

Atsushi Nakatsugawa
August 07, 2025
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Benchmarking GPT-5: Why it's a generational leap in reasoningの意訳です。
お待たせしました!AIコードレビューのリーディングツールであるCodeRabbitは、複雑なコードベースにおける理解、推論、エラー検出能力を評価するために、OpenAIのGPT-5モデルへの早期アクセスを受けました。
GPT-5のテストの一環として、モデルがコードベースの潜在的な問題やバグを理解し推論できる能力に焦点を当て、その技術的な特徴、能力、ユースケースを明らかにするための広範な評価を実施しています。
以下では、体系的な評価アプローチの内訳、他の人気モデルとの比較における詳細な知見、そしてGPT-5をAIコードレビューにどのように組み込み、さらに改善していくかをご紹介します。

GPT-5は、難易度やエラー種別が多様な300件のプルリクエストからなるテスト群で、Opus-4、Sonnet-4、OpenAIのO3を上回りました
包括的テストで最高スコアを記録し、300件中254件、すなわち85%のバグを発見しました。他モデルは200〜207件で、16%から22%少ない結果でした
評価データセットの中で最も難しい25件のPRにおいて、GPT-5は史上最高の合格率77.3%を達成しました。これはSonnet-4比で190%の改善、Opus-4比で132%の改善、O3比で76%の改善を示します
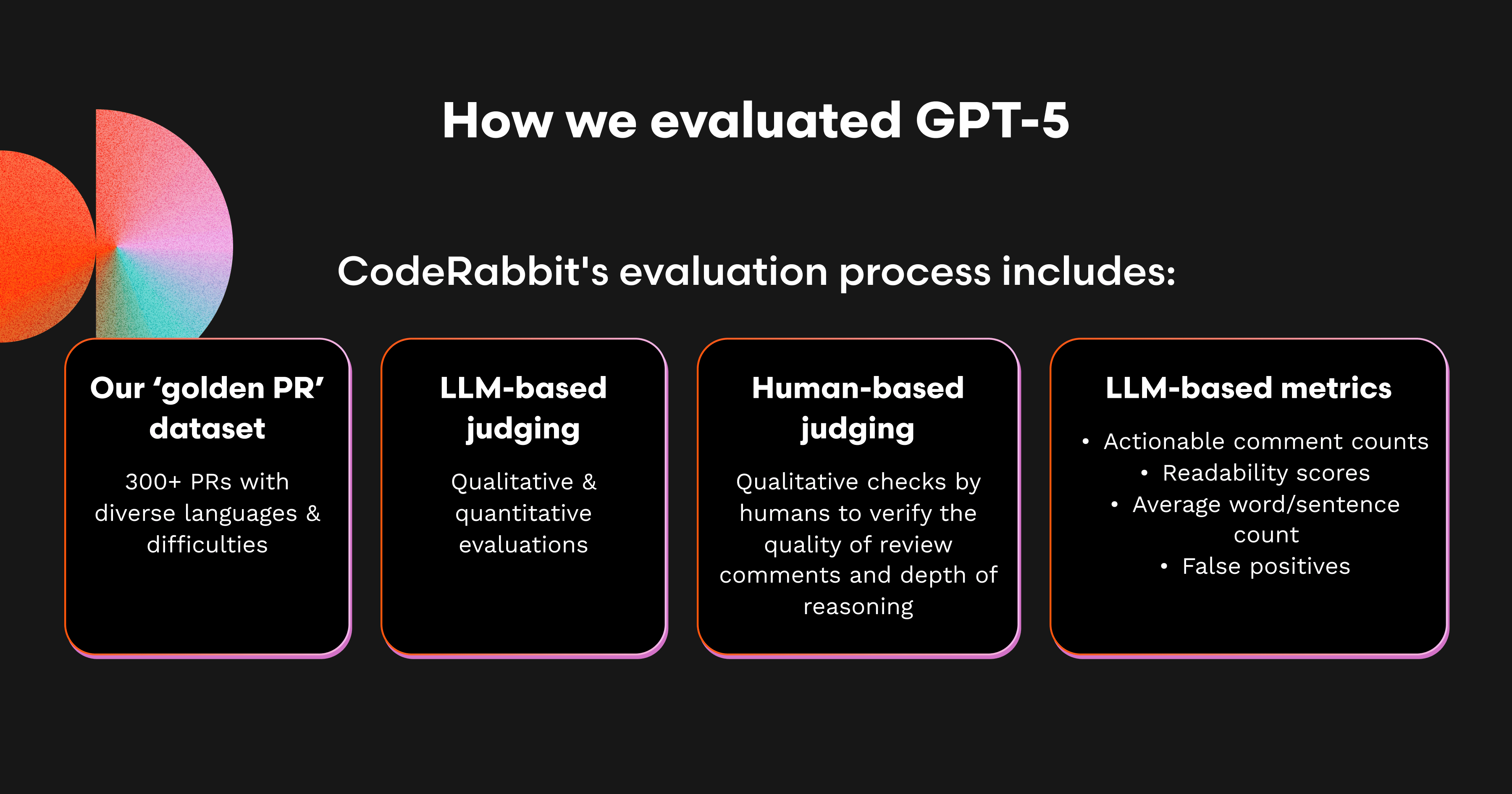
当社はすべてのモデルに対して実施している同一のテストを再現しました。これらの評価では、GPT-5をコンテキストが豊富で非線形なコードレビューパイプラインに統合し、一般的なコードレビューでのパフォーマンスを確認しました。
CodeRabbitの評価プロセスには以下が含まれます。
LLMベースの判定:レビュー品質やモデルの正確性の合否など、定性的かつ定量的なデータを二層で評価します。
人手による判定:レビューコメントの品質やモデルの推論の深さを人間が定性的に検証します。
LLMベースのメトリクス収集:高品質なコードレビューの指標と考えるメトリクスを収集し、その重要度に応じて重み付けします。これらのメトリクスには以下が含まれます。
実行可能なコメント数
可読性スコア(Flesch Reading Ease)
平均語数
文数
偽陽性(ハルシネーション)
注意:OpenAIからリリース前に共有された複数のGPT-5のスナップショットに対して評価を実施しました。結果はスナップショットごとに多少変動しましたが、相対的な一貫性があったため、以下の観察を行うことができています。リリース版はわずかに異なる可能性があります。
本評価では、GPT-5は期待に十分応えるものであることが分かりました。GPT-5は当社のデータセット上で他のすべてのモデルを大きく上回っています。
GPT-5の包括評価における重み付きスコアはテスト実行ごとに3465〜3541の範囲でした。これは以前に最高スコアであったOpenAIのO3やAnthropicのSonnet 4をほぼ200ポイント上回ります。最大得点は3651です。
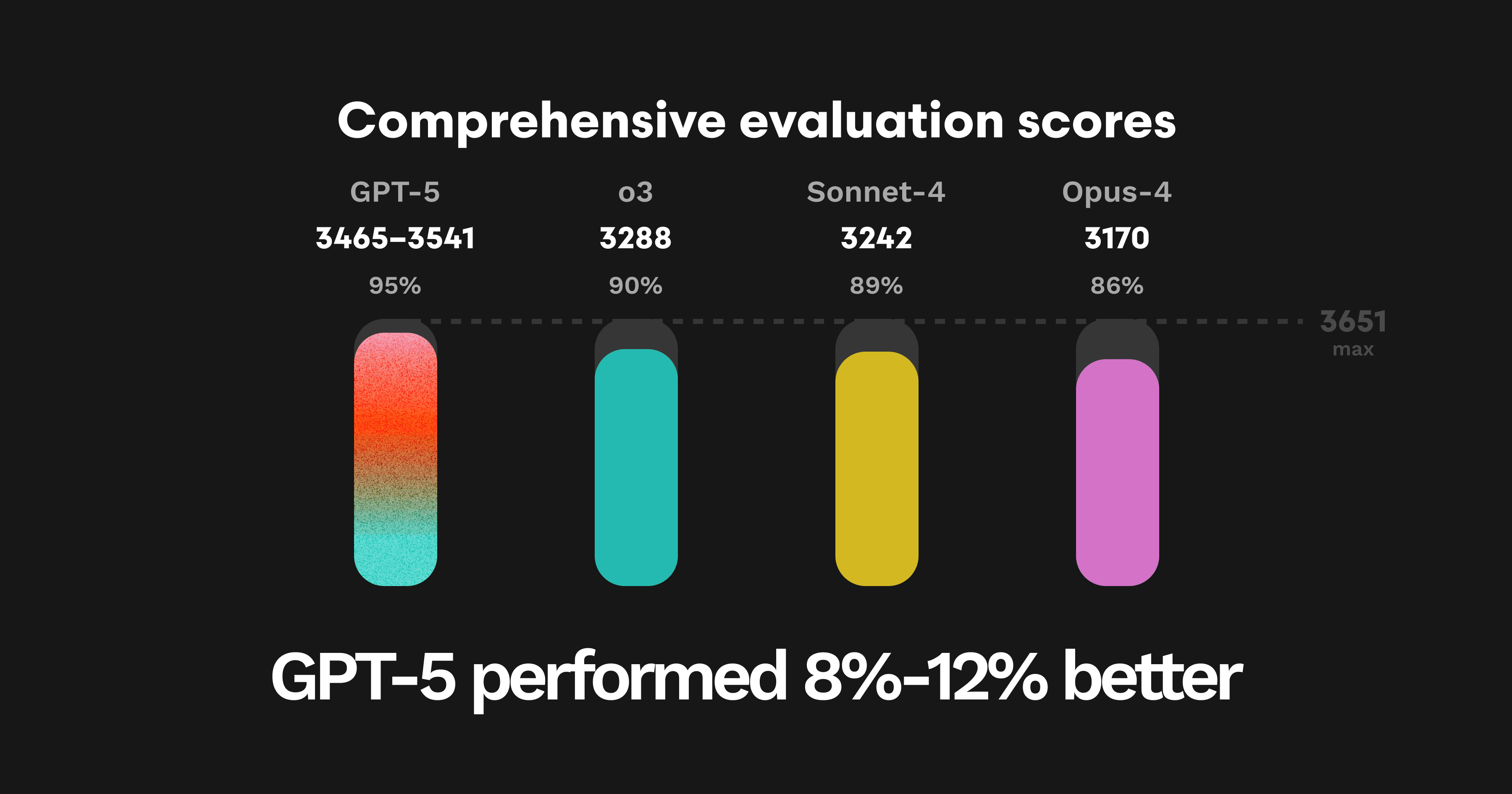
評価スコアの詳細です。
GPT-5:3465–3541
O3:3288
Sonnet-4:3242
Opus-4:3170
要点:200ポイント、すなわち5%の増加は一見すると大きくないように見えるかもしれません。当社のテスト方式では、モデルはまず無限ループや露出したシークレットキーのような取りこぼしにくい問題で点を稼ぎます。その後は残りの点がより見つけにくい難問の指摘によってしか加算されなくなります。つまり、GPT-5が他モデルよりも多くの点を獲得できたことは、推論能力の大幅な飛躍を意味します。
当社はまた、データセットのPRに含まれる300種類のエラーパターンのうち、モデルがいくつ発見できたかに基づく合否スコアも付与しています。GPT-5はこの尺度でも過去最高の成功率を達成し、300中254〜259でした。
他モデルの性能との比較です。
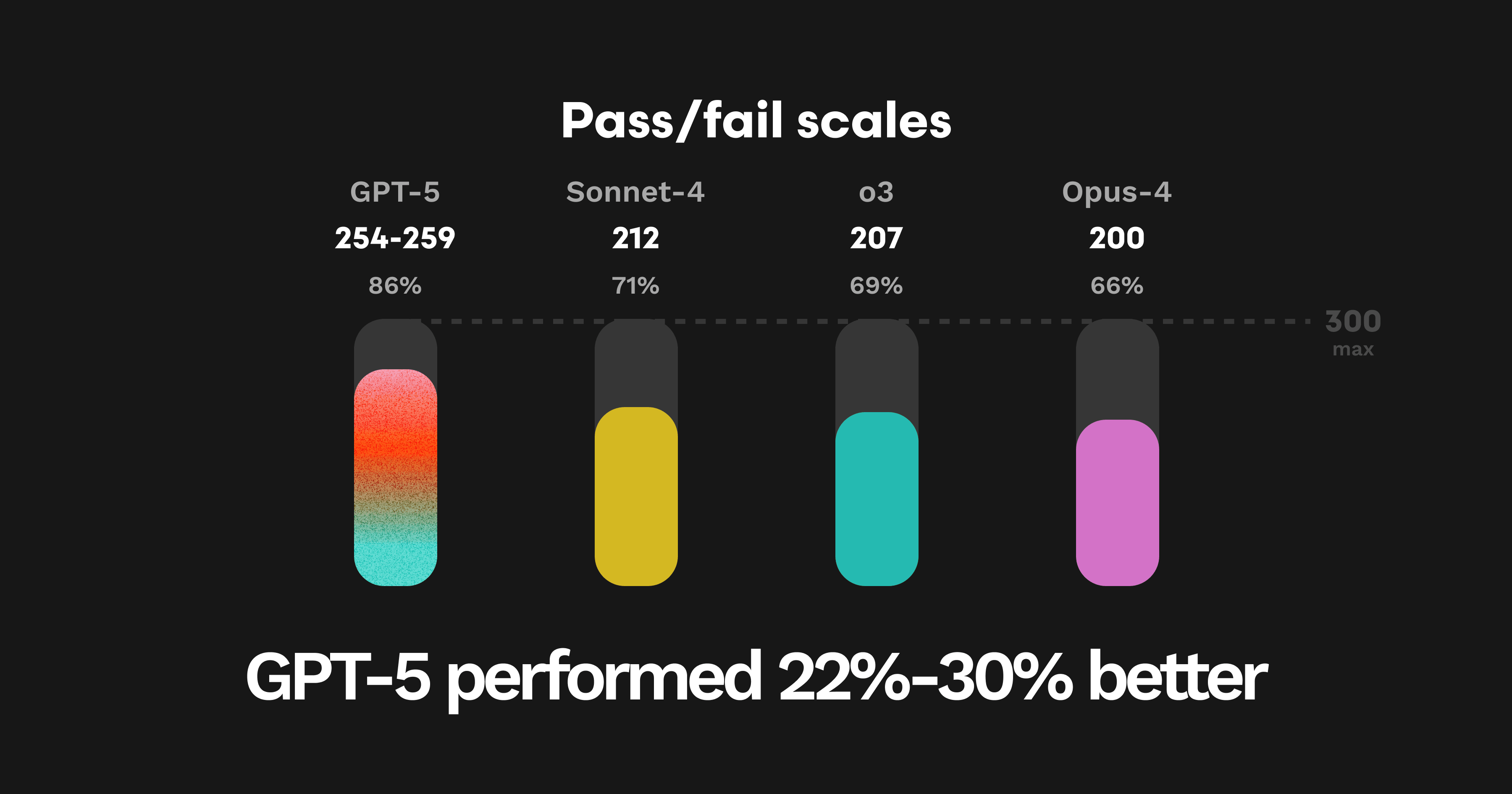
GPT-5:254〜259
Sonnet-4:212
O3:207
Opus-4:200
下位約100件のPRはあらゆるモデルが発見します。そのため最も難しい200のエラーパターンに絞って見ると、GPT-5はそれらの78%を検出し、他モデルは54%から58%にとどまるという、さらに大きな差が見られます。
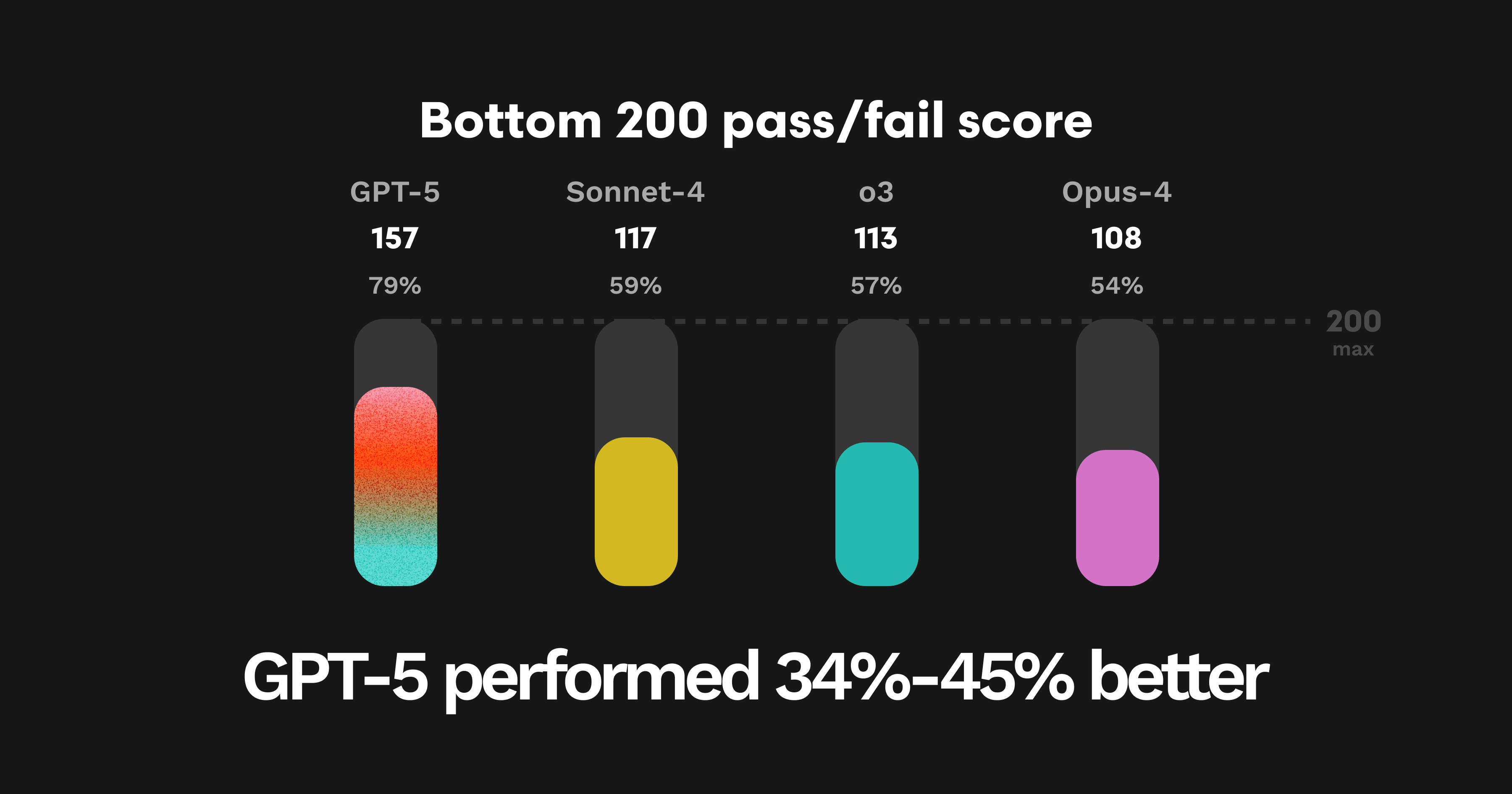
GPT-5:157
Sonnet-4:117
O3:113
Opus-4:108
要点:包括指標と同様に、GPT-5が追加で見つけられたエラーパターンは、並行性バグや環境間でのドメインキー不整合のように、LLMにとって特に見つけにくい問題です。これはモデルの推論能力が高まっていることを示唆します。
各モデルをストレステストするために、当社はGolden PR Datasetから最も難しいプルリクエスト25件を厳選しました。これらのPRは以下のような実世界のバグを網羅します。
並行性問題(TOCTOU競合、不適切な同期など)
オブジェクト指向設計の欠陥(仮想呼び出しの落とし穴、参照カウントメモリモデルの違反など)
パフォーマンス上の危険(キャッシュが際限なく成長する、タイトループによるスタールなど)
言語特有の落とし穴(TypeScriptの誤用、C++のメモリオーダーの微妙さなど)
各モデルは三回ずつ実行し、以下はこのHard 25ベンチマークにおける平均合格率です。
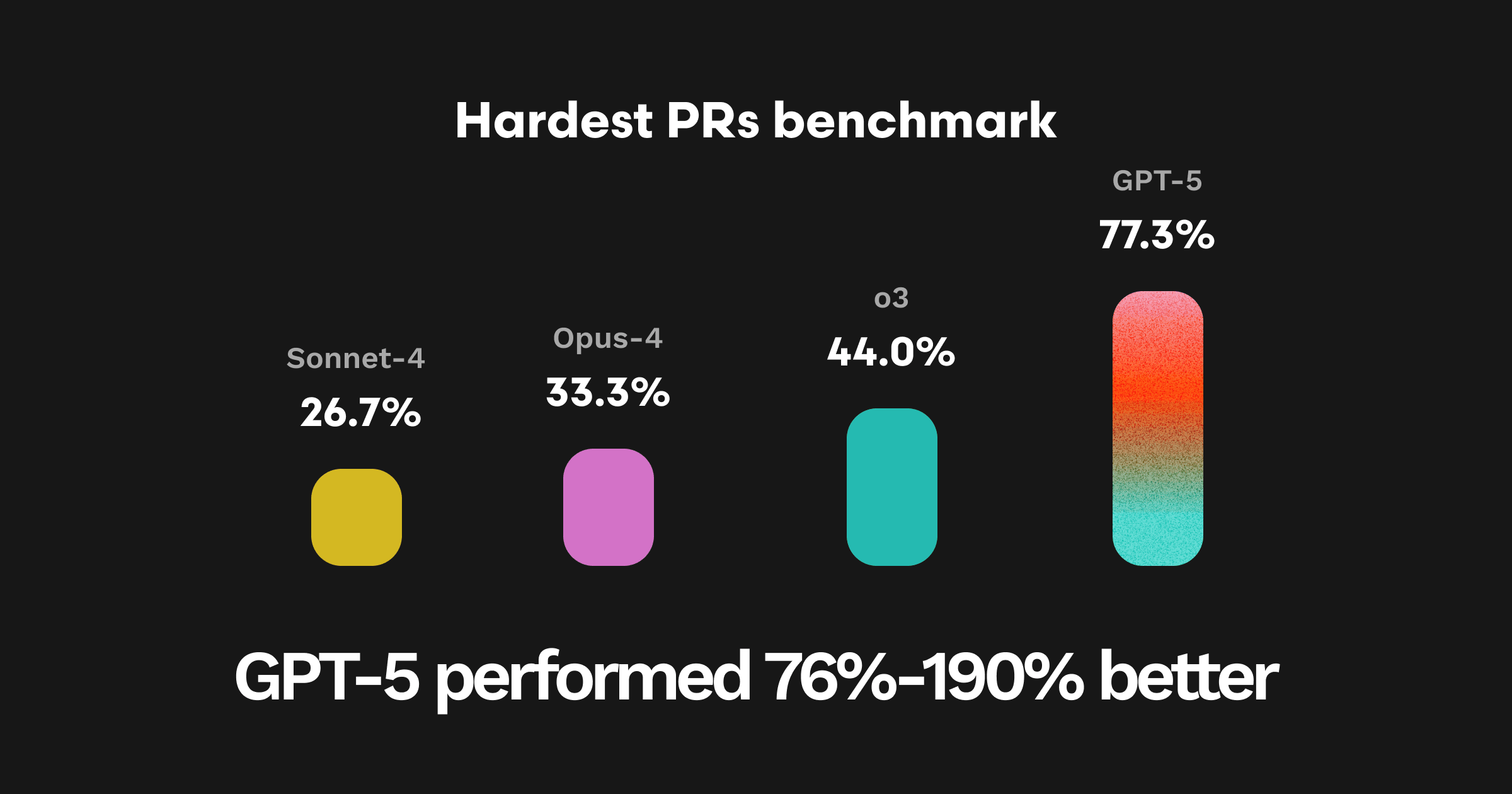
| モデル | 平均合格率 (%) |
| Sonnet-4 | 26.7% |
| Opus-4 | 33.3% |
| O3 | 44.0% |
| GPT-5 | 77.3% |
要点:GPT-5は正確性、コンテキストの連関、深さが最も重要な場面で真価を発揮します。これまでにテストしたすべてのモデルの中で、最も完全で、テスト準備が整い、将来の変更にも耐えうるコードレビュー出力を一貫して提供します。
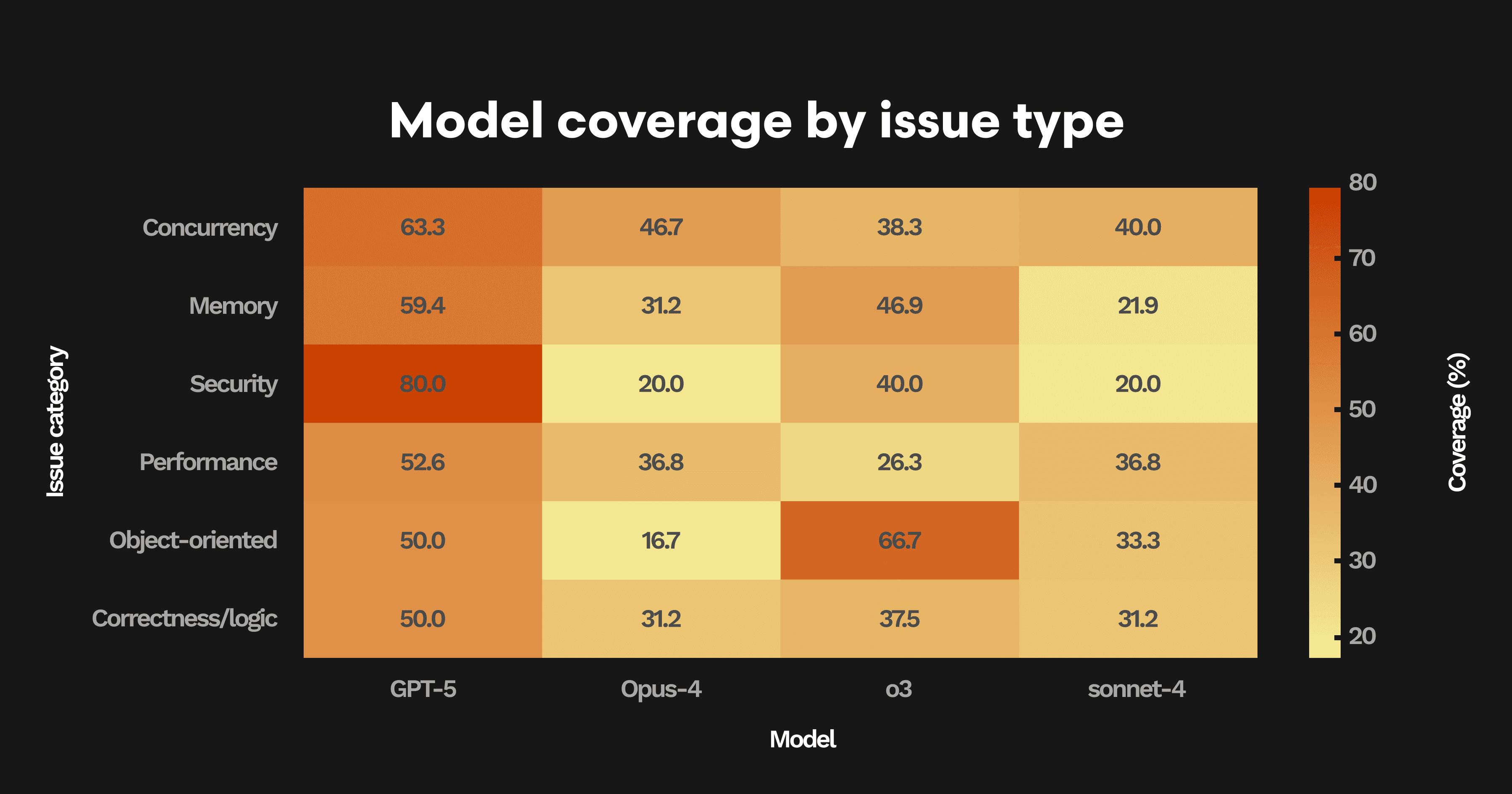
各モデルがいくつではなくどのような種類の問題を特定するのかをより良く理解するために、当社チームは難易度の高いPR群のすべてのコメントをレビューし、並行性、セキュリティ、オブジェクト指向設計といったカテゴリに分類しました。
モデル間での重複排除を適用しました。複数モデルが同一の本質的問題を指摘した場合は、表現が異なっていてもPRごとに一回のみカウントしました。これにより、コメントの多さではなく、問題の網羅性を測定できるようにしています。
その上で各モデルについて、そうしたユニークな問題のうち何パーセントを捉えられたかを集計しました。
GPT-5はほぼすべてのカテゴリで先行しており、並行性、パフォーマンス、メモリ関連のバグの60%以上を特定し、さらにセキュリティ問題の 80% を検出するという顕著な結果を示しました
セキュリティが最も際立つ差分です。GPT-5はセキュリティ関連のバグの80%を発見した一方、次点のモデルであるO3は40%にとどまりました
基本的な並行性やパフォーマンスの問題においても、GPT-5は常に20〜30ポイント上回ります
このプルリクエストでは、シングルトンサービスクラス内のダブルチェックロッキングと共有HashMapへの安全でないアクセスの組み合わせに起因する微妙な並行性バグがありました。多くのモデルが明白なスレッドセーフティの問題を指摘した一方で、GPT-5は症状だけでなく、その背後にあるアーキテクチャ上の欠陥まで解消する包括的で本番対応可能な修正を提案しました。
OrderServiceシングルトンは注文を格納するためにHashMapを使用し、固定スレッドプールから並行更新が行われています。この設計には同期がなく、データ破損の可能性がありました。さらに、シングルトンは非volatileな静的フィールドを用いて初期化されており、安全でない公開や部分的に構築されたオブジェクトが生じる可能性がありました。
GPT-5は基本的な修正を越えて、完全な並行性強化計画をまとめ上げました。
- private final Map<String, Order> orders = new HashMap<>();
+ private final Map<String, Order> orders = new ConcurrentHashMap<>();
✅ GPT-5はその理由も説明しました。「コンカレントな更新がプレーンなHashMap上で実行されており、これはスレッドセーフではないため未定義の動作につながる可能性があるためです」
- private static OrderService instance;
+ private static volatile OrderService instance;
または次の方法でも可能です。
private static class Holder {
private static final OrderService INSTANCE = new OrderService();
}
public static OrderService getInstance() {
return Holder.INSTANCE;
}
✅ GPT-5はダブルチェックロッキングに伴う古典的なメモリ可視性の問題を指摘し、構築をスレッドセーフにするための代替パターンを提案しました。
// Inside OrderService.java
void clearAllForTest() {
orders.clear();
}
✅ 共有シングルトンを複数のテストケースで扱う際に、テストの分離性と再現性を確保できます。
- future.get(); // Wait for completion
+ assertTimeoutPreemptively(Duration.ofSeconds(5), () -> future.get());
✅ GPT-5は非同期フローにおけるテストの不安定化を防ぐためのガードを追加し、テストスイートを積極的に堅牢化しました。
両モデルとも同期されていないHashMapを正しく指摘し、ConcurrentHashMapへの置き換えを提案しました。しかし、いずれも完全で本番対応可能な是正には至りませんでした。
❌ シングルトンの問題が未解決 Sonnet-4は壊れたダブルチェックロッキングを無視しました。Opus-4は言及しましたが実際の修正を行わず、volatile指定やホルダーイディオムがありませんでした
❌ テストの安全性に関する対策がない GPT-5はclearAllForTest()とタイムアウトガードを導入しましたが、Sonnet-4とOpus-4はいずれもこれらを完全には取り入れていないか、言及があっても受動的にとどまりました
❌ アーキテクチャ的な文脈が不足 両モデルとも広範なコードベースの関連範囲を突き合わせたり、変更の根拠を示したりしていませんでした。GPT-5はサービス、テスト、スレッド動作にわたる根拠をもって修正を裏付けました
❌ 対応範囲が限定的 Sonnet-4は表面的な単一修正にとどまり、Opus-4は有用なロギングを追加したものの、GPT-5が完全に対処したより深い構造的なリスクを見逃しました
GPT-5のレビューの真価はその深さと認識にあります。GPT-5は目に見える競合状態の修正にとどまらず、以下を実現しました。
より深いアーキテクチャリスクの特定
テストの信頼性とコード品質のクロスリファレンス
すぐにマージ可能な安全な変更の提示
これは単なる修正ではなく、エンジニアリングの洞察です。 GPT-5は、AIレビュアーがシステム層をまたいで推論し、持続的な解決策を提案し、チームがより安全なコードを少ない手探りで書けるよう支援できることを示しました。

メトリクスや本評価で対象にした特定の事象を超えて、GPT-5は新しい振る舞いや推論パターンを示しました。
高度なコンテキスト推論:GPT-5は入力に厳密に拘束されるロジックではなく、複数のレビュー手順を先回りして計画する広範な創造的推論を示しています。例えば、並行性に関するテストでの「チェック後実行の競合」シナリオでは、コードベースのファイル間の証拠を結び付ける深い推論を示しました。重複作成のリスクを検出した唯一のモデルであり、列挙型やテストスイートに基づいたアトミックな返金パターンを導入しています。
レビュースレッドを通じた段階的推論:コンストラクタ内の仮想呼び出しに焦点を当てたオブジェクト指向のテストでは、GPT-5はまず誤用されたポリモーフィックなオーバーライドを特定し、その後で自らの先の提案に基づいて推奨を調整するという層状のロジックを示しました。これは一つを特定した後に、後続で追加の推論を示す層状のロジックを表しています。
証拠に基づく差分の正当化:上限のないキャッシュ成長というパフォーマンス問題に焦点を当てたテストでは、GPT-5は他モデルが見逃したアーキテクチャ上のメモリリスクを特定し、差分の文脈、使用パターン、推奨されるセーフガードを根拠として示しました。
先を見据えた提案:同期プリミティブの誤用に焦点を当てた並行性関連のテストでは、GPT-5は競合を修正しただけでなく、将来の機能追加のための構成方法、ロック階層、回帰を防ぐためのテストガードレールも提案しました。
粒度の細かいタスク指向の提案:以前のモデルと異なり、GPT-5は明確なフォローアップタスクを詳細に示し、レビュー過程の中に実行可能なワークフローを作り込みました。これにより多段のワークフローにより適したモデルとなっています。
GPT-5は、詳細さ、正確さ、コンテキストに基づく推論の面でAIによるコードレビューを大きく前進させる重要な成果だと、私たちは考えています。だからこそ、本日から当社のパイプラインの中核となる推論モデルとしてGPT-5を採用します。これにより、より多くの問題を発見し、より深くコンテキストに富んだレビューを提供できるようになると期待しています。
CodeRabbitをまだ試したことがない方、以前に試して現在は利用していない方、そして現在のユーザーの方まで、GPT-5がレビュー品質や体験をどのように向上させているかについてご意見をお聞かせください。
今すぐ 14日間無料トライアルをお試しください GPT-5の威力をご自身で体感してください。



