

Atsushi Nakatsugawa
September 30, 2025
3 min read
September 30, 2025
3 min read
Share
Cut code review time & bugs by 50%
Most installed AI app on GitHub and GitLab
Free 14-day trial
GPT-5 Codex: How it solves for GPT-5's drawbacksの意訳です。
CodeRabbitのコードレビューは、開発者がバグを修正しコードをデリバリーするのを支援します。私たちは最近、GPT-5のベンチマークについて記事を書き、AIコードレビューという私たちのユースケースにおいて、このモデルが推論面で世代的な飛躍を遂げているという見解を述べました。より広いユーザーベースに展開する中で、S/N値(シグナル/ノイズ値。以下SNR)が低下し、レビューが過度に細かすぎるという印象を持たれることが分かりました。
GPT-5 Codexのリリースと、私たちが実施した製品変更(重大度タグ付け、より厳格なリファクタ提案のゲーティング、フィルタリング改善)により、難しいバグを見つける能力を犠牲にすることなく、SNRを取り戻すことができました。
刷新した「Hard 25」PRセットにおいて、GPT-5 CodexはGPT-5と比べてコメントあたりの精度が約35%向上し、エラーパターンレベルの不具合カバレッジは本質的に同等のまま、コメント量を約3分の1削減しました。さらにGPT-5 Codexモデルの低レイテンシと組み合わせることで、体感はより軽快、かつフォーカスされたものになります。
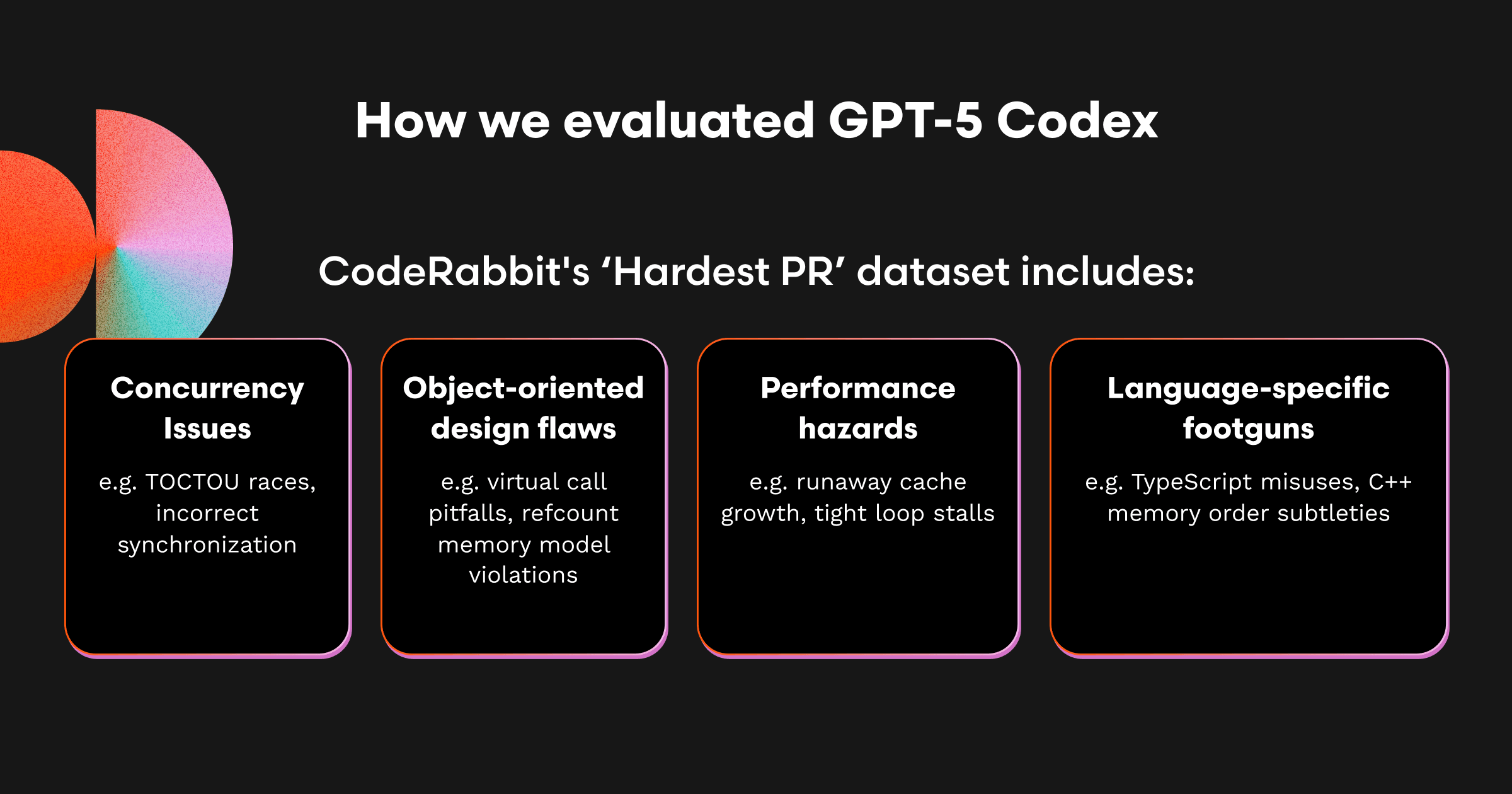
GPT-5 Codexのテストでは、OSSのPRからなる新しい「Hard 25」スイート(以前の記事よりやや難度高め)を実行しました。これは私たちのデータセットに含まれる中でも特に難しい25本のプルリクエストです。現実世界のバグを表したもので、対象は以下の通りです。
並行性の問題(例: TOCTOUレース、誤った同期化)
オブジェクト指向設計の欠陥(例: 仮想呼び出しの落とし穴、参照カウントメモリモデルの破綻)
パフォーマンス上の危険(例: 無制御なキャッシュ成長、タイトループによるスタール)
言語特有の落とし穴(例: TypeScriptの誤用、C++のメモリ順序の微妙さ)
評価したモデルは以下の通りです。
GPT-5 Codex
GPT-5
Claude(Sonnet 4 および Opus-4.1)
各モデルには、以下の観点でスコアを与えました:
EP(Error Pattern / エラーパターン)
PRに潜む特定の根本欠陥(例: 条件変数でのlost wakeup、ロック順序の不整合、ブール条件が錯綜する中に隠れたロジックバグ)。
EP PASS/FAIL(PR単位)
そのPRのEPを直接修正、または信頼できる形で表面化させるコメントを少なくとも1つ残せばPASS。コメントがゼロならそのPRはFAIL。
コメントPASS/FAIL(コメント単位)
EPを直接修正、または信頼できる形で表面化させればPASS、そうでなければFAIL。
コメントあたり精度(Per comment precision)
PASSコメント ÷ 全コメント。今回のデータセットにおける実務上のSNR。
Important share(重要コメント比率)
すべてのPASSはImportant扱い。EPを解決しないが、重大なバグ(use-after-free、二重解放、lost wakeup、メモリリーク、null参照、パストラバーサル、破滅的な正規表現など)を正しく指摘するコメントもImportant。それ以外はMinor。
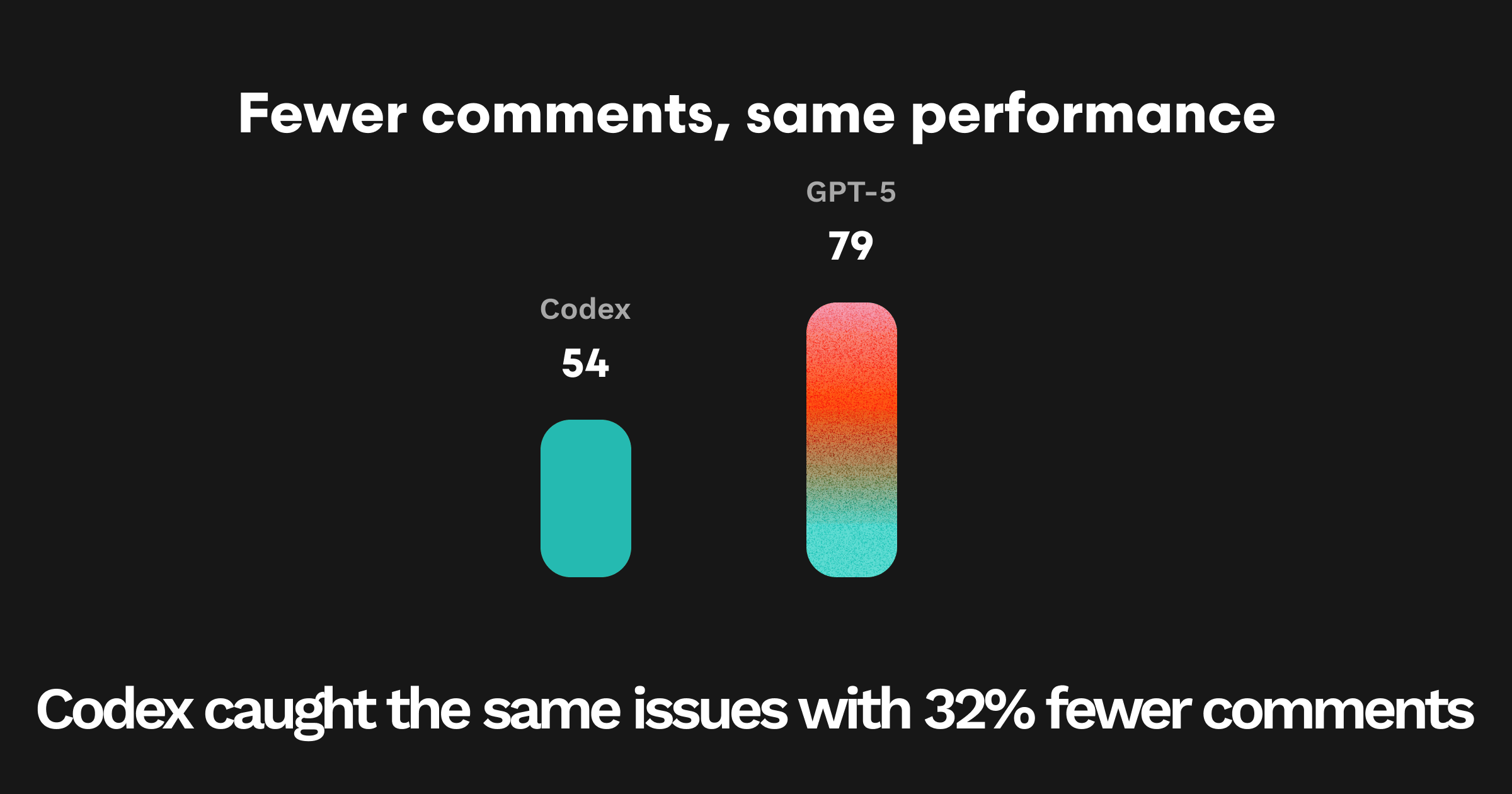
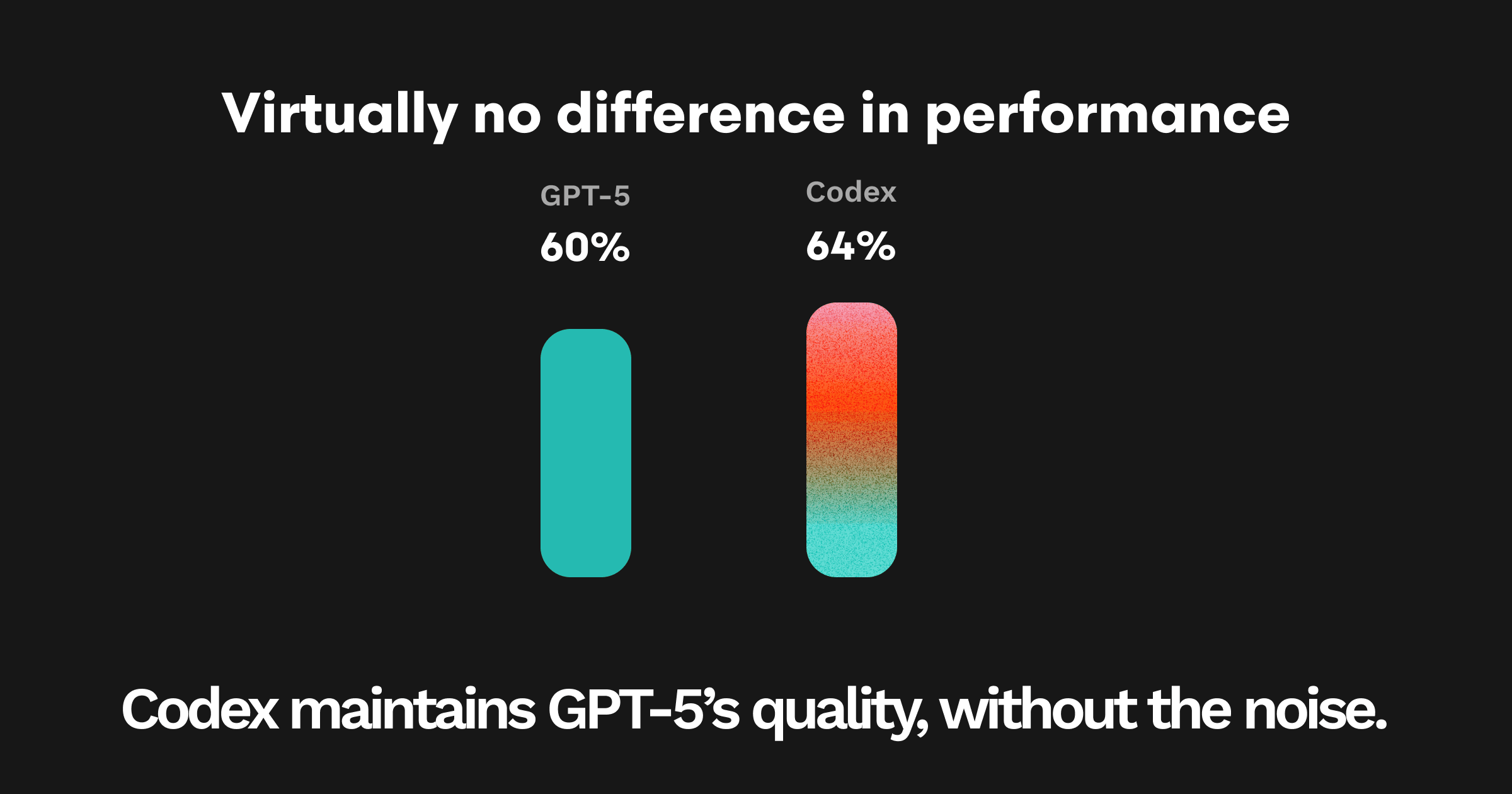
要点: Codexは、GPT-5とほぼ同じEPを見つけつつ、より少ない・締まったコメントで行うため、SNRが向上します。
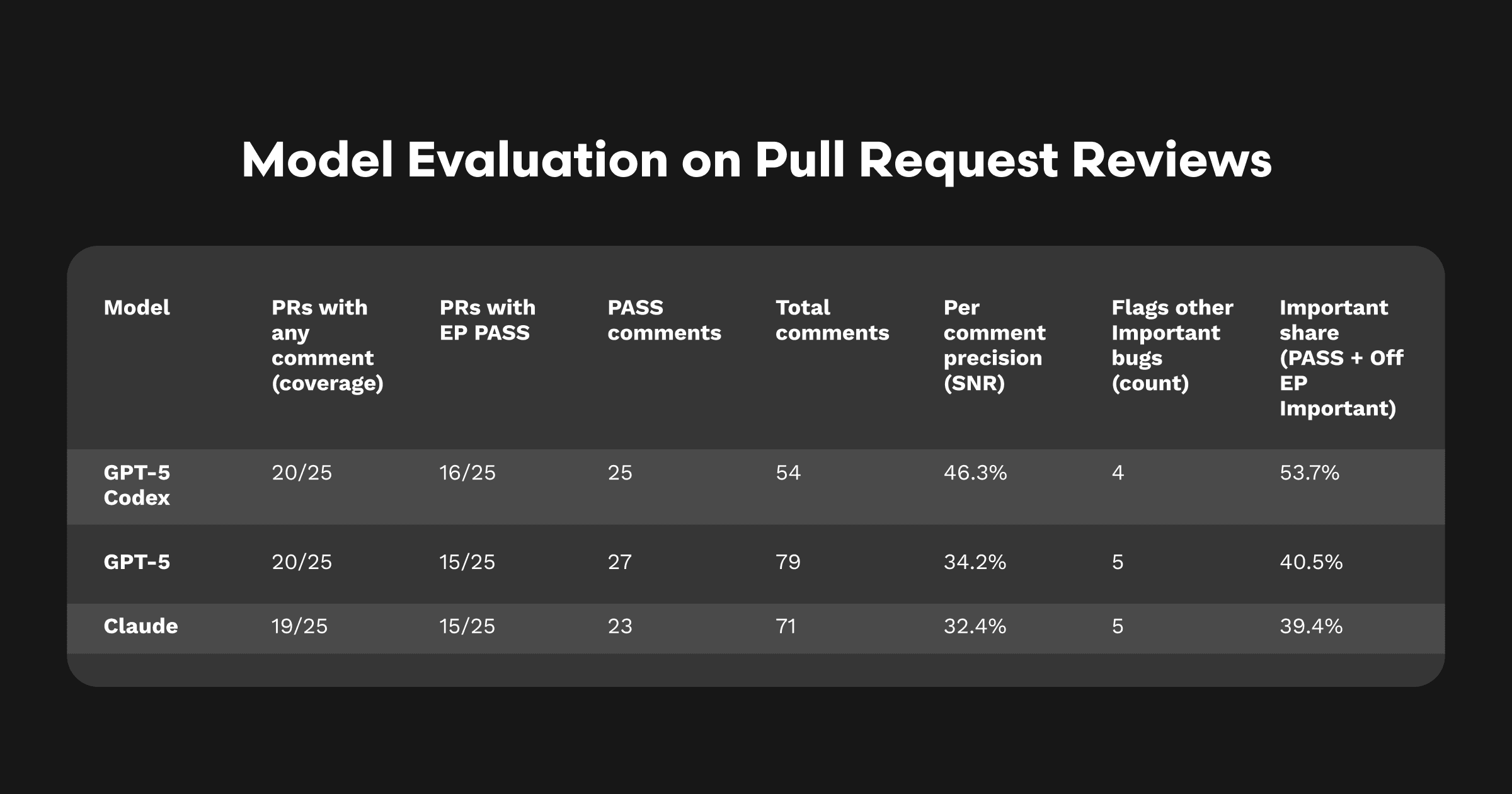
意味するところ: Codexは25本中20本のPRをカバー(残り5本は未カバーのFAIL)。総コメント数は少ないにもかかわらず、EPのPASS数はやや上回り(16 対 15)、重要(Important)コメントは大幅に増加。コメントの半分以上が、そのPRで想定していた問題へのダイレクト、または別の重大バグの指摘でした。GPT-5とClaudeは精度・重要比率ともに約40%で、後塵を拝しました。
結論: 同等のEPカバレッジで、ノイズは減少
CodexはGPT-5のバグ発見力を維持したまま、コメント量を約32%削減(54 対 79)し、コメントあたり精度を約35%向上(46.3% 対 34.2%)。ClaudeはカバレッジはGPT-5に近いものの、より冗長で精度は低めでした。
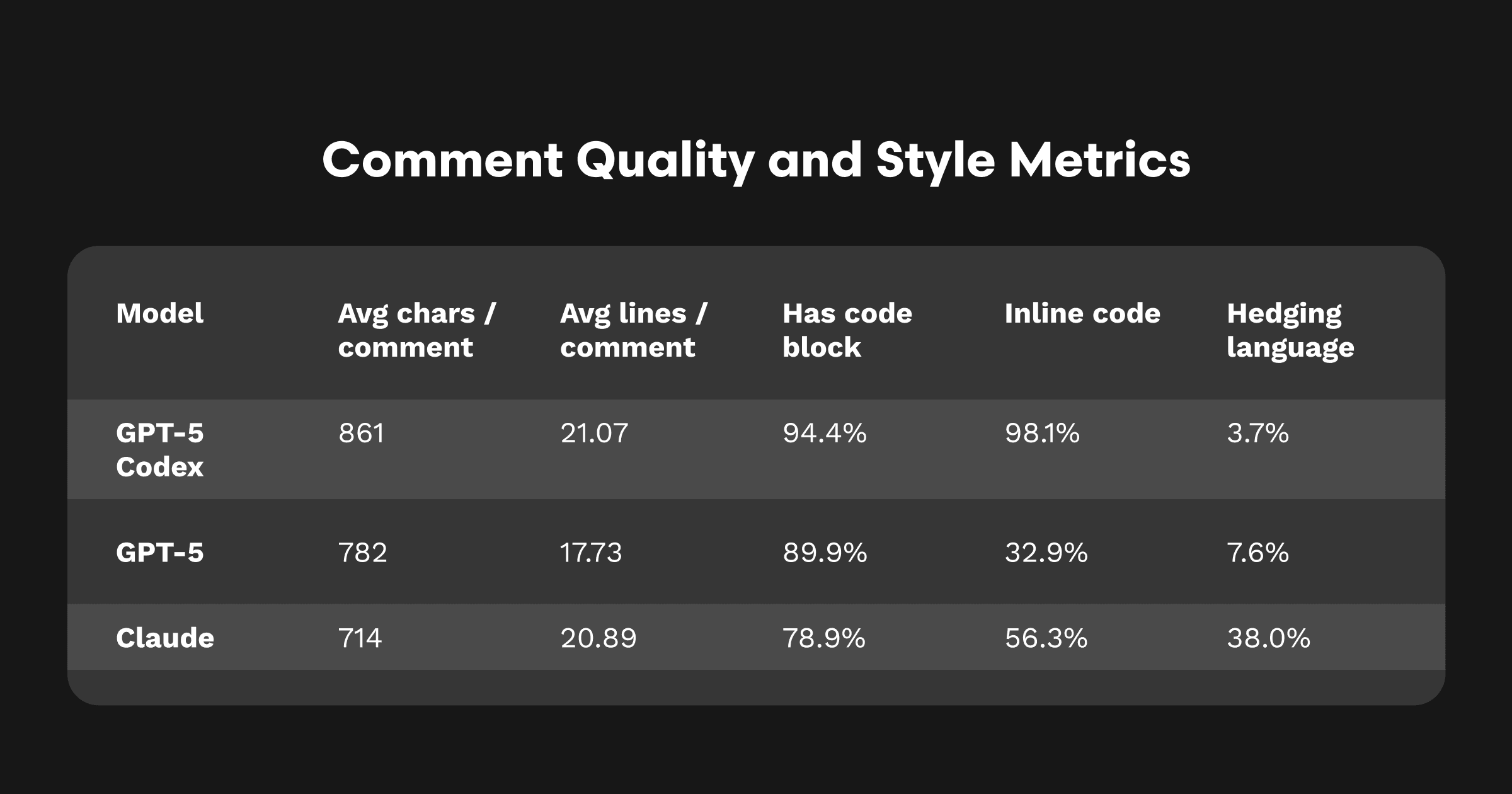
Codexの返信は一貫してアクション優先(ほぼ常にdiff付き)で、曖昧表現が少ない。これは「すぐパッチに反映できる提案」を望むレビュアーの期待に合致します。

スイート全体では、どのモデルも並行性・同期の問題に強みを見せましたが、Codexは特に以下で際立ちました。
条件変数の誤用とlost wakeup
ロック下でのwait、ループ内での述語チェックといった標準パターンを提案し、具体的なdiffを提示。
ロック順序とデッドロック
取得順の不整合を指摘し、ロック階層の導入やクリティカルセクション外への処理移動を提案(いずれも実行可能な編集付き)。
APIやパフォーマンスの微妙な罠
破滅的な正規表現のバックトラッキングやメモリモデルの順序問題などを的確に特定し、パッチを提示。

観測: SonnetやOpusからGPT-5に移行した際、レビューあたりの総コメント数はほぼ倍増しました。一方でハルシネーションは1%未満、ネガティブトーンも1%未満まで低下したにもかかわらず、受け入れ率(有益と判断されたコメントの比率)は、GPT-5導入前のベースラインに比べて大きく低下しました。
Codexでの変化: GPT-5 Codexと私たちの製品変更の併用により、受け入れ率は以前の水準まで回復。一方で総コメント量は「GPT-5導入前」より依然多いままです。要するに、「有益さ」は取り戻しつつ、GPT-5並みに実問題を見つけ続けられるようになりました。
この改善には2つの製品変更が寄与しました。
重大度とレビュータイプのタグを前面に
レビュータイプ: ユーザーが読みたいコメントの種類を自己選択できるよう、⚠️ Potential issue、🛠️ Refactor suggestion、🧹 Nitpick(Assertiveモードにしない限り非表示)を用意。
重大度: コメントに重大度タグを付け、優先度を明確化。タグは🔴 Critical、🟠 Major、🟡 Minor、🔵 Trivial、⚪ Info。
バグ(Critical/Major/Minor)は常に表示。その他は常にではありません。リファクタはモデルが「本質的」と判定した場合のみ表示。すべて見たいユーザーはAssertiveに切替可能。
より厳格なフィルタリングと集約
5分のレビューは許容範囲ですが、30分は許容できません。GPT-5の「常に深く考える」スタイルは、ファーストトークンまでの時間と全体のレビュー時間を大幅に増やしました。私たちは最近いくつかのパイプライン最適化を行い、さらにCodexがGPT-5由来のレイテンシを低減できるようになりました。
Codexの可変(弾力的)な思考は、不要な場面では深掘りを減らし、実運用でTTFT(最初の出力までの時間)とE2Eレビュー時間を短縮しています。総じて、レビューは速くなり、フィードバックは早く、ヒューマン・イン・ザ・ループの流れが改善されます。
Codex導入後、AIコードレビューはどう変わるでしょうか?
生のバグ検出力は同等
コメントは少なく、しかし強く
重大度タグでレビューに集中
フィードバックループの高速化
以下は興味深かった追加統計を紹介します。
コメントあたり精度(SNR)の向上: Codex 46.3% 対 GPT-5 34.2% — 相対で約+35%。
コメント量の差: Codex 54 対 GPT-5 79 — 約32%減、EPのPASSは実質同等(16 対 15)。
スタイル: Codexは94%のコメントでdiffを含み、このセットではClaudeやGPT-5より曖昧表現が少ない。
実環境での受け入れ: GPT-5ロールアウト中は受け入れ率が大きく低下。Codexと製品変更の併用で約20–25%相対上昇し、導入前水準に回復。かつ、GPT-5導入前より受け入れコメント数は多いまま。
改善は大きいものの、課題が残っていないわけではありません。現在、以下に取り組んでいます。
カバレッジの穴
モデルがPRにコメントを残さない場合、そのEPはハードFAIL。Codexの探索ヒューリスティクスを広げ、特定クラスの問題を見落としにくくします。
リファクタ過剰提案(調整済みだが未完)
「本質的なもののみ」のゲートでノイズは抑制しましたが、特に大規模diffでコメント過多になりがちなケースの閾値をさらに引き締めます。
ユーザー主導の優先度付け
GitHubのインライン順序は変更できませんが、各コメントに重大度を注記し、上から順にトリアージしやすくします。
私たちの指標はシンプルです: 重要なバグを、素早く、ノイズに埋もれさせずに捕まえること。Codexはその実現を助けてくれます。GPT-5の噛み応えある推論力を保ちながら、SNRを回復させ、レイテンシを大幅に削りました。今後も測定・改善を継続し、より良い製品をリリースし続けます。



