

Atsushi Nakatsugawa
September 17, 2025
2 min read
September 17, 2025
2 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Ballooning context in the MCP era: Context engineering on steroids意訳です。
かつて、LLMにコンテキストを渡すには、ハックやベクターストラテジー、そしてお祈り…と、過剰に複雑なRAGパイプラインをつなぎ合わせる必要がありました。そこに登場したのが Model Context Protocol (MCP)。外部データを本番環境のモデルに提供するための、クリーンでモジュール的手法です。MCPは、実際に「何かをする」エージェントシステムを構築する人々にとって、瞬く間に標準的なプロトコルとなりました。
今ではほとんどのテック企業がMCP機能を打ち出していますが、その理由は明白です。MCPはコンテキストのロジックとアプリケーションロジックを分離し、信頼性を向上させ、複雑なワークフローでのプロンプト構築の混乱を抑える役割を果たします。
私たちはしばらく前からコンテキストエンジニアリングの領域に深く取り組んでおり、今回独自のMCPクライアントを立ち上げるにあたり、コードレビューにより豊かなコンテキストを注入できることに大いに期待しています。しかし正直に言えば、豊富なコンテキストにはリスクも伴います。MCP時代の隠された真実はこうです:かつて欲していたコンテキストに、今や私たちは溺れそうである。ログやトレース、diffなど "関連"ファイルが増え、モデルが本当に必要としているものが見えにくくなっています。
役立つ入力はすぐにトークンの膨張、ノイズ、パフォーマンス劣化につながります。引用付きハルシネーション、レイテンシの急上昇、あるいはカフェインを摂りすぎたインターンが書いたような散漫なレビュー。良いコンテキストエンジニアリングとは「すべて詰め込む」ことではなく、「何を省くか」を知ることでもあります。そしてMCP以降、そのバランスを取るのはより難しく、より重要になっています。
この記事では、膨張するコンテキスト問題 の詳細、その副作用、そして私たちがそれにどう立ち向かっているかを解説します。MCPを用いたLLM機能を開発している方で、プロンプト形のブラックホールを作り出したくない方に役立つ内容です。

MCPサーバーとクライアントは、モデルに膨大な情報を渡すことを容易にします:ログ、トレース、diff、設定、チケット、さらには誰も所有を覚えていないリポジトリの隅まで。すべてがモデルの手の届くところにあります。しかし、ここで重要な問いがあります:「コンテキストが多ければ多いほど良いのか?」 答えは間違いなく「NO」です。
過剰なコンテキストは、試験勉強で図書館全体を読むようなもの。ノイズは増えても、知識にはなりません。コンテキストが制御されなければ、次の3つの問題がすぐに現れます:
トークンの膨張
LLMには無限のキャパシティはありません。入力ウィンドウにはコストと限界があり、念のため…と詳細情報を詰め込みすぎれば、コストは増大してスループットは低下し、不要なテキストに予算を浪費します。
関連性の低下
情報が多いほど出力が良くなるわけではありません。むしろ悪化することが多いのです。無関係または冗長なスニペットがシグナルを希釈し、モデルはインサイトではなく枝葉に追われます。
レイテンシ
追加されるログやdiff、スタックトレースはすべて取得・処理され、プロンプトに押し込まれます。コンテキスト構築がボトルネックとなり、レビュー速度を著しく低下させます。
要するに、膨張するコンテキストはMCPの優雅さを逆にリスクへと変えてしまいます。意図的なコンテキストエンジニアリングがなければ、出力を磨くどころか押しつぶしてしまうのです。

実際には、以下の3つの典型的な問題が発生します:
コンテキスト混乱
モデルが無関係な詳細をシグナルと誤解してしまうケース。例えば認証ロジックを更新するPRに、無関係なテストフィクスチャが含まれていると、モデルはフィクスチャをレビューし始め、実際の変更と関係のないコメントを生成します。
コンテキスト衝突
コンテキスト同士が矛盾する場合です。例えば最新のスキーママイグレーションと古いドックストリングが同時に含まれると、モデルはどちらを信じるべきか迷い、結果として全方位的で自信のないレビューを生成します。まるで決断できないレビュアーのように。
コンテキスト汚染
最も厄介なのは誤った情報が混入するケースです。無用な関連ファイルや、誤ってインデックス化されたスニペットが注入されると、存在しないコードを引用するようになります。レビューでは、存在しないファイルのバグに言及し、開発者を混乱させ、時間を無駄にし、信頼を損ないます。
これはコードレビューに限りません。サポートボットが無関係なチケットを引っ張ってくる場合や、リサーチアシスタントが周辺論文に気を取られる場合、セキュリティエージェントがノイジーなログを証拠として扱う場合なども同様です。いずれにしても、間違ったコンテキストは「ない方がまし」なのです。
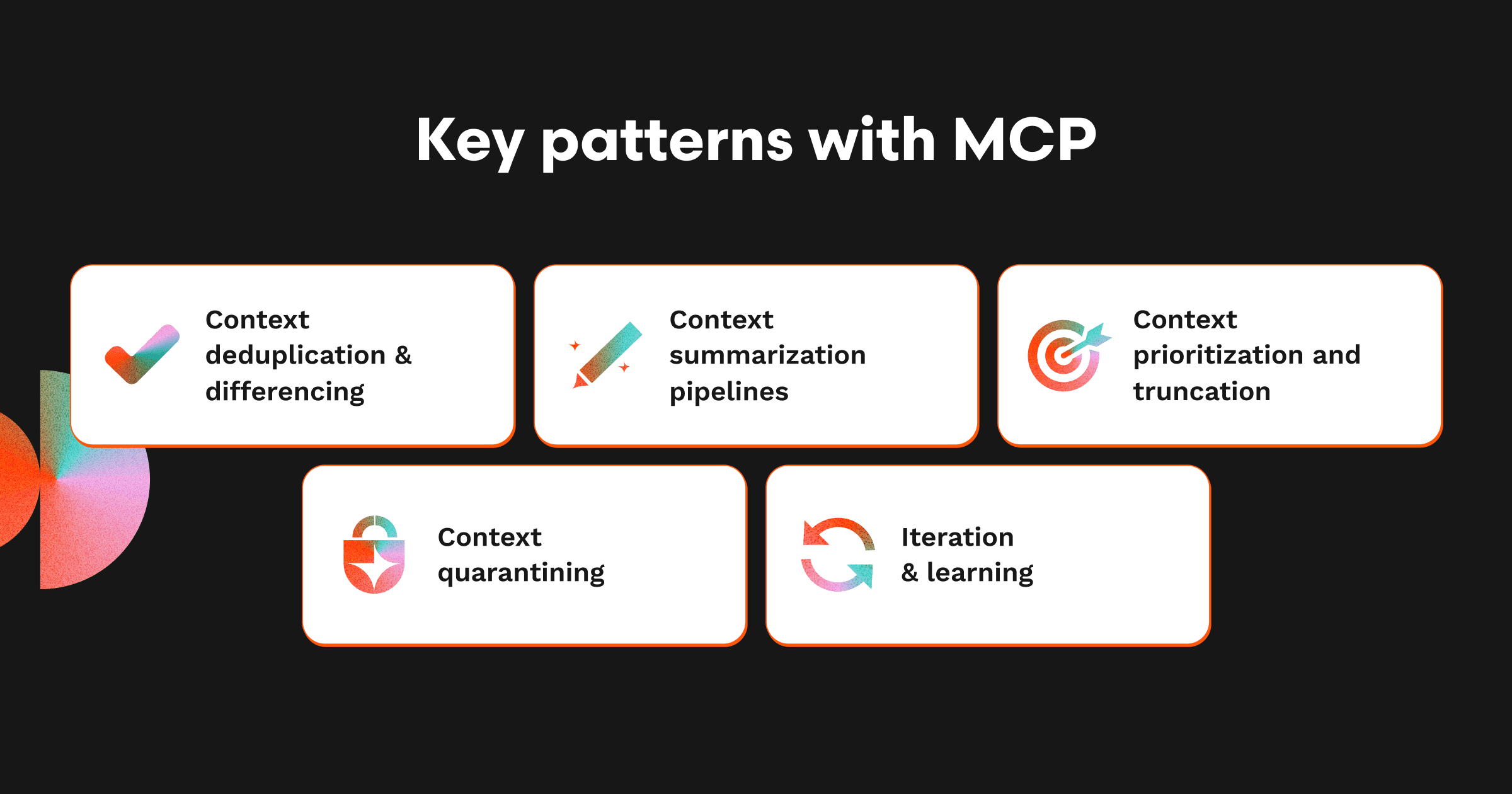
MCP時代の問題が、膨張するコンテキストだとすれば、解決策は情報の流入を止めることではありません。意図を持って選別・圧縮・提供することです。MCPのコンテキストは、生の素材をモデルに渡す前にきちんと設計されたデータ変換プロセスを経るべきものです。私たち自身のコードレビュー用MCPクライアントでも、コンテキストを高シグナル・低ノイズに保つために以下のパターンを採用しています。
コンテキストの重複排除と差分化
冗長な入力はトークン浪費の最短ルートです。同一のスタックトレース、繰り返しのログ、変更されていないdiff部分は10回も登場する必要はありません。クライアントは重複を検出して折りたたみ、新しい部分だけを強調します。この原則は他の領域にも適用可能です:重複するサポートチケットをまとめ、繰り返しのトレースを圧縮し、差分のみを残します。
コンテキスト要約パイプライン
MCP出力が依然として大きすぎる場合、LLM自体が要約して小さくすることも可能です。代償は圧縮と忠実度のトレードオフ:要約はニュアンスを失う可能性がありますが、詳細に溺れるよりはましです。実際には、重要ファイルは生のdiff、優先度の低いコンテキストは要約といったハイブリッド設計を採用します。
コンテキストの優先順位付けと切り捨て
プルーニングや要約後でも、どれを最初に入れ、後に回し、容量不足時に捨てるかを決める必要があります。MCPクエリごとにトークン予算を設定することは不可欠です。そうしなければプロンプトが予測不能に膨張します。私たちは切り捨てを前提にした設計を試し、場合によっては概要を先頭に、詳細を後半に配置するなど調整しています。
コンテキストの隔離
すべてのコンテキストを最初のプロンプトに含める必要はありません。サブタスクごとに専用のコンテキストスレッドを持たせるべきです。例えば、私たちのMCPクライアントではテスト失敗は専用のレビューサブスレッドに置かれ、メインのレビューコンテキストを妨げません。これにより混乱を減らし、長い対話でも明瞭さを保てます。
継続的な改善と学習
コンテキストエンジニアリングは静的ではありません。モデルのフィードバックや人間による修正を取り入れ、優先順位を調整していきます。重要なのは可観測性です。モジュールごとにプロンプト入力を記録し、何が通って何が無駄かを把握します。MCPダッシュボードやトークンヒートマップのようなツールが、予算超過や不要な入力を可視化します。

MCP時代はコンテキスト取得を容易にしました。おそらく「容易すぎる」ほどに。以下のようなアンチパターンがよく見られます:
ベクトル無差別投入
ベクトルDBは「関連」情報を見つけるのに優れていますが、それを万能の答えと見なすのは危険です。曖昧に関連するスニペットをすべて投入すると、関係のないファイルへのコメントや古いコードへの指摘で溢れるレビューになります。コンテキストの不適合はトークンの無駄だけでなく、モデルのパフォーマンスを引き下げる要因になります。
「全部突っ込め」方式
すべてのログ、diff、ドックストリングをコンテキストに放り込み、あとは神に祈るやり方です。コストの増加、レイテンシの悪化、結果の予測不能を保証します。モデルは重要な部分と不要な部分を区別できないため、全方位的で散漫なレビューを生成します。矛盾が混入すれば、モデルは曖昧さを埋めるために幻覚を引き起こします。
要するに、コンテキストは多ければ良いというものではありません。フィルタリング、優先順位付け、設計がなければ、「情報全部」はすぐにノイズに変わり、システムを遅く、鈍く、高コストにしてしまいます。
MCP時代において、コンテキストは「王様」です。しかし正直なところ、その王様は酔いすぎて上下も分からなくなっていることがあります。課題はもはや「コンテキストを得ること」ではなく、「それを制御すること」です。優れたコンテキストエンジニアリングには、緻密な変換パイプライン、徹底的な優先順位付け、そして改善を続ける謙虚さが必要です。これを怠れば、トークン膨張、レイテンシ、混乱したレビューを招きます。うまく実践すれば、ワークフローに沿った鋭い出力が得られます。
私たちは自社のコードレビュー用MCPクライアントでこれを実感しました。初期段階では全ログ・全ファイルをそのまま渡していました。その結果は高コストで、役に立たないほど散漫なレビューです。そこで重複排除、要約、タスク専用の隔離を導入したところ、レビュー品質が飛躍的に向上しました。すべてを指摘するのではなく、本当のクロスファイルリスクに集中するようになり、トークン消費とレイテンシも低下しました。
これこそが良いコンテキストエンジニアリングの成果です:情報量が多いのに散漫ではなく、本質を突いたレビュー。そしてそれこそが、私たちのMCPクライアントで実現しようとしていることです。
👉 コンテキスト設計の正しい姿を体験してみませんか? 今すぐ 14日間の無料トライアル でAIコードレビューをお試しください。



