Rising outages: What the data tells us
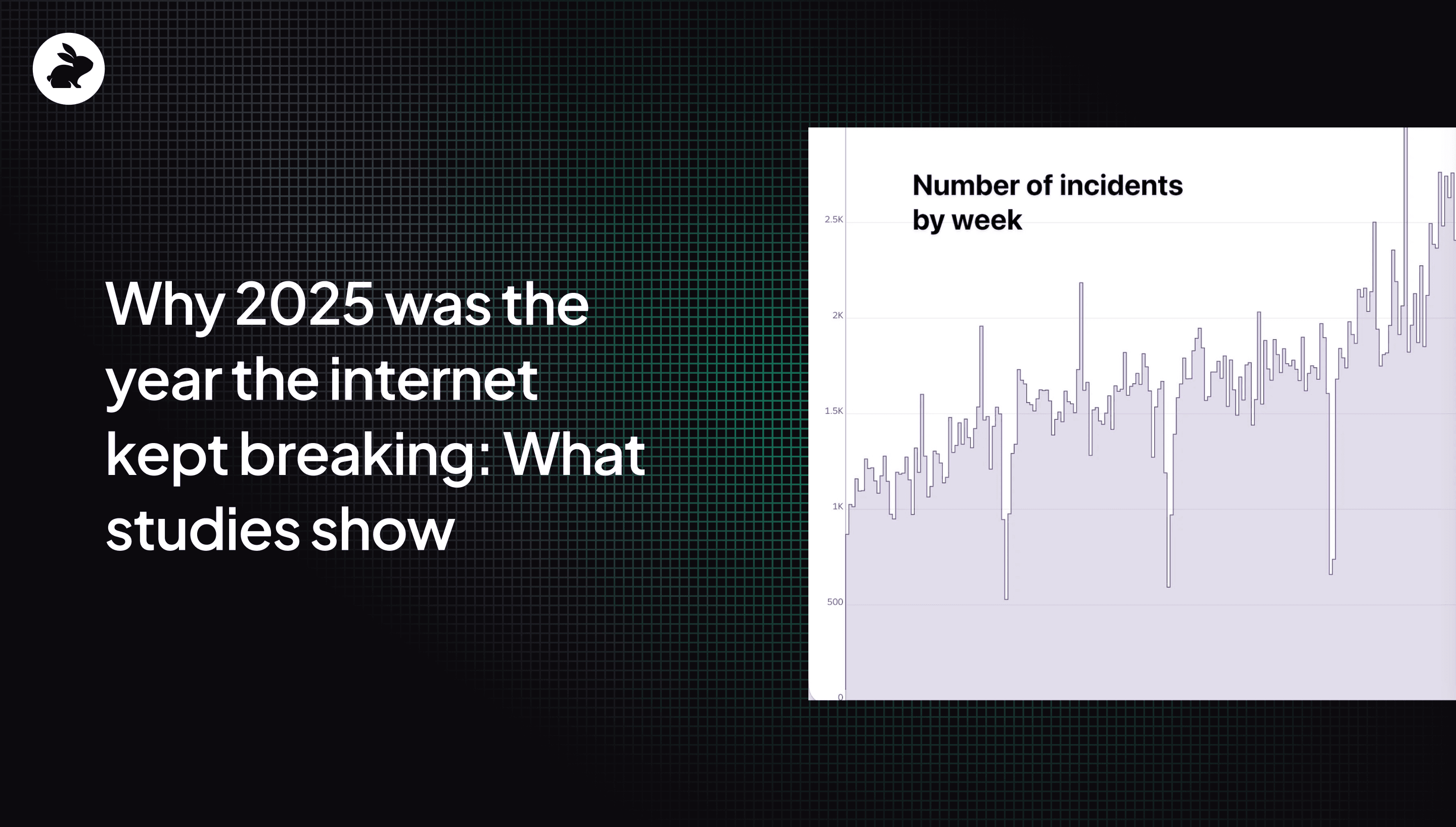
In October, the founder of www.IsDown.app went on Reddit to share some disturbing charts. His website, an authoritative source on whether a website is down or not, has been tracking outages since 2022. And he had a frightening statistic: there are a lot more outages in 2025 than there have been in past years. And the number of outages has been increasing since 2022.
In his posts, he talked through things that might be causing this trend. AI code came up repeatedly, though some contributors also suggested it could be caused by offshoring or laying too many developers off. What’s clear is that bugs got through more frequently in 2025 than in past years and that’s leading to expensive downtime for all involved.
His site’s data tracks with what multiple studies and surveys are finding:
A survey of over 1,000 CIOs, CSOs and network engineers across multiple countries found that 84% of businesses reported rising network outages over recent years and more than half of them saw a 10-24% increase over a two-year timeframe.
The ThousandEyes blog reported global outage counts increasing from 1,382 in January 2025, to 1,595 in February (+15 %), to 2,110 in March (+32 %) before tailing off somewhat to 1,843 in May, a volatile pattern of upward pressure.
So, what’s really causing this spike in outages and what can we do about it as developers?
A billion dollar outage… and companies looking for a solution
When the mighty fall, they take a lot of other companies with them. When AWS went down earlier this year, websites froze. Payments were declined. Even worse, Fortnite games were interrupted. In the aftermath of the outage, people have tried to estimate just how much economic activity evaporated with the functionality of US-EAST-1.
Amazon once claimed that even a few milliseconds difference in latency would cost them tens of millions of dollars. So, what did a multi-hour outage do for the online retailer and all the companies it hosts? Forbes estimates that billions were lost with one CEO it quoted suggesting that losses could even reach into the hundreds of billions.
Multi-cloud quickly emerged as the new/old buzzword and companies are grappling with how to manage the risk of relying too heavily on one database provider. But even if you migrate to a multi-cloud environment, your payment processor might still be on the receiving end of an outage and put a spanner in your revenue just the same. Or your operations might be taken down by a bug of your own.
A far better fix would be for us to figure out as an industry how to reverse the trend line that’s seeing downtime and incidents steadily increasing. Because something is causing those increased incidents and it’s entirely in our power as an industry to reverse that trend.
How AI, code quality & bugs fit into the picture

So, what’s contributing to these trends? It’s likely what everyone immediately thinks about when they hear incidents are increasing: the problem is AI-generated code. That’s because we’ve all found, by this point, a veritable motherload of bugs in AI-generated code that we’re certain a human engineer wouldn’t have introduced on their own.
And this isn’t just anecdotal. The data overwhelmingly supports it too:
Our recent State of AI vs. Human Code Generation Report found that AI code has 1.7x more issues and bugs in it. And what’s more, it found an increased number of issues and bugs in areas that could lead to incidents like Logic and Correctness issues (this category had the largest number of issues) and security issues (1.5x to 2x higher).
A large-scale academic study titled “Human-Written vs. AI-Generated Code: A Large-Scale Study of Defects, Vulnerabilities and Complexity” (Aug 2025) compared over half a million Python and Java samples written by humans vs. by LLMs. The findings: AI-generated code tends to include more high-risk vulnerabilities.
What this means for outages and incidents

Pulling this together, the data clearly shows overall incident and outage frequency is trending upward. As teams lean more heavily on AI-generated or AI-augmented code, they are exposing themselves to new classes of risk: more latent vulnerabilities, reduced visibility of what’s been generated, and more pressure on existing QA/test/review workflows that may not have been enhanced to compensate for the speed of code generation and deployment.
In short, the combination of faster delivery, heavier reliance on AI, plus less-mature processes in many teams = a higher probability that “something will go wrong.”
The call is coming from inside the house: We should stop treating outages as anomalies
As the data clearly shows, the problem is structural but, as developers, we are conditioned to see each incident as a separate event. Here’s the problem with that approach though: if you treat every outage as a one-off event that happened to some other team, you’ll miss the broader pattern. Change failure rates, environment complexity, and toolchain fragility are all increasing. When you overlay the growing use of AI-generated code, the risk footprint changes.
The root of reliability increasingly rests not just on infrastructure, but on how we build, review, test, deploy and operate software, and how we integrate AI into that chain without weakening it.
What a big outage like AWS’ camouflages is that the issue isn’t just third party providers, the call is also coming from inside the house. And inside all the houses of all the companies that power your stack.
What to do about it as an industry (Spoiler: This is not a pitch)
This is where a company would typically make their pitch about how, if only AWS had used their product, the outage would never have happened. Billions would not have been lost and everyone would have continued on their day like it was an ordinary Monday.
But here’s why it won’t help anyone for us to focus on that: you can’t fix a massive structural problem with a new tool alone. And this is indeed a structural problem.
In July, we wrote about what we saw as a worrying trend. Companies were starting to make claims about what percentage of their code was AI-generated as though that was a valuable metric to measure. Google and Microsoft both claimed that 30% of their new code was being generated by AI.
At the time, we wrote: “A metric based purely on volume… doesn’t tell you how much developer time was needed to debug or review the AI-generated code. Without these nuances, a 30% metric means almost nothing about actual efficiency or quality outcomes.”
Our suggestion then was that companies shift focus from this approach that sees all code generated by AI as a good thing and look at AI usage and adoption more holistically including by relying on metrics that:
Are developed in collaboration with engineers who understand day-to-day workflows.
Align with real productivity and business outcomes, not superficial adoption targets.
Encourage flexible, context-aware experimentation rather than rigid enforcement.
That could be things like holistic metrics that look at how much time developers spend coding with AI versus how much time they spend debugging or it could be as simple as tracking how many incidents you have and their severity and costs as you increase use of AI on your team.
These rules are more likely to lead to holistic metrics that look at both the productivity benefit in increased code generation speed but its downsides so companies can better understand the full impact and ROI of AI usage.
Ways to de-risk AI adoption
So, what does that mean for AI usage? Most teams have now integrated them into their workflows in ways that benefit them. And the problem might not be AI coding tools themselves but HOW some companies have chosen to adopt them.
Many teams are being told they need to use AI to write more code with a goal of increased productivity and then they’re just handed a tool and nothing more. That’s an adoption process designed to make incidents skyrocket.
Here are some common sense ways we all need to start thinking about AI coding tool adoption:
Properly resource review and QA teams
When AI coding tools are advertised as ways to reduce developer time (and developers) it’s not surprising decision makers make the mistake of thinking they can cut teams now that AI is helping. But that doesn’t address the downstream effects of AI generated code. One of the most overlooked consequences of adopting AI-assisted coding tools is the sheer increase in code volume they create.
Developers can now spin up entire modules in minutes. That speed feels like productivity, but it also means that review and QA pipelines are being overwhelmed. When the number of pull requests doubles but the number of reviewers stays the same, even the best processes begin to fray.
To de-risk AI development at scale, organizations need to staff and support review, QA, and testing functions proportionally to the new pace of code generation. That could include AI tools that help with the review and QA work.
Know what to look for
Until recently, we knew that AI introduced more bugs and issues but we didn’t know what kinds of bugs and issues it introduced most often. Now, with our State of AI vs. Human Code Generation Report, we have those answers. AI, for example, is 2.25x more likely to create algorithmic and business logic errors and 2.29x more likely to have incorrect concurrency control issues. Things like misconfiguration, error and exception handling, and incorrect dependencies are nearly 2x more prevalent as well. Our report is helpful for creating a checklist of what to double check relevant PRs for to make sure fewer of these bugs slip through. .
Shift testing and reviews left
AI-assisted code introduces a new kind of complexity: it often looks correct, compiles cleanly, and passes superficial checks but hides subtle logical or edge-case errors that only surface under specific conditions.
To mitigate this, organizations need to shift testing and reviews as far upstream as possible. Rather than treating QA as a final gate, testing must become a living part of the development loop itself. This means integrating automated unit, integration, and property-based testing directly into the AI generation workflow, sometimes referred to as continuous verification. Every code suggestion from an AI assistant should trigger lightweight checks before it even reaches a human reviewer. You can also conduct reviews in your IDE or CLI environments to catch bugs and potential issues before creating a pull request.
Then, AI-generated pull requests should be automatically flagged and routed through more rigorous review protocols, including additional static analysis, dependency scanning, and peer oversight. Reviewers should know when a piece of code was generated versus hand-written, not as a stigma, but as a signal that it may need a deeper pass. Some companies are already labeling AI-authored commits or requiring an “AI provenance” tag in the PR description. Other companies are also forbidding the use of AI to write certain kinds of code that are critical for security.
Expand chaos and resilience testing
Traditional testing assumes predictable behavior but AI-assisted systems are increasingly unpredictable. Code generated by large language models can fail in non-obvious ways: mishandling unexpected inputs, producing inconsistent API calls, or creating hidden performance bottlenecks that only reveal themselves under load.
That’s why many engineering teams are expanding chaos and resilience testing beyond infrastructure to encompass the application layer itself. By running failure-injection experiments in staging environments such as intentionally breaking components, throttling dependencies, or introducing malformed data, teams can observe how AI-generated logic behaves under stress.
These simulations expose weak assumptions baked into AI-generated code that standard test suites often miss. Pairing chaos testing with automated rollback mechanisms, canary deployments, and progressive delivery ensures that when things do go wrong, the blast radius is small and recoverable.
Integrate AI literacy and secure-coding training
Don’t assume developers instinctively know how to use AI safely. The tools may feel intuitive (type a prompt, get working code) but beneath that simplicity lies a set of entirely new failure modes that most engineers were never trained to anticipate.
That means providing regular, hands-on training on topics like prompt design, model limitations, and the systemic ways AI-generated code can go wrong. Developers should learn to spot signs of hallucinated functions (calls to APIs that don’t exist), insecure defaults (improper authentication or data handling), and non-deterministic behavior that can make debugging far more complex. They should also understand what the model doesn’t know, including its knowledge cutoff, its lack of situational awareness, and its tendency to optimize for plausibility rather than truth.
A team that understands how generative tools fail is far less likely to trust them blindly… and far more likely to catch issues before they end up in production.
We can turn this around in 2026 (yes, there’s hope)
The lesson of 2025’s rising incident curve is clear: you can’t automate your way out of accountability. If AI is going to write more code, humans need the time, tools, and headcount to review more code. Otherwise, every efficiency gain on the input side becomes a liability on the output side. Which is something we’re currently seeing writ large as an industry.
The goal shouldn’t just be to adopt AI but to adopt it in ways that actually help companies. What we’re seeing now in the increased level of incidents is false velocity: the illusion of progress that hides compounding defects. But that illusion can be corrected. Teams that invest in thoughtful testing, resilient review processes, and a culture of ownership can still realize AI’s potential without paying the price in downtime.
And the more teams that do that, the less downtime and incidents we’ll see industry-wide.
Curious how CodeRabbit could help? Read our case study on how we helped Clerk or try our AI reviews today.