

Atsushi Nakatsugawa
May 29, 2025
2 min read
May 29, 2025
2 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Pipeline AI vs. agentic AI for code reviews | AI architecture patternsの意訳です。
AIはコードレビューのあり方を大きく変えました。
従来の静的ルールや正規表現ベースのLinterから、差分を読み取り、まるでシニアエンジニアのようなフィードバックを返すシステムへと進化してきました。これは確かな前進です。
しかし、CodeRabbitのように本番環境で使えるAIレビューシステムを開発する中で、私たちはある根本的な設計の選択肢に直面します。
AIにエージェントのような自律性を持たせるべきか?それとも、構造化されたPipelineとして制御するべきか?
この選択は実装の問題だけではありません。システムの処理速度、開発者の信頼性、バグ時のデバッグしやすさ、長期的な運用コストにまで影響します。
ただし、設計が最終目的ではありません。これらはすべて、ある本質的な問いに答えるための手段に過ぎません。
「最高のコードレビューを実現するために、モデルに必要なものだけを、的確に渡すにはどうすればいいか?」
問題は「エージェント型か、パイプライン型か」ではなく、「現場で役立つ、最高のツールをどう作るか」です。
まずは、それぞれのアーキテクチャについて整理しましょう。
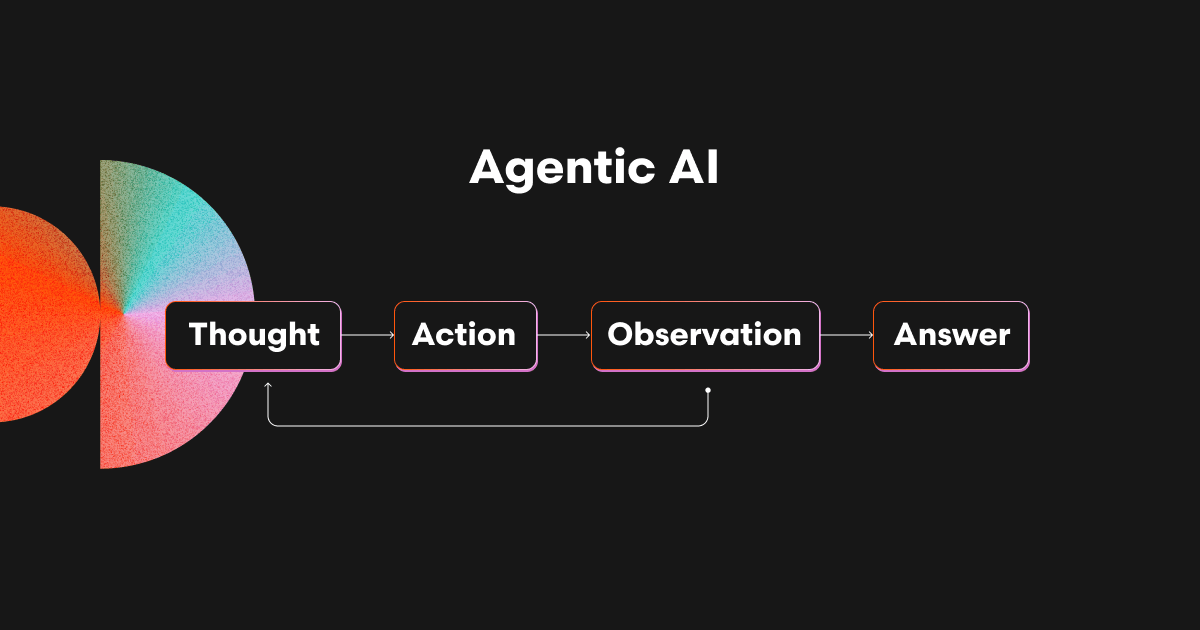
エージェント型の構成では、AIは1つのプロンプトに縛られず、ステップごとに考え、判断し、ツールを使いながら進行します。典型的なプロセスは以下の通り:
行動計画の立案
ツールの実行(例:grep、静的解析ツール、テストランナーなど)
出力の観察
次に何をすべきかを判断
このプロセスは ReAct(Reason + Act) というアプローチに基づいており、多くの研究やシステムに使われています。
モデルが外部ツールやメモリを活用して出力を豊かにできるのは大きな魅力ですが、それを正確に制御するのは非常に難しいのです。
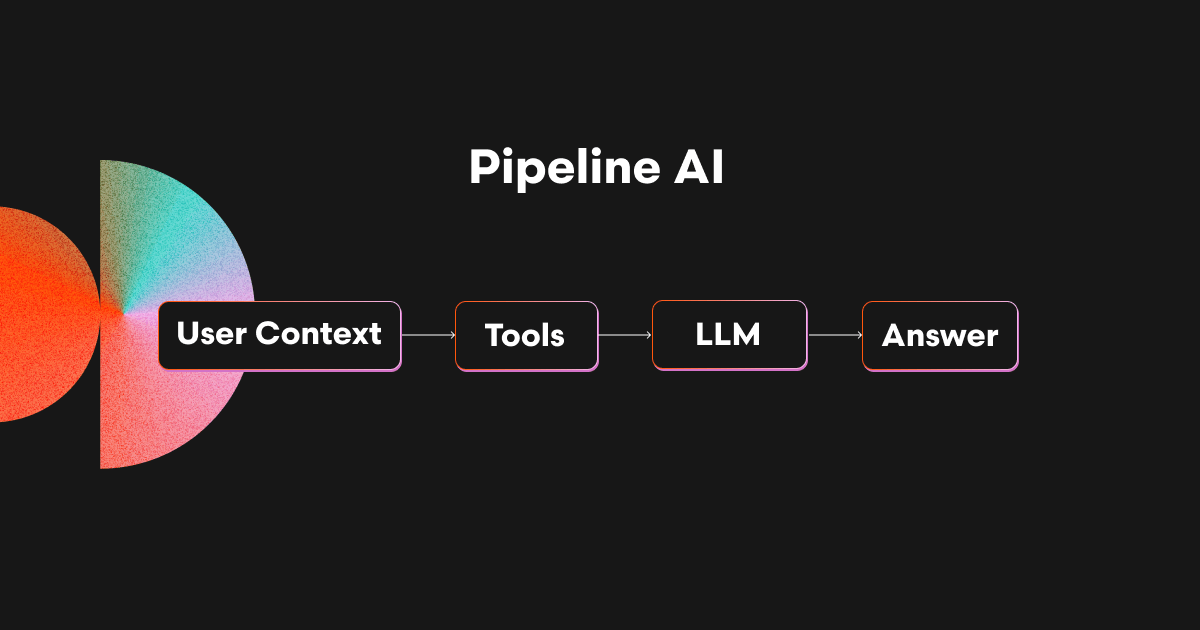
パイプライン型は、より決定論的(predictable)なアプローチです。以下のような一連のステップを定義します:
入力の準備(例:diff、関連ファイル、Issue内容など)
前処理(例:静的解析、コード検索)
モデルへのプロンプト送信
出力をレビューコメントとして整形
この構成は高速でテストしやすく、CIなどのワークフローにも組み込みやすいのが利点です。
ただし最近の多くのツールでは、パイプライン型をベースにしつつ、プロンプトの動的調整や文脈取得、対話型のフローなど、エージェント的要素も一部取り入れています。
つまり、ほとんどの現実的なシステムは、どちらか一方ではなく、その中間に位置しているのです。

実際のところ、現場で使われている多くのAIシステムは完全にエージェント型でもパイプライン型でもありません。その中間に位置し、両者の利点を活かすハイブリッド型を採用しています。
CodeRabbit や GitHub Copilot PR Reviews はその代表例です。
こうしたハイブリッド型では、パイプラインの再現性・安定性と、エージェント的な柔軟な文脈取得や動的挙動を組み合わせ、実用的なバランスを取っています。
| 観点 | エージェント型 | パイプライン型 |
| レイテンシ | ステップが多く遅くなりがち | 高速で予測可能 |
| ツールの使い方 | 柔軟で動的 | 一貫性があり安定 |
| 信頼性 | テストしにくく不確実性が高い | デバッグしやすく再現性が高い |
| 文脈の扱い | 動的で柔軟だがミスしやすい | 事前に定義・制御された入力 |
| ワークフロー適性 | 対話的なツール向け | CI/CDやPRレビューに最適 |
コードレビューAIで最も重要なのは、どのように設計するかではなく、どんな文脈を与えるかです。
ありがちな誤解として、「コードやメタ情報をもっと渡せば精度が上がるだろう」と考えがちですが、実際は逆効果になることもあります。
無関係な情報が多すぎるとモデルが混乱する
プロンプトのノイズで誤検出が増える
質の低い文脈がツール経由で生成される可能性もある
つまり、「多いほうが良い」ではなく、「適切なものだけを渡す」のが正解です。
CodeRabbitでは以下のような構成を採用しています:
モデルの実行前に30種類以上の静的解析ツールを実行
ASTやシンボル情報をもとに文脈を抽出
過去のレビュー結果を活かしたフィルタリング
モデルの入力制限を考慮して、構造化されたプロンプトを生成
これにより、「必要な情報だけを、正しく渡す」構成を実現しています。
理想的には、AIが自ら「どの文脈が役立つか」を学び、適切にツールを使えるようになるべきです。
そのためには:
理想的なPRと文脈のデータセット
評価指標と結果の紐付け
効果的なツール使用のシミュレーション
などが必要です。
実際に ReTool や LeReT のように、強化学習でツール選択を学習させる研究も進んでおり、精度や効率の向上が報告されています。
CodeRabbitでも、こうした文脈選択における次の一手に注力しており、より賢く、信頼できるレビューAIの構築を目指しています。
エージェント型かパイプライン型かという話は、本質ではありません。大事なのは、**「モデルに必要なものを、必要なだけ、正しく渡すこと」**です。
パイプラインはスピードと安定性。エージェント型は柔軟性と思考力。そして、CodeRabbitが採用するハイブリッド型はその中間で最適なバランスを目指しています。
でも最も大事なのはやはり文脈です。
どこを見て、何を無視し、何を重視するべきか。それを人間のエンジニアのようにモデルが判断できたとき、私たちは本当に信頼できるAIレビューを手にすることができるでしょう。
最高のエンジニアが最高のパフォーマンスを出しているかのようなレビュー——それを、毎回、自動で届けられる世界へ。
私たちは、そこを目指しています。
CodeRabbitを試してみたい方は、14日間の無料トライアルからお試しください!



