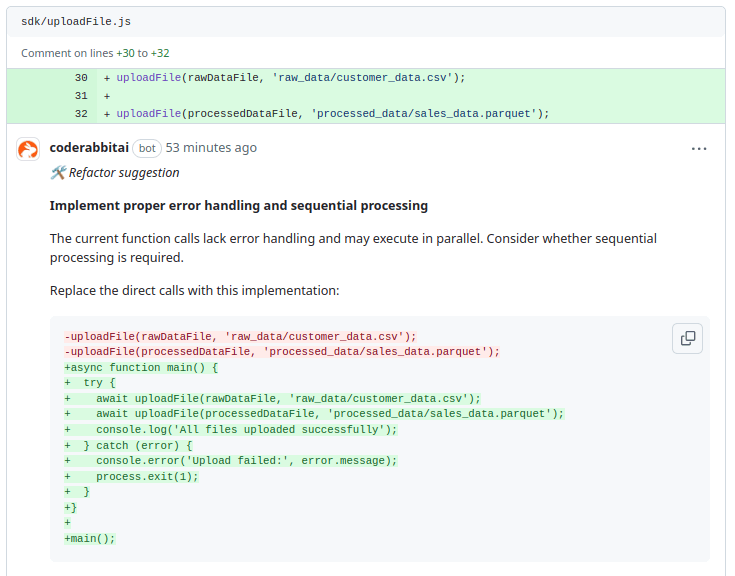
The current implementation of file uploads in uploadFile.js lacks error handling and may result in both uploads being triggered in parallel, which can cause issues if sequential processing is needed. Additionally, without proper error handling, any failures during the upload process may go unnoticed.
To address this, CodeRabbit suggests adding error handling and considering whether the uploads should be executed sequentially. This ensures that any upload failures are logged clearly, and subsequent steps are only executed if previous uploads succeed, thereby improving reliability and debugging in case of errors.
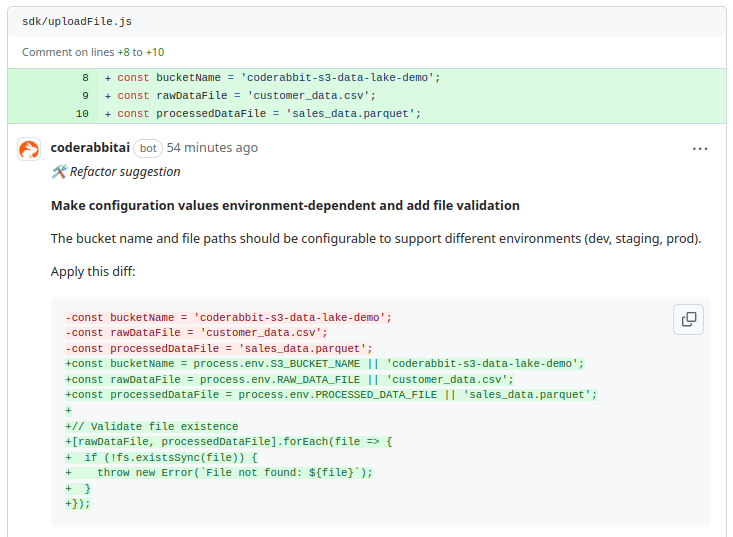
In the uploadFile.js script, CodeRabbit has detected that the bucket name and file paths are hardcoded, which reduces flexibility and makes it challenging to deploy in different environments (like dev, staging, or prod). Additionally, there is no validation to check if the specified files actually exist before attempting to upload them.
To improve this, it suggests making the bucket name and file paths configurable using environment variables. It also recommends adding file existence validation to prevent errors during the upload process due to missing files. These enhancements will make the script more robust and adaptable to different deployment scenarios.
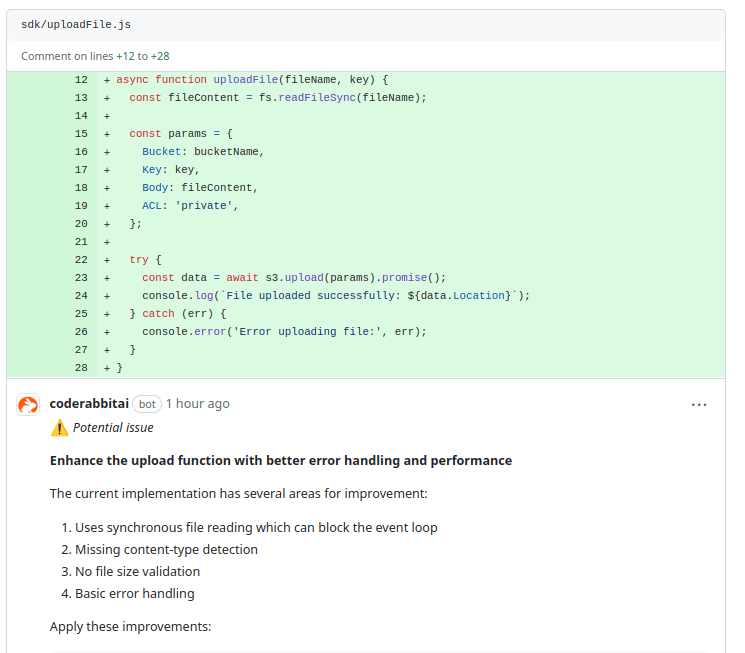
CodeRabbit has identified that the uploadFile function has performance and reliability issues. It uses synchronous file reading, lacks content-type detection, and does not validate file size. Additionally, error handling is basic and does not cover specific issues like access denials or missing buckets.
To improve the function, it is suggested to use asynchronous file reading, implement content-type detection, and validate the file size before upload. Enhanced error handling is also recommended to cover specific S3 errors, ensuring more robust and efficient file uploads.
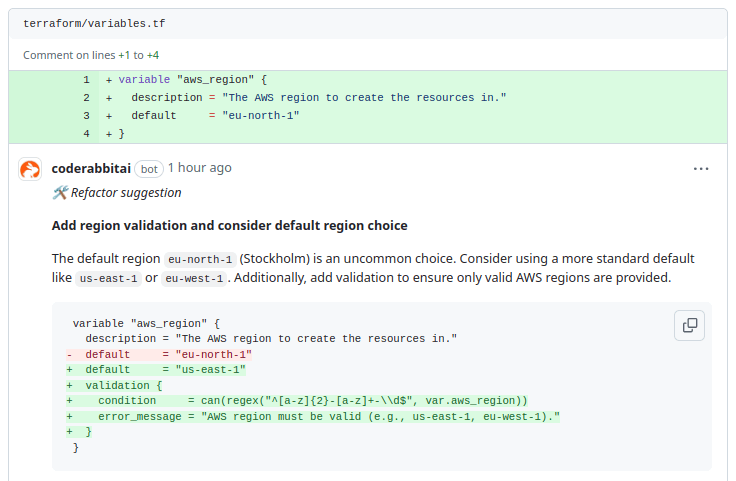
It states that the aws_region variable uses an uncommon default region (eu-north-1), which may not be familiar to all users. Additionally, there is no validation to ensure that only valid AWS regions are provided.
To improve this, it is suggested to switch to a more widely used default region like us-east-1 or eu-west-1. Additionally, a validation condition is recommended to ensure that the provided region follows the proper AWS region naming convention, enhancing the robustness and clarity of the configuration.
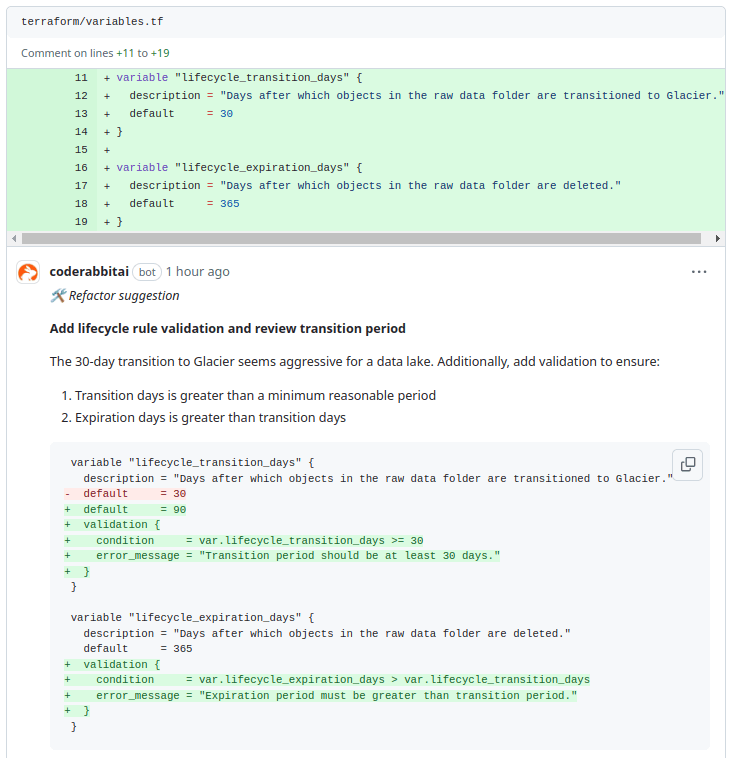
In the configuration, CodeRabbit recognized a potential issue with the lifecycle rule settings. The default 30-day transition to Glacier is considered too short for a data lake, as objects may need to remain accessible for a longer period before transitioning.
It suggests extending the transition period to 90 days and adding validation to ensure the transition period is at least 30 days. Additionally, it recommends ensuring that the expiration period is longer than the transition period to avoid premature deletion of data. These changes will help ensure that data is transitioned and expired according to reasonable retention policies.
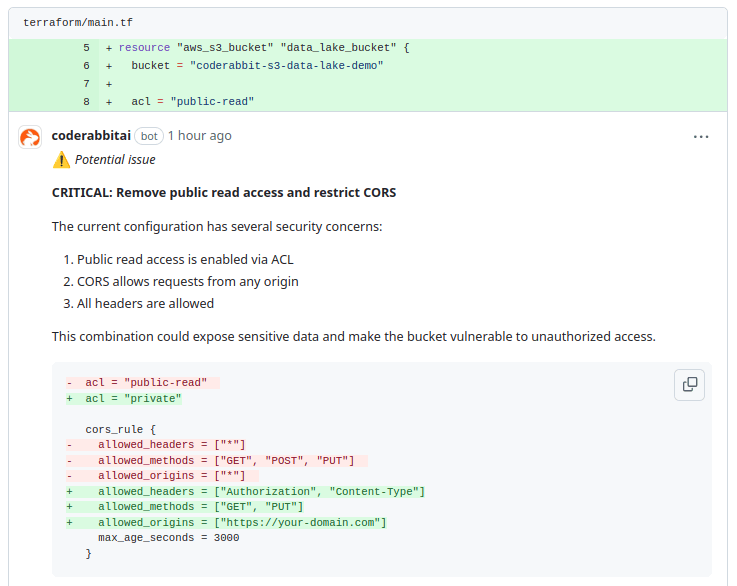
CodeRabbit has found security concerns in the current S3 bucket configuration. The public-read ACL is set, which allows public access to the bucket, potentially exposing sensitive data. Additionally, the CORS configuration is overly permissive, allowing requests from any origin and all headers, which could lead to unauthorized access.
It suggests removing the public-read ACL and changing it to private to restrict access. Moreover, it recommends tightening the CORS settings by specifying allowed origins, limiting allowed methods to GET and PUT, and restricting headers to only those necessary, such as Authorization and Content-Type.
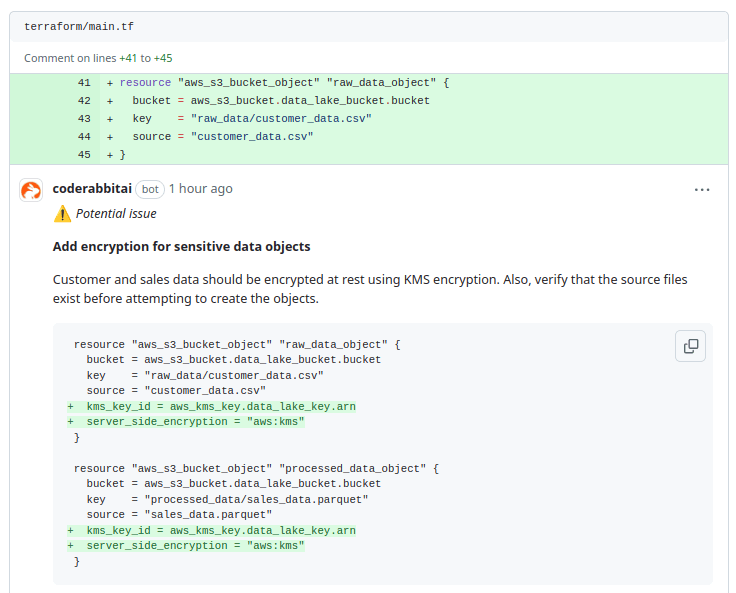
CodeRabbit has identified a potential security risk in the current S3 object configuration. The configuration does not include encryption for sensitive data objects, such as customer and sales data, which could expose them to unauthorized access. Additionally, the source files should be verified for existence before attempting to create the objects in S3.
To enhance security It recommends adding server-side encryption with AWS KMS (aws:kms) to ensure that sensitive data is encrypted at rest. It also suggests using a KMS key (e.g., aws_kms_key.data_lake_key.arn) to manage the encryption. Furthermore, a check should be added to verify the existence of the source files before proceeding with the upload to S3
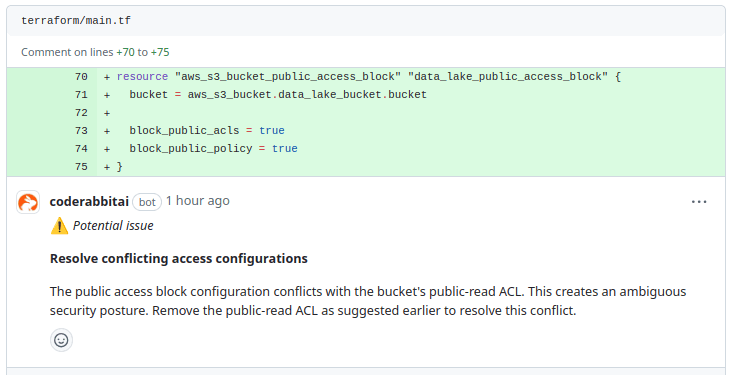
CodeRabbit has detected a conflicting access configuration in the S3 bucket setup. The current public access block settings are configured to block public ACLs and public policies, but the S3 bucket still has a public-read ACL. This creates ambiguity in the bucket's security posture and can lead to unintended public access.
To resolve this conflict and enhance security, it suggests removing the public-read ACL from the S3 bucket, as previously suggested. This will ensure that the access control settings are aligned and the data is properly protected from unauthorized public access.
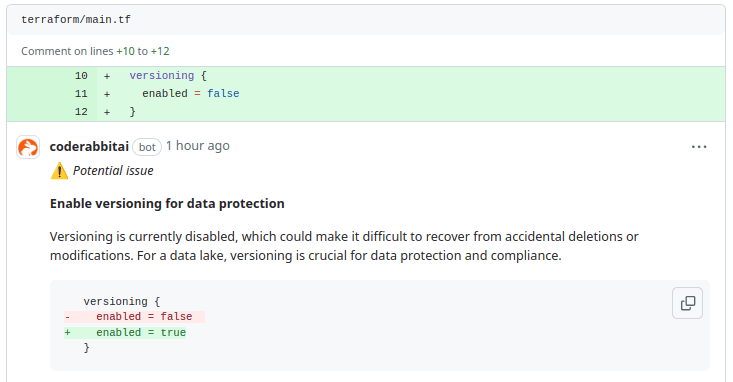
It has identified that versioning is currently disabled for the S3 bucket, which could pose a risk to data integrity. With versioning disabled, recovering from accidental deletions or modifications becomes difficult, which is especially critical in a data lake environment.
To enhance data protection and ensure compliance, it recommends enabling versioning. This will allow for preserving, retrieving, and restoring every version of an object in the bucket, improving the resilience and reliability of data storage.
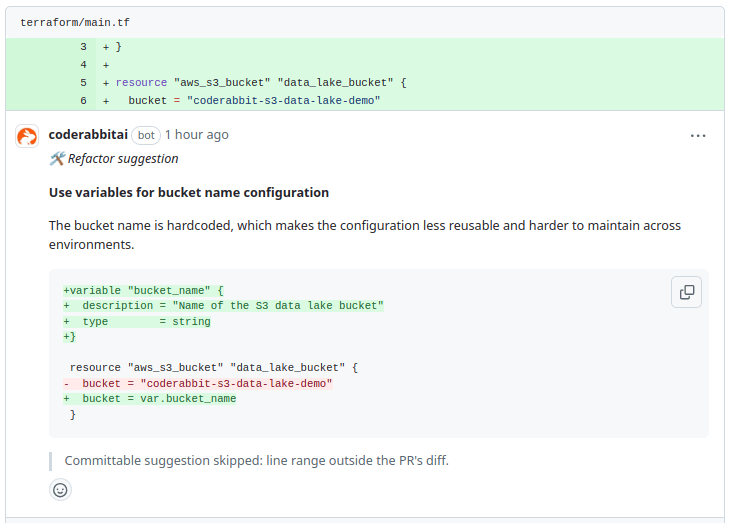
It suggests that the S3 bucket name is hardcoded in the configuration, which limits the flexibility of your Terraform setup and makes it harder to maintain across multiple environments (e.g., dev, staging, production).
To improve this, it suggests replacing the hardcoded bucket name with a variable. This would make the configuration more reusable and adaptable, allowing different bucket names to be used depending on the environment.
As seen, Coderabbit identified potential security risks in the S3 bucket configuration, including public access, permissive CORS settings, and lack of encryption, along with desirable solutions to mitigate these risks.
Minor configuration oversights today can become major security incidents tomorrow. CodeRabbit automatically reviews your S3 configurations during development, helping you ship secure code with confidence.
Join thousands of development teams who have secured their cloud infrastructure with CodeRabbit's automated code reviews. Sign up in 2 minutes, and get your first PR review in 10 minutes.



