

Atsushi Nakatsugawa
October 03, 2025
2 min read
October 03, 2025
2 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Claude Sonnet 4.5: Better performance but a paradoxの意訳です。
Sonnet 4.5はAnthropicの最新Claudeモデルであり、私たちのコードレビュー・ベンチマークでは一見パラドックスのように感じられます。より高性能で、より慎重でありながら、時にもどかしい。Sonnet 4では見逃したバグを見つけ、カバレッジではOpus 4.1に近づき、さらに想定外の重大な問題をいくつか浮かび上がらせることもあります。
しかし一方で、自己防衛的に振る舞い、自らを疑い、時に決断的なレビュアーというより思慮深い同僚のように見えることもありました。データでは確かな進歩が見られます。Sonnet 4ではコメントのうち、重要と判断されたものが35.3%だったのに対し、Sonnet 4.5では41.5%でした。しかし、そのコメントの調子や文体は、「AIレビュアーに何を求めるのか」というより深い問いを投げかけています。
そして決定的なのは価格です。Sonnet 4.5はOpusレベルの性能に近づきながら、価格は変わらず維持されています。つまり、大規模なコードレビューを行うチームにとって、実用的な最適点に位置しているのです。
Sonnet 4.5は思考を声に出しているかのようで、確かな修正を出す一方、曖昧な「条件付き」警告のようなコメントを出すこともあり、それが一部の開発者にとっては理解を難しくしているかもしれません。それでは、ベンチマークの詳細を見ていきましょう。
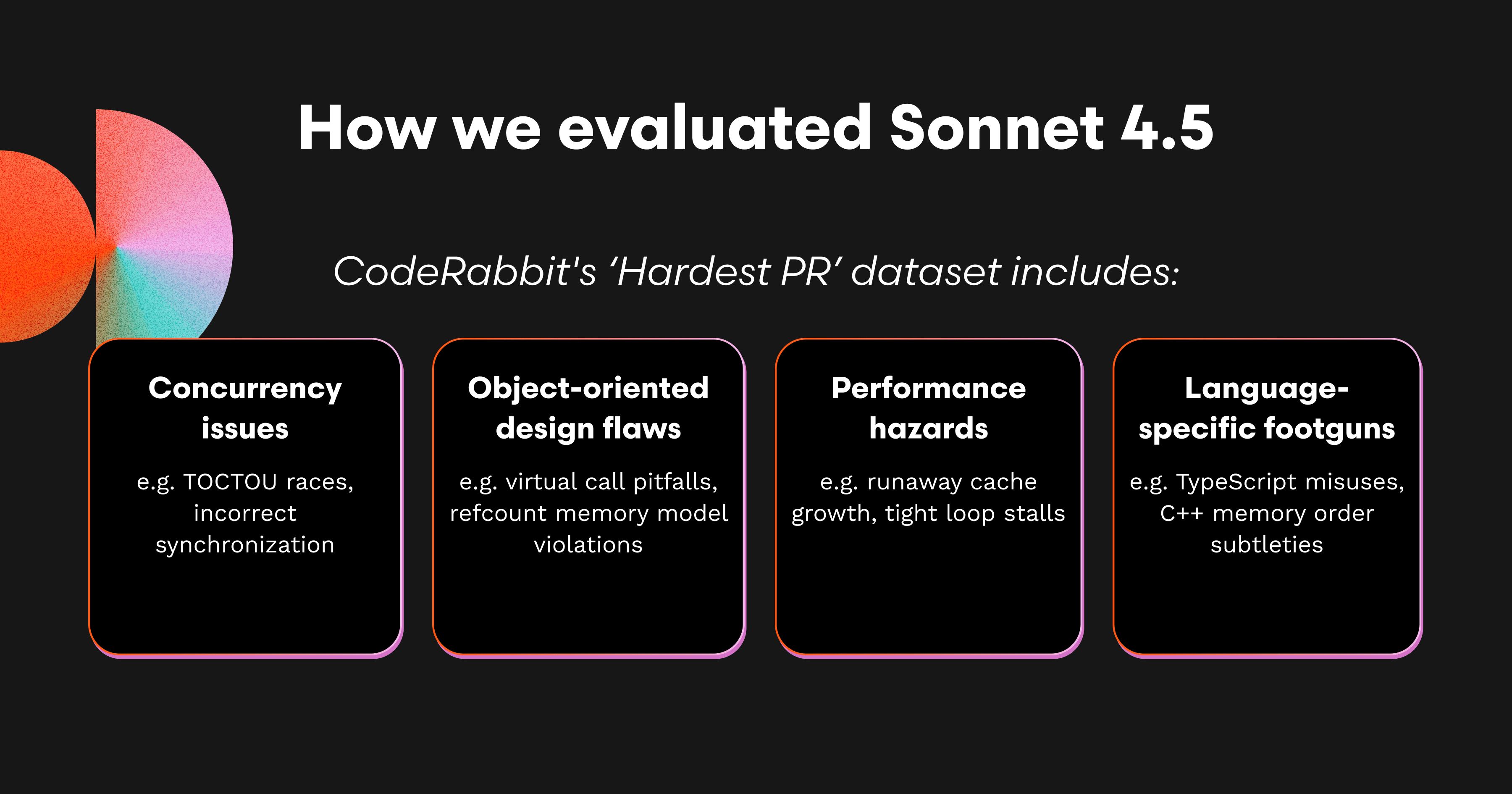
Sonnet 4.5、Sonnet 4、Opus 4.1の3つを対象に、25件の難易度の高い実際のプルリクエストで評価しました。これらには既知の重大なバグが含まれており(並行性やメモリ順序、非同期レースコンディション、APIの誤使用など)、モデルがその重大な問題に直接コメントを出せた場合、そのPRは「合格」としました。
評価指標は、カバレッジ(S@25)、精度(コメントの合格率)、そしてシグナル対ノイズ比です。シグナル対ノイズ比については、重要なコメント(Important comments) に注目しました。これらは最も価値のあるコメントであり、以下を含みます。
PASSコメント:PR内の既知の重大バグを正しく指摘・修正したもの
その他の重要コメント:追跡対象ではないが、別の重大または深刻なバグを的確に指摘したもの
結果は以下の通りです。
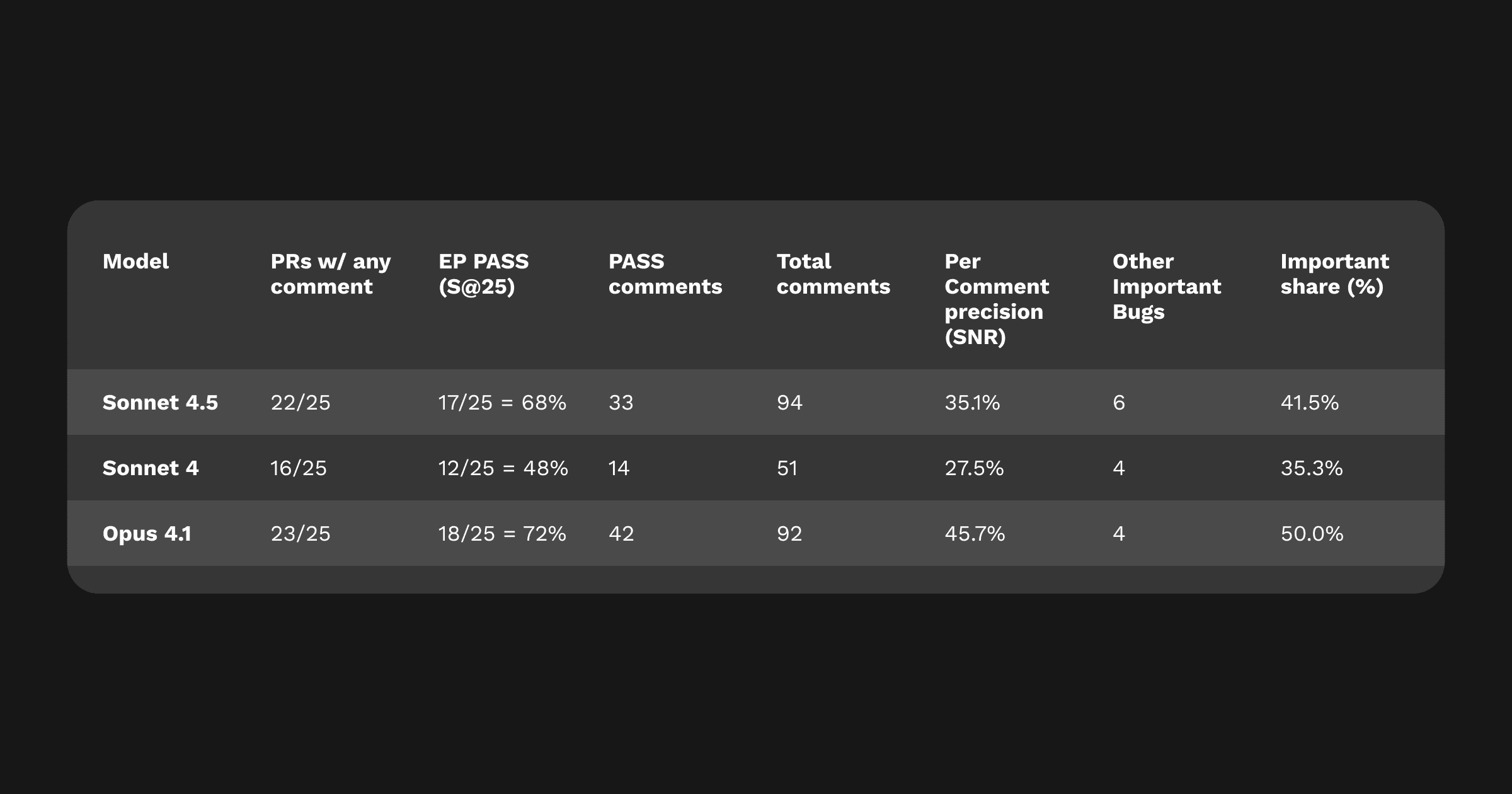
カバレッジ: Sonnet 4.5はSonnet 4とOpus 4.1の間の差を大きく縮め、Sonnet 4を大きく上回りました。
精度: Opus 4.1は依然として最も正確で信頼性の高い実行可能なコメントを生成しました。高価格モデルであるため当然の結果です。
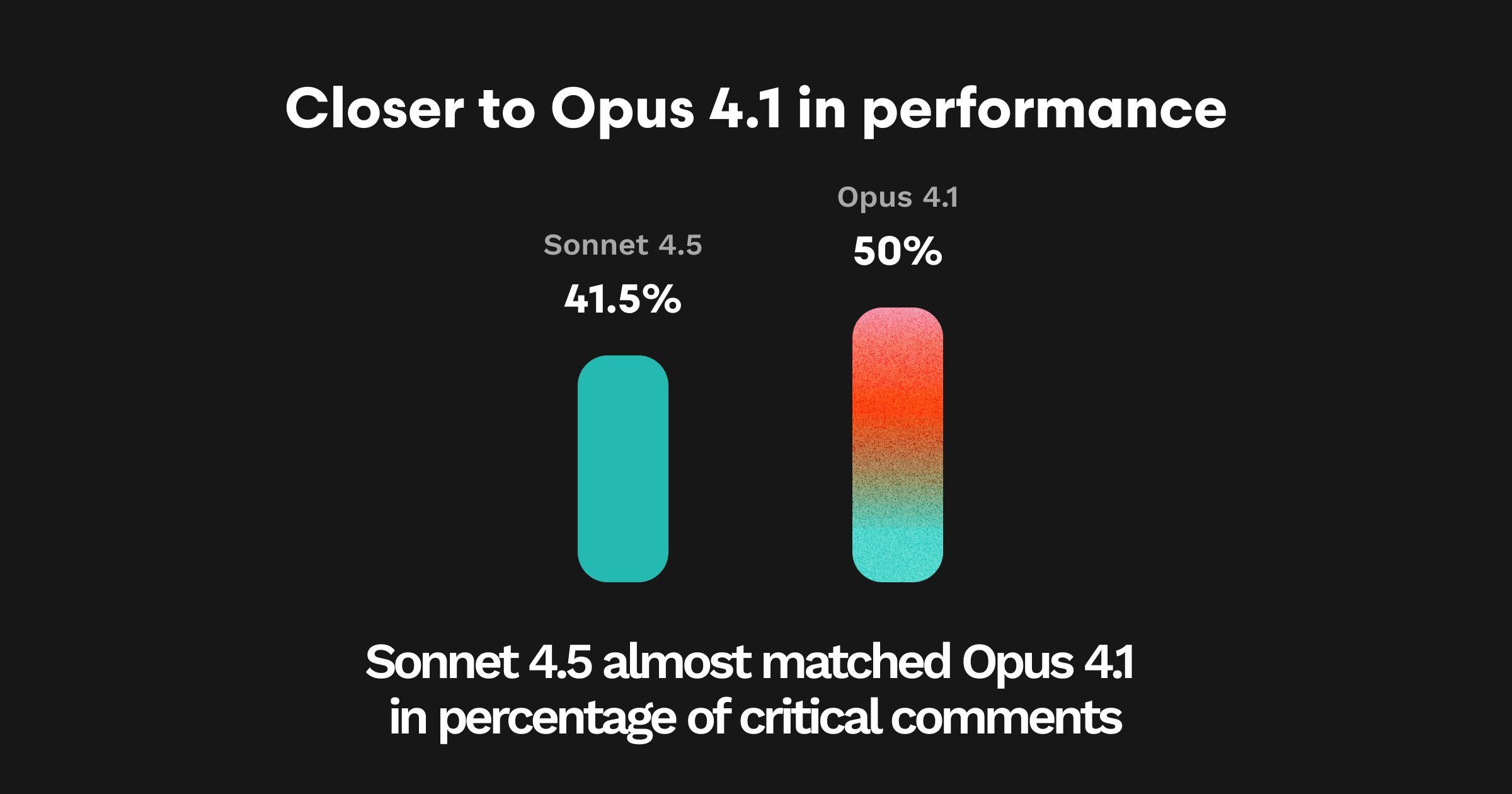
重要コメント率(重大な問題を指摘したコメントの割合): より厳格な基準で測定した場合、Sonnet 4.5の重要コメント率は約41%。つまりコメントのうち4割が、主要なバグを解決するか、別の重大な問題を指摘していたことになります。Opus 4.1は50%、Sonnet 4は約35%でした。
Sonnet 4.5のコメントはコードを修正しますが、Opus 4.1ほど自信に満ちたトーンではありません。ただし、Sonnet 4よりは明確です。
修正パッチの提示率:
Sonnet 4.5の実行可能コメントのうち87%はコードブロックやdiffパッチを含み、Sonnet 4(90%)、Opus 4.1(91%)とほぼ同水準です。
違いは文体にあります。Opusのdiffは「外科的修正」のように明確ですが、Sonnet 4.5は探索的な文章を添える傾向があります。修正を「提案する」「検討する」といった表現が多く、断定的ではありません。
慎重な言い回し(Hedging language):
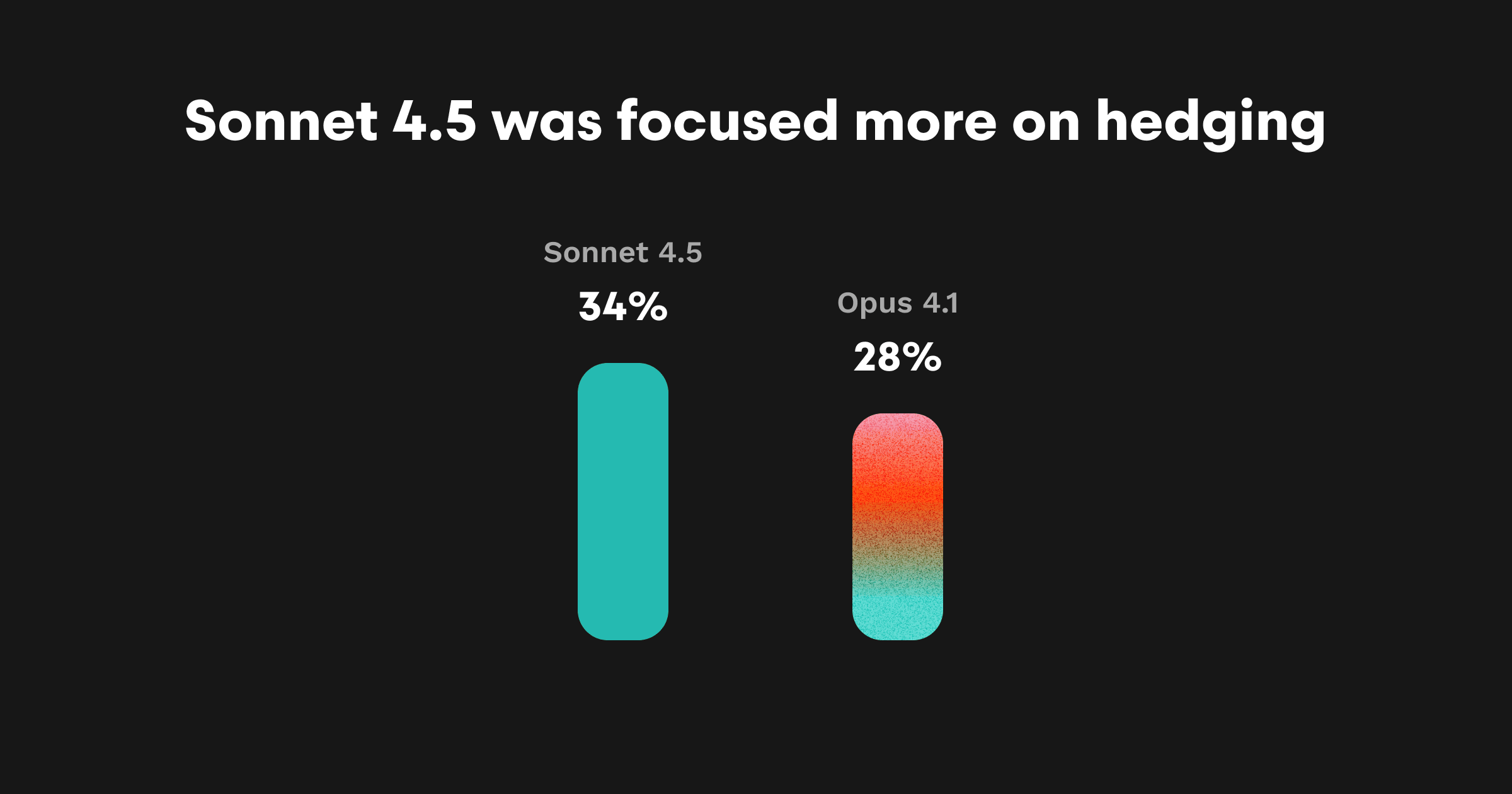
Sonnet 4.5では実行可能コメントの**34%**において、「might」「could」「possibly」といった慎重な表現が見られます。例:
“不要なアロケーション: cacheは使用されていません。 コンストラクタで4KBのメモリを確保していますが、使われていません。… cache_bufferの削除を検討してください。”
“空のtry/exceptブロックを削除してください。 …おそらくプレースホルダーです”
Opus 4.1は約28%、Sonnet 4は約26%とやや低め。
この慎重さにより、「問いかける」ようなトーンが生まれます。Sonnet 4.5はしばしば一緒に考えているような雰囲気を持ち、明確な判定を下すというより「共に推論している」ように感じられます。
自信のある言語(Confident language):
ただし、Sonnet 4.5は慎重さを補うように、高い確信を示すコメントも**39%**含んでいます。Sonnet 4(18%)、Opus 4.1(23%)よりも高い割合です。例:
“重大: self.プレフィックスが欠落しており、すべてのAPIメソッドが動作しません。 このままでは全てのメソッドがAttributeErrorを発生させます。”
“整数オーバーフローの可能性: optimization_cycle_countが無制限にインクリメントされ続けます。これは約414日稼働後に必ずオーバーフローします。”
つまり、慎重さと確信の間で大きく揺れ動くのです。
シグナル対ノイズ比:
Sonnet 4.5はSonnet 4より精度が向上しましたが、依然としてOpusよりも「軽微な」的外れコメントが多めでした。
ただし、重要コメント(PASSコメント+少数の高確信度コメント)に限定すると**41.5%**を達成。Opus 4.1は依然として約50%で最高水準です。
評価したPR群では、Sonnet 4.5が明確に、特に優れていた領域が見られました。

並行性バグ検出: C++のatomic操作やcondvarの誤用を的確に特定し、実行可能なdiffを生成
整合性チェック: サービス間での分散状態の不整合を確実に検出
追加バグの発見: 評価対象外のCritical問題も検出しましたが、より厳密な基準では件数はやや減少
AnthropicはSonnet 4.5を「ハイブリッド推論」「長期的計画立案」モデルとして打ち出しています。実際、コード内の副経路を追跡し、未追跡の実際の問題を発見する傾向が見られます。
Sonnet 4.5の最大の強みの一つは、価格対性能比にあります。Opus 4.1は依然としてAnthropicの最上位モデルですが、その分コストも高額です。
Sonnet 4.5はカバレッジと重大バグ検出能力の差を縮めつつ、はるかにコスト効率が良いです。多くのチームにとって、Opusレベルの結果を低コストで得られるこのバランスこそが、最も実用的な選択肢となる理由です。
ただし、Sonnet 4.5を使用する際はその弱点を理解しておく必要があります。

デッドロック検出: Sonnet 4やOpusと同様、複雑なロック順序の追跡はまだ苦手です
冗長さと慎重さ: コメントが長く、留保的または曖昧なことがあります。以前の研究で評価したGPT-5 Codexは「パッチのように読める」ほど明快なコメントを書く傾向がありました。例として、GPT-5 Codexのコメントを以下に示します。
ロック順序 / デッドロック: 「ロック取得を一貫した階層順に並べ替えてください。これにより循環待ちデッドロックを防げます」
正規表現の壊滅的バックトラッキング: 「ネストされた量指定子を削除してバックトラッキングを回避します」
精度のギャップ: コメント単位の精度35%、重要コメント率41.5%はSonnet 4より良いものの、Opus 4.1にはまだ届きません。
Sonnet 4.5は「赤ペン先生」ではなく、そばで考えてくれる同僚のようです。可能性のある問題を指摘し、ほとんどの場合は正しく、時に慎重すぎる時もあります。ときには、思いがけない箇所にまで目を向けてくれます。
このスタイルはレビューにおいて諸刃の剣です。一方では、開発者は追加の重大問題を指摘してくれることを評価するでしょう。もう一方では、「このバグを確実に見つけてほしい」という場合、Opus 4.1のほうが鋭いです。
AnthropicはSonnet 4.5を「エージェント的推論とコンピュータ利用」に向けたステップと位置付けています。コードレビューでは、その推論力がより豊かで慎重かつ広範なコメントとして現れます。
チームにとっての選択肢はこうです。
明確でパッチのようなフィードバックを重視するなら、Opus 4.1(またはGPT-5 Codex)が依然として基準として優れています。
トラッキング対象外の隠れた重大問題まで発見したいなら、Sonnet 4.5が有力です。
コスト効率を重視するなら、Sonnet 4.5が最も賢い選択肢です。Opus並みの精度を低価格で実現します。
いずれにせよ、Sonnet 4.5はレビュー体験の質感を変えます。より人間的で、常に明快とは限らないものの、より探究的で、より慎重で、時にあなたが見逃していた「正解」に辿り着くこともあるのです。



