

Atsushi Nakatsugawa
November 24, 2025
3 min read
November 24, 2025
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
Opus 4.5 for code-related tasks: Performs like the system architectの意訳です。
新しいモデルが登場するとき、その約束はいつも同じです。より賢い推論、よりきれいなコード、そしてよりよい回答。しかし Anthropic の Opus 4.5 は、単に推論するだけではなく、監査する モデルです。あたかも自ら設計に携わったシステムに戻ってきたかのようにコードを読み込み、弱点を特定し、アーキテクチャ全体を整えます。他のモデルが論理を説明したり、局所的な修正を示したりするのに対し、Opus 4.5 は技術文書に近い、構造的で体系的なレビューを行います。
私たちはこのモデルの特徴を把握するために、Opus 4.5 を CodeRabbit のベンチマーク環境に統合しました。その結果わかったのは、より高い知能でも派手な文章でもなく、「規律」でした。Opus 4.5 は単にバグを見つけるのではなく、その周囲にある 文脈を構築 します。つまり、レビューを推測ゲームではなくエンジニアリングプロセスとして扱うのです。


CodeRabbit では、新しい LLM を評価するために、C++、Java、Python、TypeScript にまたがる既知のエラーパターン(EP)を含む 25 件の複雑なプルリクエスト を用意しています。モデルが生成した各コメントを LLM ジャッジが次の3つの観点で評価します。
Precision(精度): EP を正しく特定しているか。
Important-share(重要コメント率): コメントのうち重要・重大な指摘(本物のバグ)がどれだけ占めるか。
Signal-to-noise ratio(S/N比): 重要コメントと、重要でないコメントの比率。
この評価フレームワークは、複数世代のモデルを通じて改善されており、自動判定の LLM と 人手による検証 を組み合わせて正確性を担保しています。また、複数ジャッジによる評価と繰り返し試行 を実施することで、一貫性とばらつきを記録しています。プロンプト改善、ラベル精度向上、評価範囲の拡大を継続的に進め、より信頼できる結果を得られるようにしています。
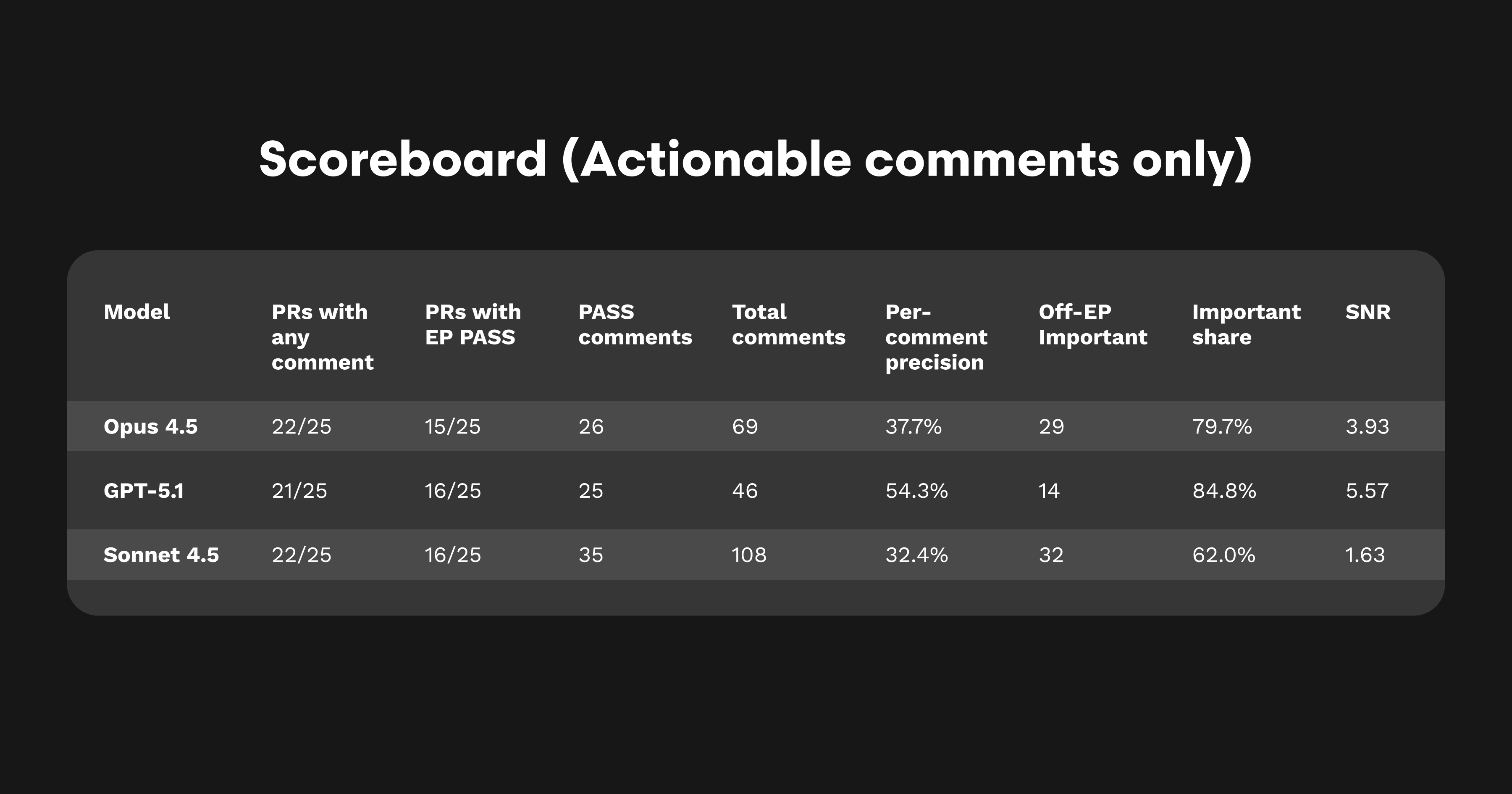
解釈:
Opus 4.5 は、Sonnet 4.5 の高ボリューム・冗長スタイルと、GPT-5.1 のシャープで精密なスタイルの中間に位置します。Sonnet 4.5 よりもコメントあたりの精度が高く、有意味な指摘の割合が多い結果となりました。EP パス数は 1 件少ない(15 vs. 16)ものの、これは通常のばらつき範囲に収まっています。実際、複数回のベンチマークでは Opus 4.5 が GPT-5.1 や Sonnet 4.5 を上回ることもありました。
総合すると、Opus 4.5 はシグナル、構造、カバレッジのバランスがよく、安定して信頼できるモデルと言えます。
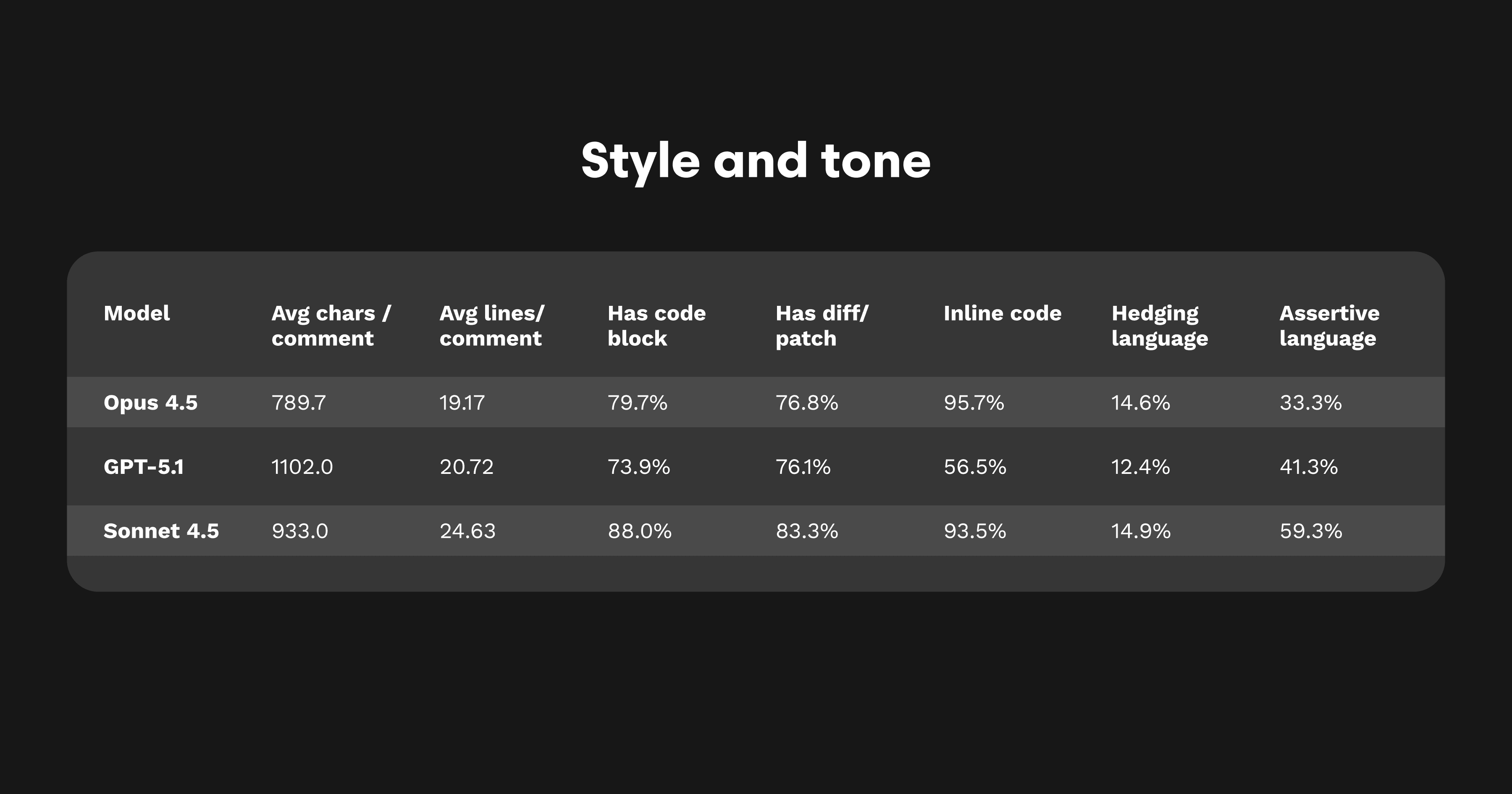
Opus 4.5 のレビューは、構造化され、簡潔で、焦点が明確です。断定表現の比率は約33%、婉曲表現は約15%と、落ち着いたプロフェッショナルなトーンになっています。密度とトーンのバランスによって、実践的で自信のある分析的な内容となっています。コードブロックや diff など、行動につながる表現を多用する傾向があり、「説明する」よりも「編集する」モデルだと言えます。

Opus 4.5 のコメントは、見出し、理由説明、diff というアーキテクチャ的なリズムで書かれています。約80%のコメントにコードブロックが含まれ、ほとんどのコメントが簡潔なパッチで締めくくられます。原因、影響、解決策が整然と記述されており、明確なバグレポートのようです。
この構造はどの言語でも維持されます。C++、Java、Python、TypeScript のいずれでも、コメントは平均19行・790文字程度に収まり、統一されたスタイルとなります。一貫性があることで自動化との相性が良く、読みやすさも向上します。まるでコードベース全体を同じエンジニアがレビューしているかのようです。
具体例:
C++(WorkerThreadPool): lost wakeup レースを3ステップのインターリーブで説明し、1行の修正 diff を提示します。
Java(OrderService): ダブルチェックロッキングで volatile が欠落している点を指摘し、正しいパターンを提示します。
Python(Batch Client): 同期 HTTP クライアントを非同期版に置き換えてブロッキングを防ぎます。
TypeScript(Cache Manager): Number.MAX_SAFE_INTEGER がエビクションを無効化している点を指摘し、現実的なデフォルト値を提案します。
いずれも簡潔でコードネイティブな洞察であり、根拠に基づいた実用的な修正です。
Opus 4.5 のトーンは全体的にバランスが良いのですが、間違っているときにやや断定的に聞こえるという、ささやかな逆転現象があります。通常は慎重ですが、この癖があるため、コメントのトーンだけで正確性を判断しないようにしています。この問題を補うため、評価サマリーではトーンデータと正解率を組み合わせて校正を行っています。
とはいえ、Opus 4.5 はほとんど推測をせず、間違っているときでさえ淡々と説明します。
多くのモデルが目の前の欠陥に集中するのに対し、Opus 4.5 は周辺のシステム全体を考慮します。推奨内容には、ライフサイクル改善、安全チェック追加、デフォルト値の見直しといった、より上位の修正が頻繁に含まれます。
例:
TypeScript Cache: エビクションロジックの再設計、TTL の強制、デフォルト改善により秘められた OOM(Out Of Memory ) を防ぎます。
Java OrderService: HashMap を ConcurrentHashMap に変更し、ExecutorService の shutdown 漏れを指摘します。
Python Client Lifecycle: 長寿命 async クライアント向けに明示的なシャットダウンフックを追加します。
C++ FileAccessEncrypted: 暗号化ファイルがすべてブロックされる検証バグを修正し、上流のエラーハンドリングも改善します。
どれも一行修正ではなく、システム全体の整合性を高める提案です。コードを「問題の集合体」ではなく「相互に影響し合うエコシステム」とみなしていることがわかります。
Anthropic の Effort パラメータを使うと、モデルの推論深度を直接制御できます。High-effort では依存関係パスを徹底的に探索し、Medium-effort ではトークン節約のため深度を抑えます。High-effort であっても、Opus 4.5 の出力トークン量は Sonnet 4.5 より約25%少なく、1M 出力トークン 25ドルという単価を効率性で補っています。
規律ある構造のおかげで脱線が減り、クリアで読みやすい結果を維持できています。

Sonnet 4.5 が教師、GPT-5.1 が決断力のあるチームメイトだとしたら、Opus 4.5 は PR をレビューしに戻ってきたアーキテクト です。トーンは落ち着いており、命令的ではありません。あなたがドメインを理解している前提で、細部を丁寧に確認します。そのため、システムエンジニアによるピアレビューのような、構造的で静かに権威を感じさせるコメントになります。
Opus 4.5 のトーンは測定可能で分析的です。劇的な表現や不必要な厳しさを避け、秩序ある構造、簡潔な要約、根拠の提示、フォーカスされた修正提案によって確信を示します。システムに精通したメンターからのアドバイスのように感じられるため、開発者が受け取りやすい雰囲気です。
コメントはコンパクトですが情報量は十分です。複雑な問題には必要なだけの説明を行い、単純な問題は短い提案で正確に処理します。このバランスによって、読みやすさと包括性が両立しています。
文脈 → 原因 → 修正というリズムにより、開発者はコメントをすばやくスキャンしつつ意味を保持できます。Opus 4.5 のコメントは「構造化されたスナップショット」のようで、何が起きたのか、なぜ重要なのか、どう直すのかが一目で分かります。
Opus 4.5 は誇張や劇的な表現を避けるため、開発者からの信頼を得やすいモデルです。プロフェッショナルで落ち着いたトーンを維持し、間違っている場合も過剰な断定ではなく理性的な仮説として提示します。過度な自信がないため、レビューがより「人間的で実務的」に感じられます。
コメントはまるで設計ノートのように読みやすく、壊れた不変条件、修正案、その根拠が明確に記されています。そのまま変更履歴や Issue Tracker に貼れるレベルの明快さです。
長所:
重要コメントの密度が高い(約80%)
言語をまたいだ構造の一貫性
並行処理やライフサイクルに強い推論能力
明確・簡潔・プロフェッショナルなトーン
Sonnet 4.5 より冗長でない一方、GPT-5.1 より文脈が豊富
短所:
精度は中程度(約38%)
間違っているときに少し断定的になることがある
重大ラベルが多く、多忙な PR では過剰に見える場合がある
単純な問題ではやや説明が長くなることがある
結論:
Opus 4.5 は、私たちがテストした中で最も システミック(全体的) なレビュアーです。落ち着きがあり、構造化され、厳密で、アーキテクチャ理解が必要な場面で特に強みを発揮します。
| シナリオ | 最適モデル | 理由 |
| 複数言語や高度な文脈を含むレビュー | Opus 4.5 | 構造が安定しており、システム的な洞察が強い |
| 精密さ重視の小規模 diff | GPT-5.1 | 精度が高く、判断も明確で、誤検知が少ない |
| 大量スキャンやコスト重視 | Sonnet 4.5 | カバレッジが高く、レビュー単価が低い |
Opus 4.5 は、実験的なモデルではなく「設計されたモデル」に感じられます。初期のモデルが推測に頼りがちだったのに対し、Opus 4.5 は測定し、構造化し、文書化します。レビューを読むと、開発者の視点 を理解したモデルと一緒に作業しているように感じられます。
コードレビューでは、トーンが信頼を決めます。Opus 4.5 のスタイル──測定可能で、構造化され、機械的な精度を持つ──は、推論の成熟を示しています。圧力のない精度、エゴのない自信が感じられます。
まとめ:
Sonnet 4.5 が教師、GPT-5.1 がチームメイトだとすると、Opus 4.5 は設計レビューのために戻ってきたアーキテクトです。
CodeRabbit を試してみたい方はこちら
14日間の無料トライアル



