

Atsushi Nakatsugawa
November 25, 2025
3 min read
November 25, 2025
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
How CodeRabbit's agentic code validation helps with code reviewsの意訳です。
2025年の Stack Overflow 調査では、幾つかの矛盾が明らかになっています。84% の開発者が AI ツールの導入に前向きである一方で、約半数(48%)がその出力の正確性を信頼していないのです。この期待と懐疑の矛盾した関係が、品質保証の考え方そのものを大きく変えています。

ソフトウェア開発のボトルネックは、コードを書く行為から「コードを検証する行為」へとシフトしてきています。
初期のAI駆動開発のワークフローはシンプルでした。AI がコードを提案し、人間が提案されたスニペットを読み、それを採用するかどうかを判断する。タブ補完でボイラープレートが書かれ、Copilot が関数を提案する。しかし、プルリクエストを作る前には、シニアエンジニアがその品質・構造・安全性を担保するべく、行単位で人力による検証を行っていました。
しかし現在は状況が異なります。OpenAI の o1 のような高度な推論モデルは複雑な要件を分解し、もはや「機能単位」のコードを生成可能です。これによってエージェントが能動的に大規模なコードを生成する “エージェントコード世代” の時代が始まりました。AI が1行ずつコードを提案するフェーズとは異なり、機能全体を生成する今の枠組みでは、品質や構造、安全性の問題を見落としやすくなります。
そして、AI が生成したコードのレビューは、これまでとは違って圧倒的に時間がかかります。ボトルネックは「コードを書くこと」ではなく、「そのコードを信頼できるかどうか」なのです。

エンジニアが懐疑的になるのも無理はありません。AIが生成するコードの40%以上に依然としてセキュリティ欠陥が含まれることがわかっているからです。AI生成コードがよく間違えるポイントを挙げます。
依存関係の爆発:
例えば「ToDo アプリを作る」と簡単に指示しただけで、モデルによっては 2〜5 個のバックエンド依存が追加されることがあります。依存が増えるほど攻撃対象領域が広がります。さらに、古いデータで訓練されたモデルは既知の CVE があるライブラリを提案することもあります。
幻の依存関係:
AI が存在しないパッケージ名を捏造し、攻撃者がその名前を悪意あるコードで公開リポジトリに登録し、開発者が盲目的にインストールしてしまうケースがあります。これは “スロップスクワッティング攻撃” と呼ばれる、AI 生成コード特有の攻撃手法です。
アーキテクチャのドリフト:
暗号ライブラリを勝手に置き換えたり、アクセス制御チェックを削除したり、セキュリティ前提を変えてしまうことがあります。表面上は正しそうに見えても挙動が不正で、静的解析では検出されず、本番で初めて発覚する類の問題です。
数年前、AI をコードレビューのような協調ワークフローに適用しようとすると、どこか「実験」のように扱われていました。セミコロンの欠落や未使用変数を指摘する程度で、せいぜいNullポインタの可能性を警告するくらい。速くて安価だが浅い、そんな時代でした。
CodeRabbit では、生成AIを導入し始めた初期段階でこの問題を早期に認識し、“monologue(モノローグ)” という技術を開発しました。これは、モデル自身が問題を思考し、その理由をコメント内で語る仕組みです。
OpenAI の o1 や o3 のような推論モデルの登場により、CodeRabbit の monologue 機能によって、モデルが問題を本当に思考するようになりました。GPT-4o にレビューさせると、過去のパターンをマッチングするだけで、レビューコメントの多くは表面的な指摘に留まります。一方、GPT-5 や Claude Sonnet 4.5 はコードのロジックを深く追跡し、実行パスを考慮し、エッジケースに向き合い、意図を理解します。
これはレビューの質にとって重要ですが、同時に大きな課題も生んでいます。
多くの人が、推論モデルを使えば AI が自ら生成したコードの品質問題やバグを自動的に検出できると思っていました。しかし、それは完全には正しくありませんでした。欠けていた大きな要素は以下の2つです。
効果的なコンテキストアセンブリ(context engineering)
結果の真正性の検証(verification)
従来のコード検証ツールはリアクティブです。
linter は未使用変数を、静的解析はNullポインタを、セキュリティスキャナはハードコードされた秘密情報を指摘します。それぞれが孤立して動作し、あなたが何を作ろうとしているのかという文脈は理解しません。
生成AI時代には、これらのツールをレビューに統合するケースも増えました。しかし、モデルもツールも、それらを取捨選択してノイズを除去し、重要なシグナルだけを浮かび上がらせるほど賢くはありません。その結果、コンテキストが詰まり(context clogging)、レビューが逆に難しくなります。
これに対処するため、CodeRabbit は各モデルに与えるコンテキストを構築し、管理する技術を発展させました。例えば:
ツールが検出した重要な問題をリスト化し、推論モデルがより合理的に改善案を導けるように指示的(instructive)な形で渡す
さらに、レビュー結果をチェックし根拠付ける verification agent を追加
以下は OSS PR からの具体例です。
静的解析:ast-grep のようなツールによる AST 解析で怪しいコードを検出
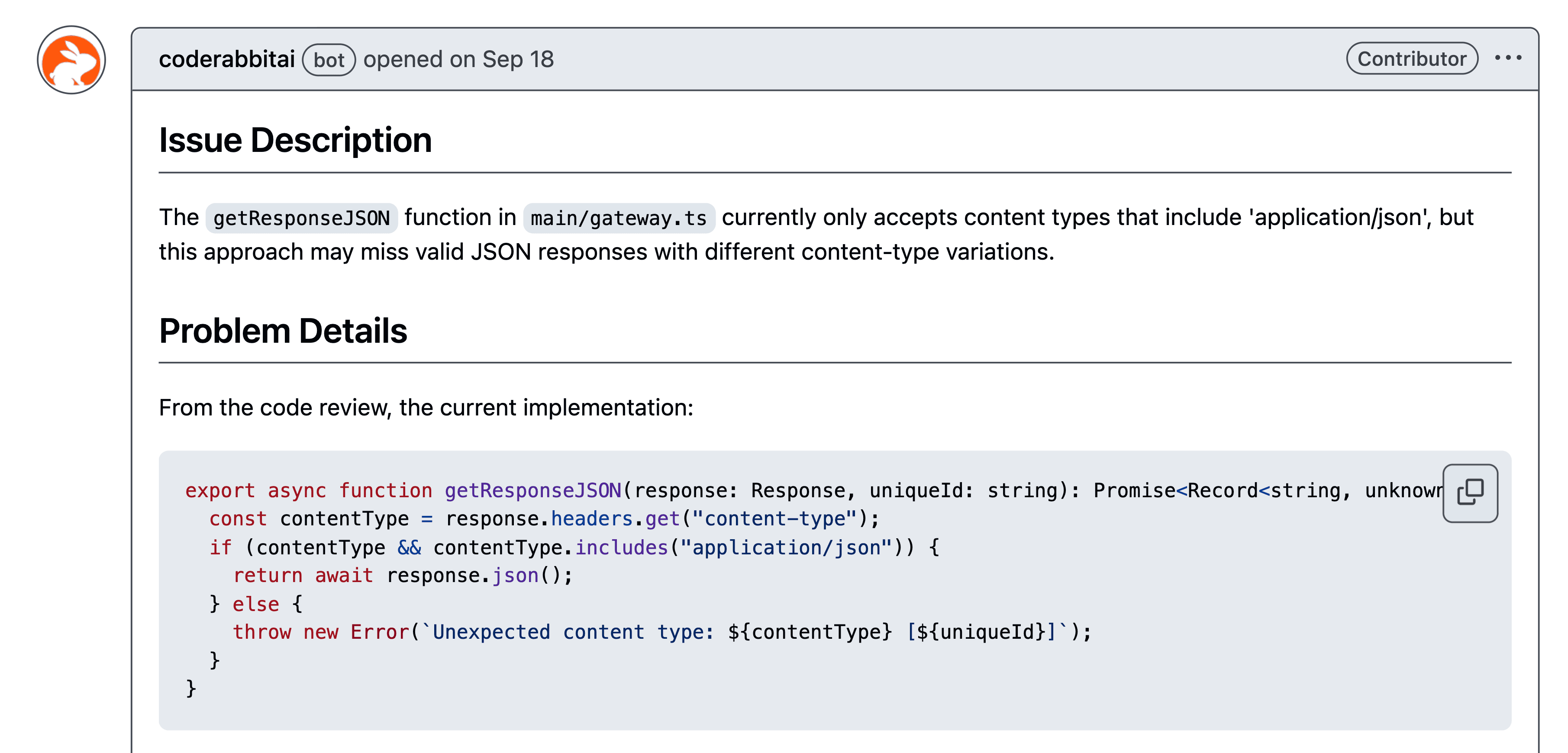

インクリメンタル解析:コードベース全体ではなく「変更部分だけ」を検証


セキュリティ課題:プロンプトインジェクションやエッジケース生成
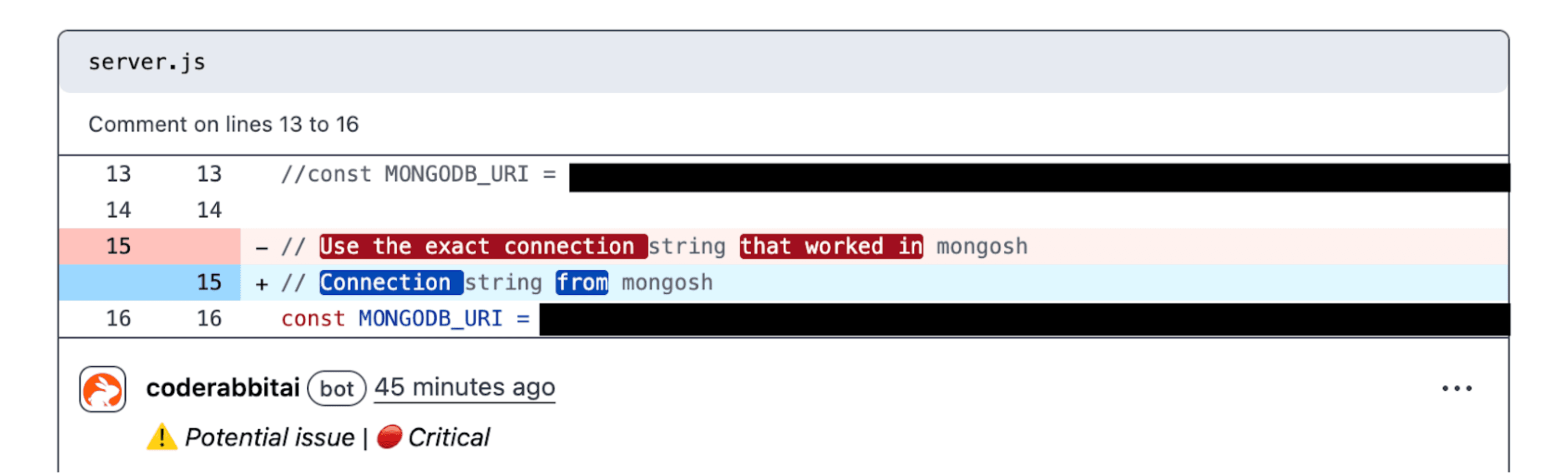
名前のリファクタリング:実際の使用箇所にもとづく変数・関数名の改善提案
ここでいう “agentic” とは、AI がどのツールを使うべきか判断し、結果を解釈し、必要なアクションを自律的に行うという意味です。つまり、状況に応じて深掘るべき点と、特に問題ない点を見極める「シニアエンジニアの判断力」に近づける試みです。
CodeRabbit はベンチマークスコアの向上や従来の指標に依存するのではなく、実際のエンジニアリング現場での動作に基づいて AI の性能を評価するために独自の評価手法を採用しています。その多くは、レビュー対象の PR 上で直接確認できるものです。
エージェンティックコード検証は CodeRabbit がレビューする すべてのプルリクエストで実行されます。ただし、すべては CodeRabbit が「tools in jail」と呼ぶ、 隔離されたサンドボックス環境で動作します。Security Posture で説明されているように、このアプローチにより、検証エージェントはユーザーデータやインフラストラクチャの整合性を損なうことなく、安全にコードの実行・検査・ストレステストができます。
エージェントは一般的な脆弱性の検出、大規模コードのパターン解析、包括的なテスト実行に優れています。人間が手動で行うと時間がかかり過ぎる問題を、特に得意としています。ただしエージェンティックコード検証がコードレビューを完全に置き換えるわけではありません。むしろ、エンジニアが本来集中すべき領域――アーキテクチャの判断、ビジネスロジックの妥当性検証、セキュリティの微妙なニュアンス――に時間を割けるようにするものです。
人間とエージェントが両方レビューに関わることで、ペアプログラミングに近い「冗長性」と「補完的な推論能力」を提供できます。
エージェンティック検証を実際に体験しませんか?
CodeRabbit の14日間トライアルに登録する



